Download

1 / 49
530 likes | 1.48k Views
CPU Scheduling. CPU Scheduler Performance metrics for CPU scheduling Methods for analyzing schedulers CPU scheduling algorithms Case study: CPU scheduling in Solaris, Window XP, and Linux. CPU Scheduler .

E N D
CPU Scheduling CPU Scheduler Performance metrics for CPU scheduling Methods for analyzing schedulers CPU scheduling algorithms Case study: CPU scheduling in Solaris, Window XP, and Linux.
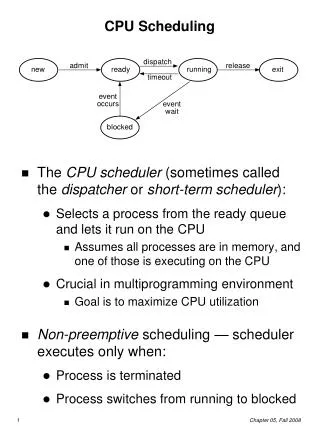
CPU Scheduler • A CPU scheduler, running in the dispatcher,is responsible for selecting of the next running process. • Based on a particular strategy • When does CPU scheduling happen? • Four cases: • A process switches from the running state to waiting state (e.g. I/O request) • A process switches from the running state to the ready state. • A process switches from waiting state to ready state (completion of an I/O operation) • A process terminates
Scheduling queues • CPU schedulers use various queues in the scheduling process: • Job queue: consists of all processes • All jobs (processes), once submitted, are in the job queue. • Some processes cannot be executed (e.g. not in memory). • Ready queue • All processes that are ready and waiting for execution are in the ready queue. • Usually, a long-term scheduler/job scheduler selects processes from the job queue to the ready queue. • CPU scheduler/short-term scheduler selects a process from the ready queue for execution. • Simple systems may not have a long-term job scheduler
Scheduling queues • Device queue • When a process is blocked in an I/O operation, it is usually put in a device queue (waiting for the device). • When the I/O operation is completed, the process is moved from the device queue to the ready queue.
An example scheduling queue structure • Figure 3.6
Queueing diagram representation of process scheduling • Figure 3.7
Performance metrics for CPU scheduling • CPU utilization: percentage of the time that CPU is busy. • Throughput: the number of processes completed per unit time • Turnaround time: the interval from the time of submission of a process to the time of completion. • Wait time: the sum of the periods spent waiting in the ready queue • Response time: the time of submission to the time the first response is produced
Goal of CPU scheduling Other performance metrics: • fairness: It is important, but harder to define quantitatively. • Goal: • Maximize CPU utilization, Throughput, and fairness. • Minimize turnaround time, waiting time, and response time.
Which metric is used more? • CPU utilization • Trivial in a single CPU system • Fairness • Tricky, even definition is non-trivial • Throughput, turnaround time, wait time, and response time • Can usually be computed for a given scenario. • They may not be more important than fairness, but they are more tractable than fairness.
Methods for evaluating CPU scheduling algorithms • Simulation: • Get the workload from a system • Simulate the scheduling algorithm • Compute the performance metrics based on simulation results • This is practically the best evaluation method. • Queueing models: • Analytically model the queue behavior (under some assumptions). • A lot of math, but may not be very accurate because of unrealistic assumptions.
Methods for evaluating CPU scheduling algorithms • Deterministic Modeling • Take a predetermined workload • Run the scheduling algorithm manually • Find out the value of the performance metric that you care about. • Not the best for practical uses, but can give a lot of insides about the scheduling algorithm. • Help understand the scheduling algorithm, as well as it strengths and weaknesses
turnaround time wait time + + Deterministic modeling example: • Suppose we have processes A, B, and C, submitted at time 0 • We want to know the response time, waiting time, and turnaround time of process A response time = 0 A B C A B C A C A C Time Gantt chart: visualize how processes execute.
turnaround time wait time + response time Deterministic modeling example • Suppose we have processes A, B, and C, submitted at time 0 • We want to know the response time, waiting time, and turnaround time of process B A B C A B C A C A C Time
response time wait time + + + turnaround time Deterministic modeling example • Suppose we have processes A, B, and C, submitted at time 0 • We want to know the response time, waiting time, and turnaround time of process C A B C A B C A C A C Time
Preemptive versus nonpreemptive scheduling • Many CPU scheduling algorithms have both preemptive and nonpreemptive versions: • Preemptive: schedule a new process even when the current process does not intend to give up the CPU • Non-preemptive: only schedule a new process when the current one does not want CPU any more. • When do we perform non-preemptive scheduling? • A process switches from the running state to waiting state (e.g. I/O request) • A process switches from the running state to the ready state. • A process switches from waiting state to ready state (completion of an I/O operation) • A process terminates
Scheduling Policies • FIFO (first in, first out) • Round robin • SJF (shortest job first) • Priority Scheduling • Multilevel feedback queues • Lottery scheduling • This is obviously an incomplete list
FIFO • FIFO: assigns the CPU based on the order of requests • Nonpreemptive: A process keeps running on a CPU until it is blocked or terminated • Also known as FCFS (first come, first serve) + Simple • Short jobs can get stuck behind long jobs • Turnaround time is not ideal (get an example from the class)
Round Robin • Round Robin (RR) periodically releases the CPU from long-running jobs • Based on timer interrupts so short jobs can get a fair share of CPU time • Preemptive: a process can be forced to leave its running state and replaced by another running process • Time slice: interval between timer interrupts
More on Round Robin • If time slice is too long • Scheduling degrades to FIFO • If time slice is too short • Throughput suffers • Context switching cost dominates
FIFO vs. Round Robin • With zero-cost context switch, is RR always better than FIFO?
turnaround time of C turnaround time of B turnaround time of C turnaround time of B turnaround time of A turnaround time of A A B C A B C A B C Time FIFO vs. Round Robin • Suppose we have three jobs of equal length Round Robin A B C Time FIFO
FIFO vs. Round Robin • Round Robin + Shorter response time + Fair sharing of CPU - Not all jobs are preemptable • Not good for jobs of the same length • More precisely, not good in terms of the turnaround time.
Shortest Job First (SJF) • SJF runs whatever job puts the least demand on the CPU, also known as STCF (shortest time to completion first) + Provably optimal in terms of turn-around time (anyone can give an informal proof?). + Great for short jobs + Small degradation for long jobs • Real life example: supermarket express checkouts
turnaround time of C turnaround time of B turnaround time of A wait time of C wait time of B wait time of A = 0 response time of C response time of B response time of A = 0 SJF Illustrated A B C Time Shortest Job First
Shortest Remaining Time First (SRTF) • SRTF: a preemptive version of SJF • If a job arrives with a shorter time to completion, SRTF preempts the CPU for the new job • Also known as SRTCF (shortest remaining time to completion first) • Generally used as the base case for comparisons
SJF and SRTF vs. FIFO and Round Robin • If all jobs are the same length, SJF FIFO • FIFO is the best you can do • If jobs have varying length • Short jobs do not get stuck behind long jobs under SRTF
Drawbacks of Shortest Job First - Starvation: constant arrivals of short jobs can keep long ones from running - There is no way to know the completion time of jobs (most of the time) • Some solutions • Ask the user, who may not know any better • If a user cheats, the job is killed
C A B Time Priority Scheduling Priority Scheduling (Multilevel Queues) • Priority scheduling: The process with the highest priority runs first • Priority 0: • Priority 1: • Priority 2: • Assume that low numbers represent high priority C A B
Priority Scheduling + Generalization of SJF • With SJF, priority = 1/requested_CPU_time - Starvation
Multilevel Feedback Queues • Multilevel feedback queues use multiple queues with different priorities • Round robin at each priority level • Run highest priority jobs first • Once those finish, run next highest priority, etc • Jobs start in the highest priority queue • If time slice expires, drop the job by one level • If time slice does not expire, push the job up by one level
Multilevel Feedback Queues time = 0 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A B C Time
Multilevel Feedback Queues time = 1 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): B C A A Time
Multilevel Feedback Queues time = 2 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): C A B A B Time
Multilevel Feedback Queues time = 3 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A B C A B C Time
Multilevel Feedback Queues time = 3 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A B C suppose process A is blocked on an I/O A B C Time
Multilevel Feedback Queues time = 3 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A B C suppose process A is blocked on an I/O A B C Time
Multilevel Feedback Queues time = 5 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A C suppose process A is returned from an I/O A B C B Time
Multilevel Feedback Queues time = 6 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): C A B C B A Time
Multilevel Feedback Queues time = 8 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): C A B C B A C Time
Multilevel Feedback Queues time = 9 • Priority 0 (time slice = 1): • Priority 1 (time slice = 2): • Priority 2 (time slice = 4): A B C B A C C Time
Multilevel Feedback Queues • Approximates SRTF • A CPU-bound job drops like a rock • I/O-bound jobs stay near the top • Still unfair for long running jobs • Counter-measure: Aging • Increase the priority of long running jobs if they are not serviced for a period of time • Tricky to tune aging
Lottery Scheduling • Lottery scheduling is an adaptive scheduling approach to address the fairness problem • Each process owns some tickets • On each time slice, a ticket is randomly picked • On average, the allocated CPU time is proportional to the number of tickets given to each job
Lottery Scheduling • To approximate SJF, short jobs get more tickets • To avoid starvation, each job gets at least one ticket
Lottery Scheduling Example • short jobs: 10 tickets each • long jobs: 1 ticket each
Case study: • CPU scheduling in Solaris: • Priority-based scheduling • Four classes: real time, system, time sharing, interactive (in order of priority) • Different priorities and algorithm in different classes • Default class: time sharing • Policy in the time sharing class: • Multilevel feedback queue with variable time slices • See the dispatch table
Solaris dispatch table for interactive and time-sharing threads • Good response time for interactive processes and good throughput for CPU-bound processes
Windows XP scheduling • A priority-based, preemptive scheduling • Highest priority thread will always run • Also have multiple classes and priorities within classes • Similar idea for user processes – Multilevel feedback queue • Lower priority when quantum runs out • Increase priority after a wait event • Some twists to improve “user perceived” performance: • Boost priority and quantum for foreground process (the window that is currently selected). • Boost priority more for a wait on keyboard I/O (as compared to disk I/O)
Linux scheduling • A priority-based, preemptive with global round-robin scheduling • Each process have a priority • Processes with a larger priority also have a larger time slices • Before the time slices is used up, processes are scheduled based on priority. • After the time slice of a process is used up, the process must wait until all ready processes to use up their time slice (or be blocked) – a round-robin approach. • No starvation problem. • For a user process, its priority may + or – 5 depending whether the process is I/O- bound or CPU-bound. • Giving I/O bound process higher priority.
Summary for the case study • Basic idea for schedule user processes is the same for all systems: • Lower priority for CPU bound process • Increase priority for I/O bound process • The scheduling in Solaris / Linux is more concerned about fairness. • More popular as the OSes for servers. • The scheduling in Window XP is more concerned about user perceived performance. • More popular as the OS for personal computers.