Download

1 / 17
170 likes | 811 Views
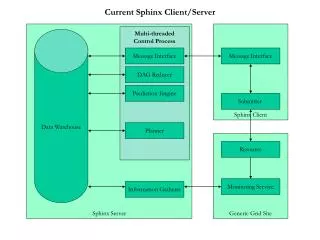
Sphinx-3. An Overview. Installation Overview Sphinx 3. Doc Model Hmm: hub4_cd_continuous Lm Scripts (Unix scripts) Src Libs3audio Libs3decoder Libutil Programs Win32: batch files and workspaces. Overview Sphinx 3.

E N D
Sphinx-3 An Overview
Installation Overview Sphinx 3 • Doc • Model • Hmm: hub4_cd_continuous • Lm • Scripts (Unix scripts) • Src • Libs3audio • Libs3decoder • Libutil • Programs • Win32: batch files and workspaces
Overview Sphinx 3 • The s3.3 decoder is based on the conventional Viterbi search algorithm and beam search heuristics. It uses a lexical-tree search structure somewhat like the Sphinx-II decoder, but with some improvements for greater accuracy than the latter. It takes its input from pre-recorded speech in raw PCM format and writes its recognition results to output files.
Installation Overview Sphinx 3 The decoder needs the following inputs: • Lexical model: The lexical or pronunciation model contains pronunciations for all the words of interest to the decoder. Sphinx-3 uses phonetic units to build word pronunciations. Currently, the pronunciation lexicon is almost entirely hand-crafted. • Acoustic model: Sphinx uses acoustic models based on statistical hidden Markov models (HMMs). The acoustic model is trained from acoustic training data using the Sphinx-3 trainer. The trainer is capable of building acoustic models with a wide range of structures, such as discrete, semi-continuous, or continuous. However, the s3.3 decoder is only capable of handling continuous acoustic models. • Language model (LM): Sphinx-3 uses a conventional backoff bigram or trigram language model.
Installation Overview Sphinx 3 • Speech input specification: This distribution contains four executable files, three of which perform recognition. • livedecode decodes live speech, that is, speech incoming from your audio card. • livepretend decodes in batch mode using a control file that describes the input to be decoded into text. • decode decodes also uses a control file for batch mode processing. In the latter, the entire input to be processed must be available beforehand, i.e., • the raw audio samples must have been preprocessed into cepstrum files. • Also note that the decoder cannot handle arbitrary lengths of speech input. Each separate piece (or utterance) to be processed by the decoder must be no more than 300 sec. long. Typically, one uses a segmenter to chop up a cepstrum stream into manageable segments of up to 20 or 30 sec. duration.
Overview Sphinx 3 • Outputs • The decoder can produce two types of recognition output: • Recognition hypothesis: A single best recognition result (or hypothesis) for each utterance processed. It is a linear word sequence, with additional attributes such as their time segmentation and scores. • Word lattice: A word-graph of all possible candidate words recognized during the decoding of an utterance, including other attributes such as their time segmentation and acoustic likelihood scores. • In addition, the decoder also produces a detailed log to stdout/stderr that can be useful in debugging, gathering statistics, etc.
Sphinx 3 Signal Processing Front End • Input: Speech waveform 16-bits (sampling rate 16kHz) • Input: Front End Processing Parameters • Pre-Emphasis module (pre-emphasis alpha = 0.97) • Framing (100 frames/sec) • Windowing (window length 0.025625 sec) • Power Spectrum (using DFT size 512) • Filtering (lower = 133.334 Hz, upper = 6855.4976 Hz) • Mel Spectrum (multiplying the Power Spectrum with the Mel weighting filters (number of Mel Filters 40)) • Mel Cepstrum (number of cepstra 13) • Mel Frequency Cepstral Coefficients (39 32-bit floats)
Sphinx 3 Acoustic Model An acoustic model is represented by the following collection of files: • A model definition (or mdef) file. • It defines the set of basephone and triphone HMMs • the mapping of each HMM state to a senone, • and the mapping of each HMM to a state transition matrix. • Gaussian mean and variance (or mean and var) files. • These files contain all the Gaussian codebooks in the model. • The Gaussian means and corresponding variance vectors are separated into the two files. • A mixture weights (or mixw) file containing the Gaussian mixture weights for all the senones in the model. • A state transition matrix (or tmat) file containing all the HMM state transition topologies and their transition probabilities in the model. • An optional sub-vector quantized model (or subvq) file containing an approximation of the acoustic model, for efficient evaluation. • The mean, var, mixw, and tmat files are produced by the Sphinx-3 trainer, and their file formats should be documented there.
Sphinx 3 Acoustic Model Continuous Broadcast News Acoustic Models • The models have been trained using 140 hours of 1996 and 1997 hub4 training data, available from the Language Data Consortium. The phoneset for which models have been provided is that of the CMU dictionary version 0.6d. • The dictionary has been used without stress markers, resulting in 40 phones, including the silence phone, SIL. Adding stress markers degrades performance by about 5% relative. • Rita SinghSphinx Speech GroupSchool of Computer ScienceCarnegie Mellon UniversityPittsburgh, PA 15213
Sphinx 3 Acoustic Model Hmm: hub4_cd_continuous files: • 8gau.6000sen.quant • Hub4opensrc.6000.mdef • Means • Mixture_weights • Transition_matrises • variances
Sphinx 3 Language Model • The main language model (LM) used by the Sphinx decoder is a conventional bigram or trigram language model. • The CMU-Cambridge SLM toolkit is capable of generating such a model from LM training data. • Its output is an ascii text file. A • large text LM file can be very slow to load into memory. To speed up this process, the LM must be compiled into a binary form. • The code to convert from an ascii text file to the binary format is available at SourceForge in the CVS tree, in a module named share. • The vocabulary of the LM is the set of words covered by the unigrams.
Sphinx 3 Language Model • In Sphinx, the LM cannot distinguish between different pronunciations of the same word. For example: • even though the lexicon might contain two different pronunciation entries for the word READ (present and past tense forms), the language model cannot distinguish between the two. Both pronunciations would inherit the same probability from the language model. • Secondly, the LM is case-insensitive. For example: • it cannot contain two different tokens READ and read. • The reasons for the above restrictions are historical. Precise pronunciation and case information has rarely been present in LM training data. It would certainly be desirable to do away with the restrictions at some time in the future. (Project)
Sphinx 3 Language Model • In the an4 directory you will see a list of files, of which the following are of special importance: • args.an4.test An argument file, used by the batch file you have executed, specifying all command line arguments for the example executable. • an4.dict The dictionary file for this language model, defining all words in terms of phonemes. • an4.ug.lm The mono-bi-tri-gram data in a readable format used to predict word sequences, this is the actual language 'model'. • an4.ug.lm.DMP The mono-bi-tri-gram data in a binary format used by the toolkit during runtime.
Sphinx 3 Batch Files • Win32: batch files and workspaces
Sphinx3-test.bat set S3ROOT=..\.. cd %S3ROOT% Set S3BATCH=.\win32\msdev\programs\livepretend\Debug\livepretend.exe set TASK=.\model\lm\an4 set CTLFILE=.\win32\batch\an4.ctl (an4.ctl: pittsburgh.littleendian) set ARGS=.\model\lm\an4\args.an4.test echo sphinx3-test echo Run CMU Sphinx-3 in Batch mode to decode an example utterance. echo This batch script assumes all files are relative to the main directory (S3ROOT). echo When running this, look for a line that starts with "FWDVIT:" echo If the installation is correct, this line should read: echo FWDVID: P I T T S B U R G H (null) %S3BATCH% %CTLFILE% %TASK% %ARGS%
Sphinx3-simple.bat rem This batch script assumes all files are relative to the dir (S3ROOT). set S3ROOT=..\.. cd %S3ROOT% set S3CONTINUOUS=.\win32\msdev\programs\livedecode\Debug\ livedecode.exe set ARGS=.\model\lm\an4\args.an4.test echo "sphinx3-simple:" echo "Demo CMU Sphinx-3 decoder called with command line arguments." echo "<executing $S3CONTINUOUS, please wait>" %S3CONTINUOUS% %ARGS% (Change: set ARGS=.\model\lm\dutch_test\args.5417.test)
Sphinx Source Code • agc.cAutomatic gain control (on signal energy), ascr.cSenone acoustic score. • beam.cPruning beam widths ,bio.cBinary file I/O support • cmn.cCepstral mean normalization and variance normalization • corpus.cControl file processing, cont_mgau.cMixture Gaussians (acoustic model) • decode.cMain file for decode • dict.cPronunciation lexicon • dict2pid.cGeneration of triphones for the pronunciation dictionary • feat.cFeature vectors computation • fillpen.cFiller word probabilities • gausubvq.cStandalone acoustic model sub-vector quantizer • hmm.cHMM evaluation • hyp.hRecognition hypotheses data type • kb.hAll knowledge bases, search structures used by decoderkbcore.cCollection of core knowledge baseslextree.cLexical search treelive.cLive decoder functionslm.cTrigram language modellogs3.cSupport for log-likelihood operationsmain_live_example.cMain file for livedecode showing use of live.cmain_live_pretend.cMain file for livepretend showing use of live.cmdef.cAcoustic model definitions3types.hVarious data types, for ease of modificationsubvq.cSub-vector quantized acoustic modeltmat.cHMM transition matrices (topology definition)vector.cVector operations, quantization, etc.vithist.cBackpointer table (Viterbi history)wid.cMapping between LM and lexicon word IDs