Download

1 / 28
280 likes | 299 Views
Developed by Alias-i, the Threat Tracker Interface is a tool intended for Information Analysts to track entities and analyze real-time feeds using innovative linguistic pipeline architecture. From tokenization to entity extraction, this application streamlines the process of creating reports and conducting thorough reviews.

E N D
Alias I Linguistic PipelineArchitecture, Algorithms & Applications Bob Carpenter Alias I, Inc. carp@aliasi.com
Who is Alias-i? • Spun out of 1995 U Penn Message Understanding Conference (MUC-5) projects on coreference • Founded in 2000 by Breck Baldwin as Baldwin Language Technologies • I’m the other technical employee as of 2003. • Funded through the Defense Advance Research Projects Agency (DARPA) through the Translingual Information Detection, Extraction and Summarization Program (TIDES) and the Total, er Terrorist Information Awareness Program (TIA) • Targeting Research Analysts with Text Mining • Based in Brooklyn (we love visitors)
Application: Threat Tracker Interface • Intended for use by Information Analysts • Analysts typically get short-term assignments and are asked to do thorough reviews, producing reports at the end. • Some analysts are assigned to track situations longer term. • Use unstructured news feeds and standing collections as sources • Basically, a lot like legal, medical or biological research • Trackers Specify Structured Searchers & Gatherers • Entities, Sub-trackers, Sample Documents, Saved Keyword Searches, Alerts • Allow addition of annotated documents making up a case • Entities Specify • Aliases • Spelling, Language, Coreference Properties • Properties • Person (Gender), Place, Thing, Other • Trackers Evaluated against real-time feeds and/or standing collections
Tracker Example(s) • Tracker: New York Yankees • Entity: New York Yankees • Aliases: Bronx bombers, … • Properties: Organization • Tracker: Yankee Players • Entity: Joe Dimaggio Aliases: Joltin’ Joe, The Yankee Clipper, Joe D Properties: Person/male • Entity: Babe Ruth • … • Entity: Yankee Stadium • Aliases: The stadium, The house that Ruth built, … • Properties: Facility • Document: (The Onion) Steinbrenner corners free-agent market. • Tracker: Sports • Tracker: Baseball • Tracker: Teams • Tracker: NY Yankees
ThreatTracker Interface: Screenshot ‘…’ indicates sentences have been removed because they don’t mention the Entity Translation of Excerpt Summary Mentions of Vajpayee and Pakistan found by ThreatTrackers
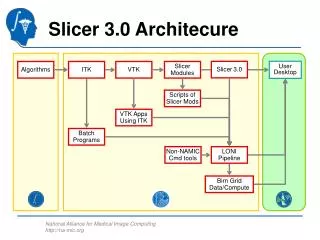
Client and Web-Container ArchitectureFlexible Model-View-Controller (MVC)
LingPipe Document Analysis • LingPipe implements (most of) Document Analysis • XML, HTML and Plain Text input; (well-formed) XML output • Tokenization • Named-entity Extraction • Sentence Boundary Detection • Within-document Coreference • Not yet released: cross-document coreference • Dual Licensing • “Open Source” • Commercial • 100% Pure Java (runs anywhere that runs Java) • Quick Start-up with sample scripts & Ant tasks • Extensive JavaDoc • API & Command-line resources • Production quality code & unit testing
XML Handling: SAX Filters • All input/output is handled through SAX filters • Streams all I/O at the element level • An org.xml.sax.ContentHandler receives callbacks: • startElement(Element, Attributes); endElement(Element); • startDocument(); endDocument(); • characters(char[] cs, int start, int length) • And a whole lot more • Not event-based, despite what everyone calls it • SAX filters • Same pattern as the Java stream filters (eg. java.io.InputStreamFilter) • Allow chains of handlers to be combined • Full XML Processing • Entities, DTD validation, character sets, etc. • Supplied filters tunable to input elements, or can be run on all text content
HTML & Plain Text Handling • HTML run through CyberNeko’s HTML • Implements org.xml.sax.XMLReader over HTML input • HTML’s a mess, so you’re taking chances • Plain Text Input • Handled with SAX filter, with wrapper elements • Text just sent to characters()
Tokenization • General Interface Streams output • Tokenizer(char[], int, int) • String nextToken() • String nextWhitespace() • Whitespaces critical for reconstructing original document with tags in place • Implementation for Indo-European • Very fine-grained tokenization • But try to keep numbers, alphanumerics, and compound symbols together • 555-1212; 100,000; ---; 40R • Not “cheating” as in many pre-tokenized evaluations • Break on most punctuation • “Mr. Smith-Jones.” yields 6 tokens
Interfaces & “Abstract” Factories • Interfaces allow flexible implementations of tokenizers • Factories allow reflectively specified tokenizer creation • TokenizerFactory interface (not an “abstract class”) • Tokenizer createTokenizer(char[] cs, int start, int length); • All APIs accept tokenizer factories for flexibility • Reflection allows command-line specification • -tokenizerFactory=fee.fi.fo.fum.TokenizerFactory • Java’s Reflection API used to create the tokenizer factory • Assumes nullary constructor for factory • Named-entity extraction and string-matching also handled with factories for flexible implementations
Named Entity Detection • Balancing Speed With Efficiency • 100K tokens/second runtime • Windows XP • 3GHz P4, 800MHz FSB, 2*10K ATA disks in RAID-0 • Sun’s JDK 1.4.2 on Windows XP • -server mode • .93 MUC7 F-score (more on scores later) • Very low dynamic memory requirements due to streamed output • Train 500K tokens, decode & score 50K tokens in 20-30 seconds • Pipelined Extraction of Entities • Speculative • User-defined • Pronouns • Stop-list Filtering (not in LingPipe, but in ThreatTracker) • User-defined Mentions, Pronouns & Stop list • Specified in a dictionary • Left-to-right, Longest match • Removes overlapping speculative mentions • Stop list just removes complete matches
Speculative Named Entity Tagging • Chunking as Tagging • Convert a “parsing” problem to a tagging problem • Assign ST_TAG, TAG and OUT to tokens • INPUT: John Smith is in Washington. • OUTPUT: John:ST_PERSONSmith:PERSONis:OUTin:OUTWashington:ST_LOCATION.:OUT
Statistical Named Entity Model • Generative Statistical Model • Find most likely tags given words • ARGMAX_Ts P(Ts|Ws) = ARGMAX_Ts P(Ts,Ws)/P(Ws) = ARGMAX_Ts P(Ts,Ws) • Predict next word/tag pair based on previous word/tag pairs • word trigram, tag bigram history • Decompose into tag and lexical model • P(w[n],t[n] | t[n-1], w[n-1], w[n-2]) = P(t[n] | t[n-1], w[n-1], w[n-2]) [tag model] * P(w[n] | t[n], t[n-1], w[n-1]) [lexical model] • State Tying for Lexical Model • P(w[n]) | t[n], t[n-1], …) t[n-1] doesn’t differentiate TAG and ST_TAG • P(w[n] | t[n], t[n-1], w[n-1], w[n-2]) ~ P(w[n] | t[n], w[n-1] ) if t[n] != t[n-1] • Bigram model within category • P(w[n] | t[n], t[n-1], w[n-1], w[n-2]) ~ P(w[n] | t[n], t[n-1]) if t[n] = t[n-1] • Unigram model cross category
Smoothing the Named Entity Model • Witten-Bell smoothing • Not as accurate as held-out estimation, but much simpler • P’(E|C1,C2) = lambda(C1,C2) * P_ml(E|C1,C2) + (1 – lambda(C1,C2) * P’(E|C1) • lambda(x) = events(x) / (events(x) + K * outcomes(x)) • Lexical Model: smooth to uniform vocab estimate • Tag Model: tag given tag for well-formedness • Category-based Smoothing of Unknown Tokens • Assign lexical tokens to categories • Capitalized, all-caps, alpha-numeric, number+period, etc. • Replace unknown words with categories • Result is not joint model of P(Ws,Ts) • OK for maximizing P(Ts|Ws) • No category-based smoothing of known tokens in history
Blending Dictionaries/Gazetteers • Lexical and Tag models • Given “John”:PERSON • P(John|ST_PERSON) ++ • Given “John Smith”:PERSON • P(Smith|PERSON,ST_PERSON,John) ++ • P(PERSON|ST_PESON,John) ++ • Given “John Smith Junior”:PERSON • P(Junior|PERSON,PERSON,Smith,John) ++ • P(PERSON|PERSON,Smith,John) ++ • Easier with pure language-model based system
Multi-lingual & Multi-genre Models • Based on language segmentation for SpeechWorks • Trained models for Hindi & English • TIDES Surprise Language 2003 • Ported our ThreatTracker interface • About ½-1% f-score hit for using multilingual model • Models don’t interfere much • P(w[n] | t[n], t[n-1], w[n-1]) • Until smoothing to P(w[n] | t[n]), only use Hindi context for Hindi following if t[n], w[n-1] is known. • P(t[n] | t[n-1], w[n-1], w[n-2]) • Until smoothing to P(t[n] | t[n-1]) • Would probably help to model transitions on multi-lingual data and expected quantity of each if not uniform • As is, we just trained with all the data we had (400K toks/language) • Not nearly as bad as HMMs for pronunciation variation
Named Entity Algorithms • See Dan Gusfield’s book: Algorithms on Strings and Trees • Must read for non-statistical string algorithms • Also great intro to suffix trees and computational biology • Theoretically linear in input text size * tag set size • Beam greatly reduces dependence on tagging • Smoothing ST_TAG and TAG reduces contexts by half • Dictionary-based tagging • Aho-Corasick Algorithm is linear asymptotically • Trie with suffix-to-prefix matching • Actually more efficient to just hash prefixes for short strings • Statistical Model Decoding • Simple dynamic programming (often called “Viterbi”) • Only keep best analysis for outcome given history • Outcomes are tags, and only bigram tag history • Lattice slicing for constant memory allocation (vs. full lattice) • Allocate a pair of arrays sized by tags and re-use per token • Still need backpointers, but in practice, very deterministic • Rely on Java’s Garbage Collection
So why’s it so slow? • Limiting factor is memory to CPU bandwidth • aka frontside bus (FSB) • Determined by Chipset, motherboard & memory • Best Pentium FSB: 800MHz (vs 3.2GHz CPU) • Best Xeon FSB: 533MHz • Models are 2-15 MB, even pruned & packed • CPU L2 Cache sizes are 512K to 1MB • Thus, most model lookups are cache misses • Same issue as database paging, only closer to CPU
Packing Models into Memory • Based on SpeechWorks Language ID work • Had to run on a handheld with multiple models • Prune Low Counts • Better to do Relative Entropy Based Pruning: Eliminate estimate counts that are similar to smoothed estimates • Symbol tables for tokens & 32-bit floating point • At SPWX, mapped floats to 16-bit integers • Trie-structure from general to specific contexts • Only walk down until context is found (Lambda != 0.0) • P(w[n] | t[n], t[n-1], w[n-1]) • Contexts: t[n] t[n-1] w[n-1] log(1 – lambda(context)) • Outcomes: w[n] w[n] w[n] log(P(w[n] | context) • Array-based with binary search • Binary search is very hard on memory with large arrays • Better to hash low-order contexts, OK for smaller contexts • I’m going to need the board for this one
Named Entity Models and Accuracy • Spanish News (CoNLL): P=.95, R=.96, F=.95 • English News (MUC7): P=.95, R=.92, F=.93 • Hindi News (TIDES SL): P=.89, R=.84, F=.86 • English Genomics (GENIA): P=.79, R=.79, F=.79 • Dutch News (CoNLL): P=.90, R=.68, F=.77 • All tested without Gazetteers • All Caps models only 5-10% less accurate
Within-Document Coreference • Mentions merged into mention chains • Greedy left-to-right algorithm over mentions • Computes match of mention vs. all previous mention chains • No-match creates new mention chain • Ties cause new mention chain (or can cause tighter match) • Matching functions determined by entity type (PERSON, ORGANIZATION, etc.) • Generic matching functions for token-sensitive edit distance • Next step is soundex style spelling variation • Specialized matching for pronouns and gender • Matching functions may depend on user-defined entities providing thesaurus-like expansion (“Joe Dimaggio” and “Joltin’ Joe” or “the Yankee Clipper”) • User-configurable matching based on entity type (e.g. PROTEIN) • Next step is to add contextual information
Cross-Document Coreference • Mention Chains merged into entities • Greedy order-independent algorithm over mention chains • Matching functions involve complex reasoning over sets of mentions in chain versus sets of mention in candidate entities. • Matching involves properties of the mentions in the whole database and degree of overlap • “Joe” or “Bush” show up in too many entities to be good distinguishing matchers • Chain: “John Smith”, “Mr. Smith”, “Smith” • Entity1: John Smith Jr., John Smith, John, Smith • Entity 2: John Smith Sr., John Smith, Jack Smith, Senior • Chain: “John James Smith”, “John Smith” • Entity: John Smith, Smith, John K. Smith • Only pipeline component that must run synchronously. • Only takes 5% of pipeline processing time. • Next Step (recreating Bagga/Baldwin): Contextual Information
Document Feed Web Service for DARPA • HTTP Implementation of Publish/Subscribe. • Implemented as Servlets. • Subscribers submit URL to receive documents. • Publishers submit binary documents. • May be validated if form is know; eg. XML DTD. • Subscribers receive all published documents via HTTP. • A more general implementation allows reception by topic.
What’s next? • Goal is total recall, with highest possible precision • Finding “spelling” variations of names • Suffix Trees • Edit Distance (weighted by spelling variation) • Cross-linguistically (pronunciation transduction) • Context (weighted keyword in context) • Over 100K newswire articles • Name structure • Nicknames: Robert:Bob • Acronyms: International Business Machines:IBM • Abbreviationss: Bob Co:Bob Corporation
Analyzed Document Format <!ELEMENT DOCUMENT (P)*> <!ATTLIST DOCUMENT uri CDATA #REQUIRED source CDATA #REQUIRED language CDATA #REQUIRED title CDATA #REQUIRED classification CDATA "UNCLASSIFIED" date CDATA #REQUIRED> <!ELEMENT P (S)*> <!-- Analysis adds rest of data to input document --> <!ELEMENT S (#PCDATA | enamex)*> <!ELEMENT ENAMEX (#PCDATA)> <!ATTLIST ENAMEX id CDATA #REQUIRED type CDATA #REQUIRED>