Download
1 / 1
10 likes | 123 Views
Outliers Rejection Based On Repeated Medians. Author’s Name : Hanzi Wang Supervisor : David Suter Associate supervisor : Ray mond Jarvis. Introduction.

E N D
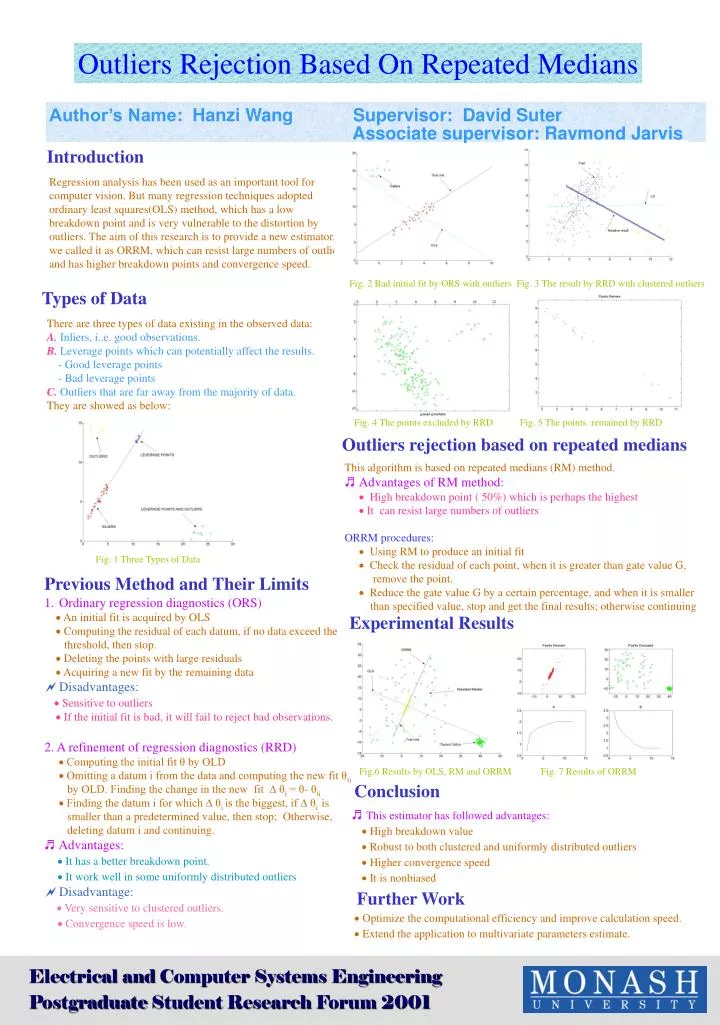
Outliers Rejection Based On Repeated Medians Author’s Name: Hanzi Wang Supervisor: David Suter Associate supervisor: Raymond Jarvis Introduction Regression analysis has been used as an important tool for computer vision. But many regression techniques adopted ordinary least squares(OLS) method, which has a low breakdown point and is very vulnerable to the distortion by outliers. The aim of this research is to provide a new estimator, we called it as ORRM, which can resist large numbers of outliers and has higher breakdown points and convergence speed. Fig. 2 Bad initial fit by ORS with outliers Fig. 3 The result by RRD with clustered outliers Types of Data There are three types of data existing in the observed data: A. Inliers, i..e. good observations. B.Leverage points which can potentially affect the results. - Good leverage points - Bad leverage points C. Outliers that are far away from the majority of data. They are showed as below: Fig. 4 The points excluded by RRD Fig. 5 The points remained by RRD Outliers rejection based on repeated medians This algorithm is based on repeated medians (RM) method. ♬Advantages of RM method: High breakdown point ( 50%) which is perhaps the highest It can resist large numbers of outliers ORRM procedures: Using RM to produce an initial fit Check the residual of each point, when it is greater than gate value G, remove the point. Reduce the gate value G by a certain percentage, and when it is smaller than specified value, stop and get the final results; otherwise continuing Fig. 1 Three Types of Data Previous Method and Their Limits • Ordinary regression diagnostics (ORS) • An initial fit is acquiredby OLS • Computing the residual of each datum, if no data exceed the • threshold, then stop. • Deleting the pointswith large residuals • Acquiring a new fit by the remaining data • Disadvantages: Sensitive to outliers If the initial fit is bad, it will fail to reject badobservations. 2. A refinement of regression diagnostics (RRD) Computing the initial fit θ by OLD Omitting a datum i from the data and computing the new fit θii by OLD. Finding the change in the new fit ∆ θi = θ- θii Finding the datum i for which ∆ θi is the biggest, if ∆ θi is smaller than a predetermined value, then stop; Otherwise, deleting datum i and continuing. ♬Advantages: It has a better breakdown point. It work well in some uniformly distributed outliers • Disadvantage: Very sensitive to clustered outliers. Convergence speed is low. Experimental Results Fig.6 Results by OLS, RM and ORRM Fig. 7 Results of ORRM Conclusion ♬This estimator has followed advantages: High breakdown value Robust to both clustered and uniformly distributed outliers Higher convergence speed It is nonbiased Further Work Optimize the computational efficiency and improve calculation speed. Extend the application to multivariate parameters estimate. Electrical and Computer Systems Engineering Postgraduate Student Research Forum 2001