Download

1 / 1
20 likes | 140 Views
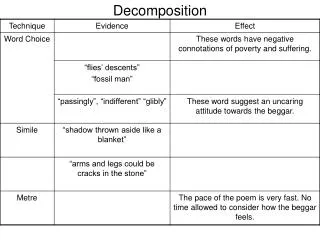
Local search. RMI. RMI. RMI. RMI. RMI. RMI. RMI. RMI. RMI. Loopback search. Remote search: 1 machine. Remote search: 2 machines. Remote search: 4 machines. Remote search: 3 machines. matches. time (ms). query (type). jon stewart (term, phrase, boolean). 405. 16. 384. 31.

E N D
Local search RMI RMI RMI RMI RMI RMI RMI RMI RMI Loopback search Remote search: 1 machine Remote search: 2 machines Remote search: 4 machines Remote search: 3 machines matches time (ms) query (type) jon stewart (term, phrase, boolean) 405 16 384 31 clinton OR senator AND new york 387 33 scandal -enron (negation) 2509 156 m*d (wildcard expansion) california~ (fuzzy-matching search) 1364 1203 2004-2005 Laserfiche Computer Science ClinicDistributing Document Search Laserfiche Document Search About Laserfiche: Laserfiche is a leading supplier of document management software allowing the electronic storage, processing, and retrieval of information from scanned and electronically stored paper documents. Problem Statement: Our team was charged with researching methods for decreasing the amount of time necessary to perform full text search within large document databases (on the order of 2-20 gigabytes of text). In particular, we were asked to focus on ways to distribute the search process – using multiple computers in parallel to achieve faster search times. Our research is to be applicable to any search system, so that Laserfiche can use our findings to guide the development of future products. Components of Search Index: Similar to an index found at the end of a textbook, an index in a search system represents a mapping from terms to documents. Not only do indices take less time to traverse than a full body of text, they are also smaller and easier to manage. Query: When a user wishes to find documents containing specific information, he or she must enter a query. Term Expansion: With wildcard and fuzzy queries, the search system first decides which terms in its vocabulary match the query. The system then executes a new query which is a boolean combination of these terms. Performing this term expansion takes a non-trivial amount of time, as the entire vocabulary must be considered for matches. By caching the results of these term expansions, time is saved for both repeated queries and subquery parts. Testing and Results Each search-distribution strategy has been tested under six network configurations and on a variety of database sizes, 500MB-4GB. Our network consists of four machines, and our configurations range from one local machine all the way to four machines communicating through Java’s built-in Remote Method Invocation (RMI) facility. The graph below demonstrates that the split-query approaches are the only that show substantial improvement, and their improvement is virtually the same. This provides empirical evidence that the dominant factor in determining search time is the number of terms being queried on each machine. Strategies that split indices into subparts, as a result, do not show the same kinds of dramatic speedup. Deliverables The team is providing Laserfiche with a comprehensive report on these results, the source code to each of the index- and query-distribution strategies, the test scaffolding, and our 8GB web-document corpus. Acknowledgments Team MembersLaserfiche Liaisons Adam Kangas (Project Manager) Kurt Rapelje Janna DeVries Karl Chan Joseph Walker Michael Allen Kamil Wnuk Faculty Advisor Zach Dodds laserfiche releases laserfiche in laserfiche1 laserfiche2 releases laserfiche document releases in laserfiche1 documents releases laserfiche management documents laserfiche management releases laserfiche documents document management laserfiche1 management documents laserfiche2 releases laserfiche documents document management management releases documents in laserfiche laserfiche1 management documents laserfiche2 releases 1 of 2 document documents management releases in laserfiche1 documents laserfiche2 management releases documents in laserfiche documents document management management documents management documents documents management management documents laserfiche management laserfiche2 2 of 2 hits vocabulary document hits document full The six network configurations used to test parallel search. Splitting Search Indices and Queries Coarse-grain divisions Fine-grain divisions Fuzziness Level # terms Example matches Laserfiche1 management documents Laserfiche2 releases Laserfiche documents document management Management releases documents in Laserfiche Laserfiche~0.99 Laserfiche~0.7 Laserfiche~0.5 Laserfiche~0.3 Laserfiche~0.0 0 1 146 7533 131072 “Laserfiche” is not indexed laserlicht innerliche, lasersight eclectic, fakeswitch wonderland, zambonini Three documents within a hypothetical search corpus Fuzzy matching can make even simple queries very large Index Decomposition A complex query is reduced to a boolean combination of terms. Index decomposition sends all of these terms to a number of machines, each of which holds a fraction of the index, as illustrated below. We have developed four approaches to index decomposition, summarized above. At the finest level of granularity, every term in the corpus is distributed to the next index in sequence. At the next level, the index is split on terms so that each fractional index has a unique vocabulary. The third method is similar, but on a per-document basis, so that every instance of a single word within a given document will reside on the same index. Finally, indices can also be split on entire documents so that each document resides on the same index. Query Decomposition In the naïve approach to parallelizing search across queries, a query is first reduced to a boolean combination of terms, and then divided evenly according to the number of available servers. All fractional queries are then searched simultaneously on separate servers that hold the entire index, and the results are returned to the client. The intelligent approach is performed on a network configuration in which all index servers contain disjoint vocabularies. Once reduced to a boolean combination of terms, a query is divided so that each component term is sent only to the index server in whose vocabulary it resides, thus reducing the average query size sent to each server. Five common query types with examples and search result times The speedup relative to single-processor local search for each of our strategies. In this graph, four machines are used to distribute a difficult search query: court~0.3 or california~0.3, with ~2000 search terms. court~ OR scot~ OR bizarre Naïve vs. intelligent query splitting For the sample query boxed at the above right, the naïve approach is illustrated to the left and the intelligent approach is shown on the right. First, the terms present in each fractional index are sent only to the appropriate index. In addition, in the intelligent approach, terms such as “bizarre” that do not appear in any of the indices are not included in any query. scottcourtcoutcurtcountcourts bizarrescot scottcurtcourtsslotscatsootscot spot courtcoutcountcotascotscoot spotscatcotascotslotsootscoot Flow chart of index-parallel search term: court term: scour term: caledonia term: cant term: four term: zabulafia Half Index Half Index Full Index Full Index Original query california~0.3 or court~0.3 … scour, four, caledonia … Term Expansion Fractional Indices term: court term: scour term: cant term: four term: caledonia term: california term: zabulafia term: court term: california Term-expansion caching reduces search time a by a factor of 2-20 for fuzzy search and by a factor of 1.5-2.5 for wildcard search.