Download
1 / 9
100 likes | 749 Views
A systolic array for a 2D-FIR filter for image processing. Sebastian Siegel ECE 734 . Outline. Why Systolic Arrays (SA)? Design Issues Approach Solution Result. Why Systolic Arrays? (1). 4-level nested do-loop:. Why Systolic Arrays? (2).

E N D
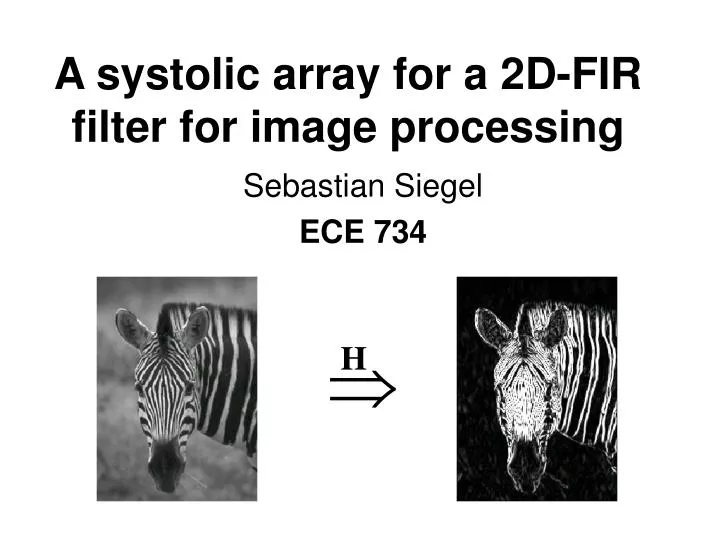
A systolic array for a 2D-FIR filter for image processing Sebastian Siegel ECE 734
Outline • Why Systolic Arrays (SA)? • Design Issues • Approach • Solution • Result
Why Systolic Arrays? (1) • 4-level nested do-loop:
Why Systolic Arrays? (2) • Sequential execution on one MAC requires too much timeExample: image: 512x512, filter: 3x32.3 Million operations @ 10 Mhz = 0.23 s • Algorithm in nested do-loop structure Single Assignment Format possible Parallel execution possible • Systematic approach vs. “rocket science”
Design Issues • Recall: • Avoid multiple access to the same databy pipelining it • Minimize execution time and registers • Maximize Usage of Processing Elements (PEs)
Approach (1) Steps: • Rewrite Algorithm in Single Assignment Format (SAF) • Draw and examine Dep. Graph (DG) • Map DG to SA by generating suitable solutions and chose an optimal oneProblem: SA too big partitioning data reaccessed or cache needed
Approach (2) Partitioning of the DG generates even more (and better) solutions:
Result • Fully pipelined SA • 100% PE utilization • SA can be partitioned with relatively small cache and 100% data reuse or without cache and high data reuse • PEs and their interconnections (# of registers per pipeline) independent of filter size • Low latency for the results • Constant I/O rate • Fast MATLAB® implementation





















