Download

1 / 1
10 likes | 159 Views
Runtime Data Flow Scheduling of Matrix Computations Ernie Chan. Abstract. Algorithm-by-Blocks. Queueing Theory.

E N D
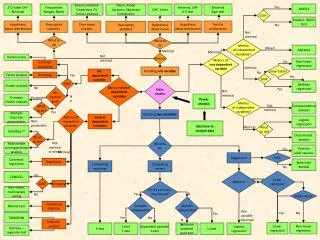
Runtime Data Flow Scheduling of Matrix Computations Ernie Chan Abstract Algorithm-by-Blocks Queueing Theory We investigate the scheduling of matrix computations expressed as directed acyclic graphs for shared-memory parallelism. Because of the data granularity in this problem domain, even slight variations in load balance or data locality can greatly affect performance. We provide a flexible framework for scheduling matrix computations, which we use to empirically quantify different scheduling algorithms. We have developed a scheduling algorithm that addresses both load balance and data locality simultaneously and show its performance benefits. Single-queue multi-server system PE1 Iteration 1 Iteration 2 A single-queue multi-server system attains better load balance than a multi-queue multi-server system. Matrix computations exhibit coarse data granularity, so the cost of performing the Enqueue and Dequeue routines are amortized over the cost of executing the tasks. We developed the cache affinity scheduling algorithm that uses a single priority queue to address load balance and software caches with each thread to address data locality simultaneously. Dequeue Chol0 A0,0:= chol(A0,0) Enqueue … Dequeue PEp Trsm1 A1,0:= A1,0 A0,0-T Syrk4 A1,1:= A1,0A1,0T Chol10 A1,1:= chol(A1,1) Multi-queue multi-server system Trsm2 A2,0:= A2,0 A0,0-T Gemm5 A2,1:= A2,0 A1,0T Syrk7 A2,2:= A2,0 A2,0T Trsm11 A2,1:= A2,1 A1,1-T Syrk13 A2,2:= A2,1 A2,1T Enqueue Dequeue PE1 … … … … Trsm3 A3,0:= A3,0 A0,0-T Gemm6 A3,1:= A3,0 A1,0T Gemm8 A3,2:= A3,0 A2,0T Syrk9 A3,3:= A3,0 A3,0T Trsm12 A3,1:= A3,1 A1,1-T Gemm14 A3,2:= A3,1 A2,1T Syrk15 A3,3:= A3,1 A3,1T Enqueue Dequeue PEp SuperMatrix Iteration 4 Iteration 3 Use separation of concerns between code that implements a linear algebra algorithm from runtime system that exploits parallelism from an algorithm-by-blocks mapped to a directed acyclic graph. Analyzer Dispatcher Performance • Delay the execution of operations and instead store all tasks in global task queue sequentially. • Internally calculate all data dependencies between tasks only using the input and output parameters for each task. • Implicitly construct a directed acyclic graph (DAG) from tasks and data dependencies. • Once analyzer completes, dispatcher is invoked to schedule and dispatch tasks to threads in parallel. • foreach task in DAGdo • if task is readythen • Enqueuetask end end • whiletasks are available do • Dequeuetask • Execute task • foreach dependent task do • Update dependent task • if dependent task is ready then • Enqueue dependent task • end end end Chol16 A2,2:= chol(A2,2) Trsm17 A3,2:= A3,2 A2,2-T Syrk18 A3,3:= A3,2 A3,2T Chol19 A3,3 := chol(A3,3) Algorithm-by-blocks for Cholesky factorization given a 4×4 matrix of blocks Reformulate a blocked algorithm to an algorithm-by-blocks by decomposing sub-operations into component operations on blocks (tasks). Performance of Cholesky factorization using several high-performance implementations (left) and finding the best block size for each problem size using SuperMatrix w/cache affinity (right) Cholesky Factorization Directed Acyclic Graph A → L LT where A is a symmetric positive definite matrix and L is a lower triangular matrix. Chol0 Trsm1 Trsm2 Trsm3 FLA_Error FLASH_Chol_l_var3( FLA_Obj A ) { FLA_Obj ATL, ATR, A00, A01, A02, ABL, ABR, A10, A11, A12, A20, A21, A22; FLA_Part_2x2( A, &ATL, &ATR, &ABL, &ABR, 0, 0, FLA_TL ); while ( FLA_Obj_length( ATL ) < FLA_Obj_length( A ) ) { FLA_Repart_2x2_to_3x3( ATL, /**/ ATR, &A00, /**/&A01, &A02, /* ************* */ /* ******************** */ &A10, /**/&A11, &A12, ABL, /**/ ABR, &A20, /**/&A21, &A22, 1, 1, FLA_BR ); /*-----------------------------------------------*/ FLASH_Chol( FLA_LOWER_TRIANGULAR, A11 ); FLASH_Trsm( FLA_RIGHT, FLA_LOWER_TRIANGULAR, FLA_TRANSPOSE, FLA_NONUNIT_DIAG, FLA_ONE, A11, A21 ); FLASH_Syrk( FLA_LOWER_TRIANGULAR, FLA_NO_TRANSPOSE, FLA_MINUS_ONE, A21, FLA_ONE, A22 ); /*-----------------------------------------------*/ FLA_Cont_with_3x3_to_2x2( &ATL, /**/&ATR, A00, A01, /**/ A02, A10, A11, /**/ A12, /* ************** */ /* ****************** */ &ABL, /**/&ABR, A20, A21, /**/ A22, FLA_TL ); } return FLA_SUCCESS; } Syrk4 Gemm5 Gemm6 Syrk7 Gemm8 Syrk9 Conclusion Chol10 Trsm11 Trsm12 Separation of concerns facilitates programmability and allows us to experiment with different scheduling algorithms and heuristics. Data locality is important as load balance for scheduling matrix computations due to the coarse data granularity of this problem domain. This research is partially funded by National Science Foundation (NSF) grants CCF-0540926 and CCF-0702714 and Intel and Microsoft Corporations. We would like to thank the rest of the FLAME team for their support, namely Robert van de Geijn and Field Van Zee. Syrk13 Gemm14 Syrk15 Map an algorithm-by-blocks to a directed acyclic graph by viewing tasks as the nodes and data dependencies between tasks as the edges in the graph. Trsm1 reads A0,0 after Chol0 overwrites it. This situation leads to the flow dependency (read-after-write) between these two tasks. Chol16 Trsm17 References [1] Ernie Chan, Enrique S. Quintana-Ortí, Gregorio Quintana-Ortí, and Robert van de Geijn. SuperMatrix out-of-order scheduling of matrix operations on SMP and multi-core architectures. In Proceedings of the Nineteenth Annual ACM Symposium on Parallelism in Algorithms and Architectures, pages 116-125, San Diego, CA, USA, June 2007. [2] Ernie Chan, Field G. Van Zee, Paolo Bientinesi, Enrique S. Quintana-Ortí, Gregorio Quintana-Ortí, and Robert van de Geijn. SuperMatrix: A multithreaded runtime scheduling system for algorithms-by-blocks. In Proceedings of the Thirteenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 123-132, Salt Lake City, UT, USA, February 2008. [3] Gregorio Quintana-Ortí, Enrique S. Quintana-Ortí, Robert A. van de Geijn, Field G. Van Zee, and Ernie Chan. Programming matrix algorithms-by-blocks for thread-level parallelism. ACM Transactions on Mathematical Software, 36(3):14:1-14:26, July 2009. Syrk18 Chol19 Blocked right-looking algorithm (left) and implementation (right) for Cholesky factorization Directed acyclic graph for Cholesky factorization given a 4×4 matrix of blocks