Download

1 / 26
270 likes | 585 Views
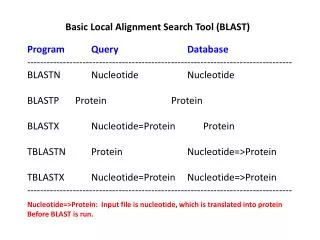
BLAST: Basic Local Alignment Search Tool Altschul et al. J. Mol Bio. 1990. CS 466 Saurabh Sinha. Motivation. Sequence homology to a known protein suggest function of newly sequenced protein Bioinformatics task is to find homologous sequence in a database of sequences

E N D
BLAST:Basic Local Alignment Search ToolAltschul et al. J. Mol Bio. 1990. CS 466 Saurabh Sinha
Motivation • Sequence homology to a known protein suggest function of newly sequenced protein • Bioinformatics task is to find homologous sequence in a database of sequences • Databases of sequences growing fast
Alignment • Natural approach to check if the “query sequence” is homologous to a sequence in the database is to compute alignment score of the two sequences • Alignment score counts gaps (insertions, deletions) and replacements • Minimizing the evolutionary distance
Alignment • Global alignment: optimize the overall similarity of the two sequences • Local alignment: find only relatively conserved subsequences • Local similarity measures preferred for database searches • Distantly related proteins may only share isolated regions of similarity
Alignment • Dynamic programming is the standard approach to sequence alignment • Algorithm is quadratic in length of the two sequences • Not practical for searches against very large database of sequences (e.g., whole genome)
Scoring alignments • Scoring matrix: 4 x 4 matrix (DNA) or 20 x 20 matrix (protein) • Amino acid sequences: “PAM” matrix • Consider amino acid sequence alignment for very closely related proteins, extract replacement frequencies (probabilities), extrapolate to greater evolutionary distances • DNA sequences: match = +5, mismatch = -4
BLAST: the MSP • Given two sequences of same length, the similarity score of their alignment (without gaps) is the sum of similarity values for each pair of aligned residues • Maximal segment pair (MSP): Highest scoring pair of identical length segments from the two sequences • The similarity score of an MSP is called the MSP score • BLAST heuristically aims to find this
Locally maximal segment pair • A molecular biologist may be interested in all conserved regions shared by two proteins, not just their highest scoring pair • A segment pair (segments of identical lengths) is locally maximal if its score cannot be improved by extending or shortening in either direction • BLAST attempts to find all locally maximal segment pairs above some score cutoff.
Rapid approximation of MSP score • Goal is to report those database sequences that have MSP score above some threshold S. • Statistics tells us what is the highest threshold S at which “chance similarities” are likely to appear • Tractability to statistical analysis is one of the attractive features of the MSP score
Rapid approximation of MSP score • BLAST minimizes time spent on database sequences whose similarity with the query has little chance of exceeding this cutoff S. • Main strategy: seek only segment pairs (one from database, one query) that contain a word pair with score >= T • Intuition: If the sequence pair has to score above S, its most well matched word (of some predetermined small length) must score above T • Lower T => Fewer false negatives • Lower T => More pairs to analyze
Implementation • Compile a list of high scoring words • Scan database for hits to this word list • Extend hits
Step 1: Compiling list of words from query sequence • For proteins: List of all w-length words that score at least T when compared to some word in query sequence • Question: Does every word in the query sequence make it to the list? • For DNA: list of all w-length words in the query sequence, often with w=12
Step 2: Scanning the database for hits • Find exact matches to list words • Can be done in linear time • two methods (next slides) • Each word in list points to all occurrences of the word in word list from previous step
Scanning the database for hits • Method 1: Let w=4, so 204 possible words • Each integer in 0 … 204-1 is an index for an array • Array element point to list of all occurrences of that word in query • Not all 204 elements of array are populated • only the ones in word list from previous step
Scanning the database for hits • Method 2: use “deterministic finite automaton” or “finite state machine”. • Similar to the keyword trees seen in course. • Build the finite state machine out of all words in word list from previous step
Step 3: Extending hits • Once a word pair with score >= T has been found, extend it in each direction. • Extend until score >= S is obtained • During extension, score may go up, and then down, and then up again • Terminate if it goes down too much (a certain distance below the best score found for shorter extensions) • One implementation allows gaps during extension
BLAST: approximating the MSP • BLAST may not find all segment pairs above threshold S • Trying to approximate the MSP • Bounds on the error: not hard bounds, but statistical bounds • “Highly likely” to find the MSP
Statistics • Suppose the MSP has been calculated by BLAST (and suppose this is the true MSP) • Suppose this observed MSP scores S. • What are the chances that the MSP score for two unrelated sequences would be >= S? • If the chances are very low, then we can be confident that the two sequences must not have been unrelated
Statistics • Given two random sequences of lengths m and n • Probability that they will produce an MSP score of >= x ?
Statistics • Number of separate SPs with score >= x is Poisson distributed with mean y(x) = Kmn exp(-x), where • is the positive solution of ∑pipjexp(s(i,j)) = 1 • K is a constant • s(i,j) is the scoring matrix, pi is the frequency of i in random sequences
Statistics • Poisson distribution: Pr(x) = (e- x)/x! • Pr(#SPs >= ) = 1 - Pr(#SPs <= -1)
Statistics • For =1, Pr(#SPs >= 1) = 1-e-y(x) • Choose S such that 1-e-y(S) is small • Suppose the probability of having at least 1 SP with score >= S is 0.001. • This seems reasonably small • However, if you test 10000 random sequences, you expect 10 to cross the threshold • Therefore, require “E-value” to be small. • That is, expected number of random sequence pairs with score >= S should be small.
More statistics • We just saw how to choose threshold S • How to choose T ? • BLAST is trying to find segment pairs (SPs) scoring above S • If an SP scores S, what is the probability that it will have a w-word match of score T or more? • We want this probability to be high
More statistics: Choosing T • Given a segment pair (from two random sequences) that scores S, what is the probability q that it will have no w-word match scoring above T? • Want this q to be low • Obtained from simulations • Found to decrease exponentially as S increases