Download
1 / 39
410 likes | 704 Views
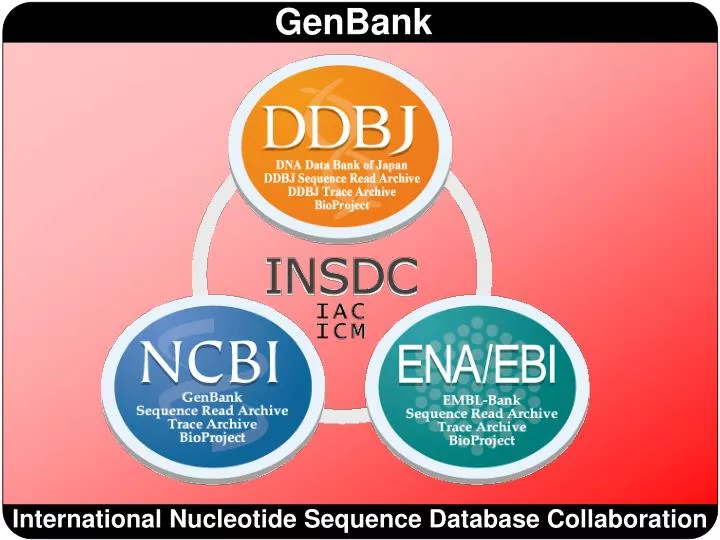
International Nucleotide Sequence Database Collaboration. ¿Qué es Genbank?. GenBank es la base de datos de secuencias genéticas del NIH. Contiene todas las secuencias de ADN de acceso público y, además, incluye anotaciones. Las secuencias están distribuídas en 3 BD: Nucleotide, EST y GSS.

E N D
¿Qué es Genbank? GenBank es la base de datos de secuencias genéticas del NIH. Contiene todas las secuencias de ADN de acceso público y, además, incluye anotaciones. Las secuencias están distribuídas en 3 BD: Nucleotide, EST y GSS http://www.ncbi.nlm.nih.gov/genbank/
Cada dos meses sale una nueva versión de GenBank. La versión 200 (15 de Febero de 2014) contiene más de 171 millones de secuencias Más o menos cada 18 meses se duplica el número de secuencias de GenBank Es posible descargar la base de datos completa desde el sitio ftp del NCBI. ftp://ftp.ncbi.nih.gov/genbank El crecimiento de GenBank
Hay varias formas de enviar secuencias a GenBank ¿Cómo envío una secuencia a GenBank?
Hay varias formas de acceder a las secuencias de nucleótidos almacenadas en Gen Bank: (1) a través de la base de datos Nucleotide, (2) a través de la herramienta BLAST o (3) a través de programas específicos desarrollados por el NCBI. ¿Cómo accedo a una secuencia de GenBank?
Puedo acceder a las secuencias almacenadas en GenBank a través de la base de datos Nucleotide. http://www.ncbi.nlm.nih.gov/nucleotide/ Acceso directo: La base de datos Nucleotide
Puedo acceder a las secuencias almacenadas en GenBank a través de la base de datos EST. http://www.ncbi.nlm.nih.gov/nucest/ Acceso directo: La base de datos EST
Puedo acceder a las secuencias almacenadas en GenBank a través de la base de datos GSS. http://www.ncbi.nlm.nih.gov/nucgss/ Acceso directo: La base de datos GSS
http://blast.ncbi.nlm.nih.gov/Blast.cgi Acceso indirecto: desde la herramienta BLAST
Pincha aquí para acceder al registro de GenBank correspondiente a una de las secuencias que ha encontrado BLAST Resultados de una búsqueda en BLAST Acceso indirecto desde la página de resultados
Pincha aquí para seleccionar GenBank Pincha aquí para acceder al fichero de GenBank correspondiente al gen que codifica esta proteína Acceso indirecto: desde un registro de la BD UniProtKB
(12) (8) Cada secuencia pertenece a una de las 20 divisiones de GenBank
Introduce aquí el término de la búsqueda Puedes seleccionar otras bases de datos Inicia la búsqueda Información sobre el NCBI Documentación sobre el NCBI Otras bases de datos http://www.ncbi.nlm.nih.gov/nucleotide
Para buscar secuencias en Gen Bank se puede introducir el nombre de una proteína, de un gen o del autor que envió la secuencia. También se puede introducir directamente el número de acceso. Si se ponen términos compuestos, entre comillas. Cómo hacer una búsqueda sencilla
Aquí se introduce el término que queremos buscar: colicin Inicio la búsqueda NUCLEOTIDE: Búsqueda rápida
También ha encontrado secuencias EST y GSS 35187 secuencias encontradas Esta búsqueda no ha sido muy productiva Hay que definir mejor los términos de la búsqueda para que me sea útil Resultados de la búsqueda
Inicio de la búsqueda Introduzco el término: “colicin A” Los términos compuestos se ponen entre comillas Búsqueda más detallada con un término compuesto
Puedes filtrar los resultados de la búsqueda Se pueden imponer límites a la búsqueda 63 secuencias encontradas Resultados de la búsqueda clasificados por organismo Selecciona las secuencias de Escherichia coli Filtrado de los resultados de la búsqueda
Inicio de la búsqueda Puedo introducir más de un término y usar los operadores lógicos (AND, OR, NOT) Búsqueda con varios términos usando operadores lógicos
Pincha aquí para acceder a la secuencia Pincha aquí para cambiar el formato de presentación de los resultados de la búsqueda Selecciona la secuencia que quieres ver
Se puede cambiar el formato de presentación de los resultados
Enlaces a otras bases de datos Registro de GenBank con el resultado de la búsqueda
Los registros almacenados en la base de datos GenBank constan de varios apartados: 1.- Encabezamiento: información general sobre el registro (identificadores, número de acceso, descripción del gen y del organismo de donde procede) 2.- Referencias bibliográficas 3.- Tabla de características (Features table) 4.- Secuencia de nucleótidos (en código de una letra) Un registro de la base de datos GenBank
Encabezamiento Referencias bibliográficas La última referencia (en este caso es la 2) incluye detalles sobre quién ha enviado la secuencia a la base de datos Encabezamiento y referencias bibliográficas
Tipos de característica Se detalla la ubicación exacta (location) de cada tipo de característica y se añaden uno o más calificadores (qualifiers). También hay enlaces a otras BD. Tabla que reúne las características de la secuencia Tabla de características (Features table)
Secuencia de nucleótidos. Cada línea contiene 60 nucleótidos agrupados en 6 bloques de 10. Símbolo que indica que se ha llegado al final del registro La secuencia de nucleótidos
Pincha aquí para ver la secuencia mediante un gráfico interactivo Pincha aquí para obtener la secuencia en formato FASTA El formato FASTA es aceptado por la mayoría de los programas de análisis de secuencias Otras formas de ver la secuencia
Línea de definición: En la primera línea se incluye una escueta definición de la secuencia. Siempre empieza por el símbolo > Secuencia ininterrumpida de nucleótidos (70 por cada línea) Es posible que te interese guardar esta secuencia en tu ordenador. Puedes hacer corta y pega y guardarla en un fichero Word. La secuencia de nucleótidos en formato FASTA
Región vista en pantalla Zoom Hebra directa 5’3’ (forward) Hebra directa (5’3’) y proteína que codifica. La hebra complementaria también puede codificar proteínas. Hebra complementaria (complement) Gráfico interactivo de la secuencia
Forward: Cualquier secuencia escrita en sentido (5’ 3’) 5’-gaggagaagtctgccgttactgccctgtgg-3’ Reverse: la secuencia anterior escrita en sentido (3’ 5’) 3’-ggtgtcccgtcattgccgtctgaagaggag-5’ Complement: la secuencia complementaria escrita en sentido (3’ 5’) 5’-gaggagaagtctgccgttactgccctgtgg-3’ 3’-ctcctcttcagacggcaatgacgggacacc-5’ Reverse-complement: la secuencia complementaria escrita en sentido (5’ 3’) 5’-gaggagaagtctgccgttactgccctgtgg-3’ 5’-ccacagggcagtaacggcagacttctcctc-3’ Forward, reverse, complement and reverse-complement
La hebra que sirve de molde para la transcripción es la hebra antisentido. También se llama hebra no codificante, hebra (-) o hebra de Watson. La hebra complementaria, que no sirve de molde para la transcripción, es la hebra con sentido. Su secuencia es igual a la del transcrito RNA (cambiando U por T). También se llama hebra codificante, hebra (+) o hebra de Crick. ¿Qué sentido tiene todo esto?
Pinchando en cada característica (feature), la puedes ver con todo detalle Se puede ver cada característica por separado
Se resalta la región de la secuencia de nucleótidos que corresponde a la CDS (empieza por ATG y termina en TAA) Pincha aquí para obtener la región seleccionada en formato FASTA Pincha aquí para seleccionar otra característica Pincha aquí para saltar de una característica a otra Enlaces a otras BD que ofrecen información relacionada Pincha aquí para obtener la región seleccionada en el formato de GenBank Pincha aquí para ver los detalles relacionados con la característica seleccionada Vista detallada de una característica (CDS)
Pincha aquí para hacerte con una copia del registro Seleccionar la parte del registro que te interesa Pincha aquí para seleccionar el formato en que quieres almacenar el registro Pincha aquí para crear un fichero con tu selección Cómo guardar una copia del registro en tu ordenador
Capítulo 2: How most people use Bioinformatics Capítulo 3: Using nucleotide sequences databases Bibliografía