Download
1 / 40
• 480 likes • 760 Views
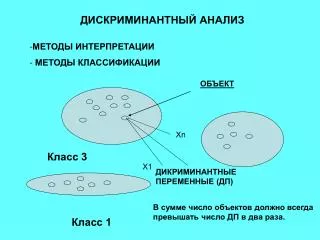
ОБЪЕКТ. Х n. Класс 3. Х1. ДИКРИМИНАНТНЫЕ ПЕРЕМЕННЫЕ (ДП). Класс 1. ДИСКРИМИНАНТН Ы Й АНАЛИЗ. МЕТО ДЫ ИНТЕРПРЕТАЦИИ МЕТОДЫ КЛАССИФИКАЦИИ. В сумме число объектов должно всегда превышать число ДП в два раза. Ограничения на ДП:

E N D
ОБЪЕКТ Хn Класс 3 Х1 ДИКРИМИНАНТНЫЕ ПЕРЕМЕННЫЕ (ДП) Класс 1 ДИСКРИМИНАНТНЫЙ АНАЛИЗ • МЕТОДЫ ИНТЕРПРЕТАЦИИ • МЕТОДЫ КЛАССИФИКАЦИИ В сумме число объектов должно всегда превышать число ДП в два раза.
Ограничения на ДП: 1) Ни одна переменная не может быть линейной комбинацией других. Соответственно недопустимы переменные, коэффициент корреляции которых равен 1. 2) Ковариационные матрицы для генеральных совокупностей равны между собой для различных классов. 3) Закон распределения для каждого класса является многомерным нормальным Этап интерпетации • Снижение размерности пространства ДП путем построения КДФ – канонические дискриминантные функции • 2. Выбор наиболее информативных КДФ • 3. Представление объектов в пространстве на основе КДФ
КДФ2 КДФ1 Построение Канонических дискриминантных функций х1 х3 х2 х4 объекты Уменьшение размерности пространства
Fkm=U0+UiXikm+U2X2km+…+UpXpkm, Fkm – значение КДФ для m-го объекта в группе К; Xikm– значение ДП Xi для m-го объекта в группе К; Ui – коэффициенты, обеспечивающие выполнение требуемых условий; ОБОЗНАЧЕНИЯ g – число классов; nk – число наблюдений в некотором классе; n. – общее число наблюдений по всем классам; Xikm – величина переменной i для m-го наблюдения в некотором классе k; Xik – средняя величина переменной i в некотором классе; Xi.. – среднее значение переменной i по всем классам (общее среднее)
1. Нахождение матрицы Т – разброс объектов между классами 2. Нахождение матрицы W – разброс объектов внутри классов 3. Нахождение матрицы В – матрицы межгрупповой суммы квадратов отклонений и попарных произведений. Bij=tij-Wij
Для нахождения коэффициентов КДФ - необходимо решить систему уравнений Решение относительно viи
Стандартизация коэффициентов Вклад каждой переменной в классификацию Максимальное количество КДФ p-g+1. Пример. P =6, классов g=3. Значит КДФ = 4 СКОЛЬКО ОСТАВИТЬ ФУКНЦИЙ И КАКИЕ? 1. Статистика Уилкса 2.Собственные числа
Функция1Функция 2 SEPALLEN ,42695 ,012408 SEPALWID ,52124 ,735261 PETALLEN -,94726 -,401038 PETALWID -,57516 ,581040 Стандартизированные коэффициенты Соб. Канон. Wilks' числа R Lambda Chi-Sqr. df p-level 0 32,191 0,984 0,023 546,1153 8 0,000000 1 ,28539 ,4711 ,7779 36,5297 3 ,000000 Наиболее значимая функция
Вид расположения объектов на основе КДФ КДФ2 КДФ1
ЭТАП КЛАССИФИКАЦИИ • На основе классифицирующих функций • 2. На основе расстояния Махалонобиса • 3. Методом Байесса 1. Классифицирующие функции Hk=bk0+bk1X1+bk2X2+…+bkpXp
КДФ2 H2- versicol У каждого класса своя классифицирующая функция H1- verginic H3-setosa КДФ1 Н1 Н1=-104.368+12.44х1+3.685х2+12.767х3+21.079х4
Новый объект х1 х4 х3 Подстановка ДП нового объекта в классифицирующие функции для каждого класса х2 Н1=-104.368+12.44х1+3.685х2+12.767х3+21.079х4 Н2=-72.85+15.69х1+7.07х2+5.21х3+6.43х4 Н3=-86.30+23.54х1+23.58х2-16.43х3-17.39х4 Новый объект классифицируется к классу где h-максимальное
2. На основе расстояния Махалонобиса КЛАССИФИКАЦИЯ ОБЪЕКТОВ НА ОСНОВЕ УНИВЕРСАЛЬНОГО КЛАССИФИКАТОРА БАЙЕССА
∆2 – критерий дискриминации Концептуальная модель дискриминантного анализа Класс W1 Новый объект x1,x2,…,xp Диск-е функции Zi=αi1x1+αi2x2+…+ αipxp i=1, 2, …, k Ков-я матрица Класс W2
КЛАССИФИКАЦИЯ В СЛУЧАЕ ДВУХ КЛАССОВ Объекты – Х=(x1,x2,…,xp). Предполагается, что класс W1 имеет распределение W2 - , где µi=(µi1, µi2,…, µip), i=1,2 Предполагаем , что ∑1=∑2=Sυj, 1. Дискриминантная функция Zi=αi1x1+αi2x2+…+ αipxp,i=1, 2, …, k Будем относить X к W1, если Z ≥ C, и к W2, если Z<C (1) Если объект Х поступил из W1, то Z имеет среднее (2) и дисперсию (3) (2) (3)
Если объект Х поступил из W2, то Z имеет среднее (4) Необходимо выбрать такие 1, …, р чтобы средние были удалены друг от друга Введем расстояние Махаланобиса (5) Нахождение таких коэффициентов из системы уравнений
X в W2 X в W1 Pr(2|1) Pr(1|2) C (6) Эвристическая процедура классификации
Pr(1|2) И Pr(2|1) Pr(1|2) +Pr(2|1) Если вектор X принадлежит W2 но то X относится к W1 - вероятность ошибочной классификации min Необходимо найти такую С, чтобы (7) • Вычисление оценок 1, …, р, удовлетворяющих системе (6) • 2. Вычисление оценок 1 и 2 по (2) и (4) • 3. Вычисление постоянной С по (7) • 4. Для каждого объекта вычислить значение ДФ – Z • 5. Если ZC, то Х принадлежит классу W1, иначе к W2
Обозначения: 1) qi – априорная вероятность, что объект принадлежит классу Wi, i=1,2 2) Pr(X|Wi) - условная вероятность получения некоторого вектора наблюдений X, если известно, что объект принадлежит к классу Wi, i=1,2. 3) Pr(Wi|X) - условная вероятность того, что объект принадлежит к классу Wi при данном векторе наблюдений X (апостериорная вероятность)
Теорема Байесса. (8) Если X имеет многомерное нормальное распределение или , (9)
Если Pr(X|W1)≥Pr(X|W2) X принадлежит W1 Или если X принадлежит W1 (10) min (12) Это величина - вероятность того, что объект, принадлежащий к популяции W1, ошибочно классифицируется, как принадлежащий W2, или наоборот, объект из W2 ошибочно относится к W1.
Алгебраическое преобразование неравенства (10) Показывает, что байесовская процедура эквивалентна отнесению X к W1, если (13) и к W2, если (14)
Обозначения: 1) C(2|1) – стоимость ошибочной классификации из-за отнесения объекта из W1 к популяции W2. 2) Аналогично C(1|2) Обобщенная процедура классификации Байесса состоит в отнесении X к W1, если (15)
и к W2, если (16) q1C(2|1)Pr(2|1)+q2C(1|2)Pr(1|2) min (17) Вероятности ошибочной классификации (19) (18)
где (20), ∆2 задается равенством (5) В случае C(1|2)= C (2|1) и q1=q2=l/2, (21)
Если X принадлежит к одной из двух известных популяций с произвольными функциями плотности f1(x) и f2(x) соответственно, то обобщенная байесовская процедура сводится к отнесению X к W1, если . Пример. Пусть X=(x1,x2) – вектор оценок абитуриента. Из опыта предыдущих лет известно, что µ1=(60,57), µ2=(42,39) и Пусть q1=1/3, q2=2/3 и примем, что C(1|2)=2000 и C(2|1)=3000 долл.
Подставляя эти значения в систему уравнений (6), получаем 100α1+70α2=18, 70α1+100α2=18, откуда α1=α2=54/510. Дискриминантная функция имеет вид Z=(54/510)(x1+x2). Согласно (2), ξ1=(54/510)(60+57)= 12.39, по (4) имеем ξ2=8.58. По (7) и (20) получаем (12.39+8.58)/2=10.49 и K=ln(4/3)=0.288. Обобщенная байессовская процедура относит объект X к классу W1,если (54/510)(x1+x2)≥10.49+0.288, т.е. x1+x2≥101.79. согласно (15) Величина σ2 (3) равна 3.81 и расстояние Махаланобиса ∆2 (5) равно 3.81.
Затем по формулам (18) - (19) получаем вероятности ошибочной классификации: Pr(2|1)=Ф(-0.83)=0.203; Pr(1|2)=Ф(-1.12)=0.131. ИТОГ: 1) Абитуриент принимается, если •линейная комбинация его оценок больше или равна 101.79 2) 20.3% потенциально хороших студентов отвергается комиссией и принимается 13.1% потенциально плохих
Классификация в случае двух многомерных нормальных популяций при неизвестных параметрах ДАНО: Имеется объект, которому соответствует вектор наблюдений X=(x1,x2,…,xp). ТРЕБУЕТСЯ: отнести объект к классу W1 с распределением или к W2 . Метод решения. Оцениваем µ1 через ∑ – объединеннойвыборочной ковариационной матрицей S=(Sυj), j=l,...,p; υ=l,...,p.
Т.е. заменяемµijна , i=l,2, j=l,...,p , и заменой Sυj на υ=l,...,p. Далее ξi, заданные (2) и (4), оцениваются величинами (22) а σ2 заданные (3) – величиной (23)
Обобщенная байесовская процедура оценивания состоит в отнесении X=(x1,x2,…,xp) к W1 если (24) Выборочное расстояние Махаланобиса (25) является оценкой для ∆2 (5).
Алгоритм работы дискриминантного анализа: • определяются коэффициенты дискриминантной функции • а1,…,аp; • б) оценивается значение дискриминантной функции Zil • для каждого вектора наблюдений xil, i=1,2; l=1,…,n; • в) определяются выборочные средние и г) рассчитывается выборочное расстояние Махаланобиса D2; д) реализуется процедура классификации в соответствии с (24). Априорные вероятности q1 и q2
Несмещенная оценка расстояния Махаланобиса: (27) Вероятность ошибочной классификации Pr(2|1) и Pr (1|2) Метод 1. Метод классифицирует каждый элемент выборки объема n1 из класса W1 и выборки объема n2 из W2 согласно выражению (24). Если m1 – число наблюдений из W1, отнесенных к W2, и m2 - число наблюдений из W2 классифицированных в W1,
Вычисление апостериорных вероятностей.
КЛАССИФИКАЦИЯ В СЛУЧАЕ Kклассов Рассмотрим случай отнесения неизвестного вектора наблюдений xpxl=(x1,...,xp) к одному из k классов Wi, i= l,...,k, k≥2. Классификация в случае классов с произвольными известными распределениями Пусть fi (x) означает плотность распределения X в Wiи qi– априорную вероятность того, что вектор наблюдения X принадлежит классу Wi, i=l,...,k. Стоимость отнесения объекта из класса Wjк Wi -C(i|j), а вероятность отнесения объекта из Wj к Wi – Pr(i|j), i,j=l,...,k; i≠j.
Обобщенная байесовская процедура классификации относит объект Х к Wi, если величина (30) Значение дискриминантной функции для i-го класса (31) Такая процедура минимизирует ожидаемую стоимость ошибочной классификации
Классификация в случае классов с многомерными нормальными распределениями Пусть популяция Wiимеет распределение с функцией плотности fi(x), i=l,...,k. δi=αi1x1+…+αipxp+γilnqi, i=1,…,k (1*) Вектор наблюдений X относится к классу Wi, если значение δiявляется максимальным среди всех i=l,...,k.
Апостериорная вероятность (2*) Пусть ni - объем i-й выборки, – ее вектор средних и Si– ковариационная матрица, i=l,...,k. Тогда в формуле (1*) можно заменить µi на хi, и ∑ – на объединенную ковариационную матрицу S: (3*)
Таким образом, оценка дискриминантной функции для i-го класса имеет вид di=ai1x1+…+aipxp+ci+lnqi, i=l,...,k (4*) При этом оценка апостериорной вероятности имеет вид (5*)
