Download

1 / 14
140 likes | 255 Views
Using Mixed Length Training Sequences in Transcription Factor Binding Site Detection Tools. Nathan Snyder Carnegie Mellon University. BioGrid REU 2009 University of Connecticut. Transcription Factors. Transcription factors regulate DNA transcription.

E N D
Using Mixed Length Training Sequences in Transcription Factor Binding Site Detection Tools Nathan Snyder Carnegie Mellon University BioGrid REU 2009 University of Connecticut
Transcription Factors Transcription factors regulate DNA transcription
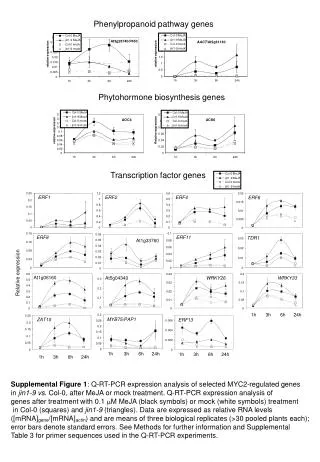
Transcription Factor Binding Site Detection Algorithms Training sequences AGATCGTT ACATGATT TGATGGAT Genetic region to search ATCGTCGATGCTGAGATGTCTATCGTAGCTAGTC Highest scoring sequence in that region AGATGTCT
Assessment by Osada et al. Compared various transcription factor binding site detection algorithms Consensus: builds a consensus sequence based on the training data PSSM: makes a scoring matrix based on the logs of nucleotide frequencies. Berg and von Hippel: like PSSM, but with nucleotide counts instead of freqs. Centroid: sum of position specific frequencies
The Same Length Training Sequence Assumption Example set of known binding sites from TRANSFAC: ACATTTAACTGGTTAATTGA ATAACCCAAT TTAATCCGTT ACCGGGTTGC TCGAAGGGATTAG ACTGGGTTAT TTAACCCGTTT TTAGCGGCATAAAAGGGTTAAACAGG AATGCGCGCCCATAAAAGGGTTAAG
Project Goal Modify the tools evaluated by Osada et al. to handle training sets with varying sequence length and still produce decent performance
Overall Strategy Step 1: Alignment AGCTTTCA ACCTTTGGAC GTAACTTTCA AGCTTTCA ACCTTTGGAC GTAACTTTCA Step 2: Scoring ACTGAGTCGATAATTTTGAACTG AATTTTGA
MLCentroid Applies this strategy to the Centroid algorithm Centroid was chosen for its strong performance, more efficient execution, and ease of implementation The same techniques could be readily applied to any of the other algorithms
Running Time Issues Quadratic is MUCH better than exponential! First version: O(c * L^numseqs) Second version: O(c * L * numseqs^2)
Method of Testing Leave one out testing similar to that used by Osada Counts the number of sequence which score higher than the desired one The data sets for Drosophila Melanogaster from Tompa's paper were used
Future Work Better alignment scoring schemes Modify and test PSSM, Berg and von Hippel, and Consensus Incorporate these techniques into de novo motif discovery algorithms Trying to incorporate sequence structure into alignment.
References Timothy L. Bailey, Nadya Williams1, Chris Misleh1 and Wilfred W. Li: MEME: discovering and analyzing DNA and protein sequence motifs, Nucleic Acids Research, 2006, Vol. 34, Web Server issue W369–W373 Berg, O. and von Hippel, P. : Selection of DNA binding sites by Regulatory Proteins. Statistical-Mechanical Theory and Application to Operators and Promoters, Journal of Molecular Biology, 1987, 193, pages 723-750 Day,W.H. and McMorris,F. : Critical comparison of consensus methods for molecular sequences. Nucleic Acids Res., 20, 1992, pages 1093–1099 Charles E. Lawrence and Andrew A. Reilly, An Expectation Maximization (EM) Algorithm for the Identification and Characterization of Common Sites in Unaligned Biopolymer Sequences, PROTEINS: Structure, Function, and Genetics, 1990 7:41-51 Robert Osada, Elena Zaslavsky, Mona Singh: Comparative analysis of methods for representing and searching for transcription factor binding sites, Bioinformatics, Vol. 20 no. 18 2004, pages 3516–3525 Giulio Pavesi, Giancarlo Mauri, and Graziano Pesole: An algorithm for finding signals of unknown length in DNA sequences , Bioinformatics, Vol. 17 Suppl. 1 2001 pages S207–S214 Giulio Pavesi, Paolo Mereghetti, Giancarlo Mauri and Graziano Pesole, Weeder Web: discovery of transcription factor binding sites in a set of sequences from co-regulated genes, Nucleic Acids Research, vol. 32, Web server issue, 2004 Tompa et al.: Assessing computational tools for the discovery of transcription factor binding sites, Nature Biotechnology, vol. 23, no. 1, January 2005, pages 137-144 http://www.embl-grenoble.fr/groups/dna/t.gif blogs.venturacountystar.com www.clas.ufl.edu