Download
1 / 1
10 likes | 144 Views
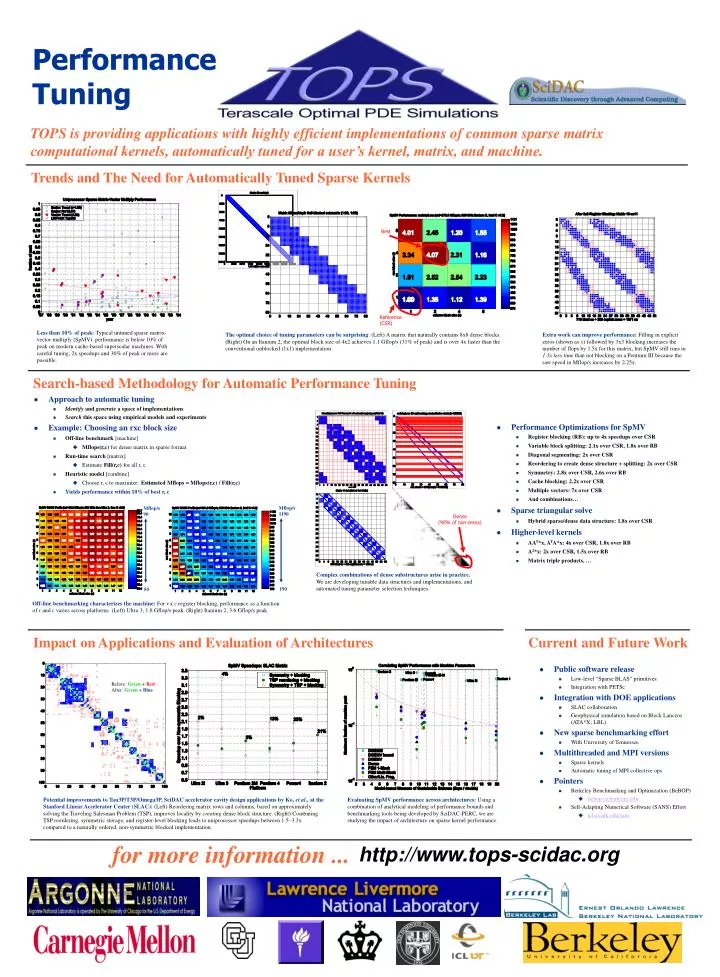
Best. Reference (CSR). Mflop/s 1190. Mflop/s 90. Dense (90% of non-zeros). 50. 190. Performance Tuning. TOPS is providing applications with highly efficient implementations of common sparse matrix computational kernels, automatically tuned for a user’s kernel, matrix, and machine.

E N D
Best Reference (CSR) Mflop/s 1190 Mflop/s 90 Dense (90% of non-zeros) 50 190 Performance Tuning TOPS is providing applications with highly efficient implementations of common sparse matrix computational kernels, automatically tuned for a user’s kernel, matrix, and machine. Trends and The Need for Automatically Tuned Sparse Kernels Less than 10% of peak: Typical untuned sparse matrix-vector multiply (SpMV) performance is below 10% of peak on modern cache-based superscalar machines. With careful tuning, 2x speedups and 30% of peak or more are possible. The optimal choice of tuning parameters can be surprising: (Left) A matrix that naturally contains 8x8 dense blocks. (Right) On an Itanium 2, the optimal block size of 4x2 achieves 1.1 Gflop/s (31% of peak) and is over 4x faster than the conventional unblocked (1x1) implementation. Extra work can improve performance: Filling in explicit zeros (shown as x) followed by 3x3 blocking increases the number of flops by 1.5x for this matrix, but SpMV still runs in 1.5x less time than not blocking on a Pentium III because the raw speed in Mflop/s increases by 2.25x. Search-based Methodology for Automatic Performance Tuning • Approach to automatic tuning • Identify and generate a space of implementations • Search this space using empirical models and experiments • Example: Choosing an rxc block size • Off-line benchmark [machine] • Mflops(r,c) for dense matrix in sparse format • Run-time search [matrix] • Estimate Fill(r,c) for all r, c • Heuristic model [combine] • Choose r, c to maximize: Estimated Mflops = Mflops(r,c) / Fill(r,c) • Yields performance within 10% of best r, c • Performance Optimizations for SpMV • Register blocking (RB): up to 4x speedups over CSR • Variable block splitting: 2.1x over CSR, 1.8x over RB • Diagonal segmenting: 2x over CSR • Reordering to create dense structure + splitting: 2x over CSR • Symmetry: 2.8x over CSR, 2.6x over RB • Cache blocking: 2.2x over CSR • Multiple vectors: 7x over CSR • And combinations… • Sparse triangular solve • Hybrid sparse/dense data structure: 1.8x over CSR • Higher-level kernels • AAT*x, ATA*x: 4x over CSR, 1.8x over RB • A2*x: 2x over CSR, 1.5x over RB • Matrix triple products, … Complex combinations of dense substructures arise in practice. We are developing tunable data structures and implementations, and automated tuning parameter selection techniques. Off-line benchmarking characterizes the machine: For r x c register blocking, performance as a function of r and c varies across platforms. (Left) Ultra 3, 1.8 Gflop/s peak. (Right) Itanium 2, 3.6 Gflop/s peak. Impact on Applications and Evaluation of Architectures Current and Future Work • Public software release • Low-level “Sparse BLAS” primitives • Integration with PETSc • Integration with DOE applications • SLAC collaboration • Geophysical simulation based on Block Lanczos (ATA*X; LBL) • New sparse benchmarking effort • With University of Tennessee • Multithreaded and MPI versions • Sparse kernels • Automatic tuning of MPI collective ops • Pointers • Berkeley Benchmarking and Optimization (BeBOP) • bebop.cs.berkeley.edu • Self-Adapting Numerical Software (SANS) Effort • icl.cs.utk.edu/sans Before: Green + Red After: Green + Blue Potential improvements to Tau3P/T3P/Omega3P, SciDAC accelerator cavity design applications by Ko, et al., at the Stanford Linear Accelerator Center (SLAC): (Left) Reordering matrix rows and columns, based on approximately solving the Traveling Salesman Problem (TSP), improves locality by creating dense block structure. (Right) Combining TSP reordering, symmetric storage, and register-level blocking leads to uniprocessor speedups between 1.5–3.3x compared to a naturally ordered, non-symmetric blocked implementation. Evaluating SpMV performance across architectures: Using a combination of analytical modeling of performance bounds and benchmarking tools being developed by SciDAC-PERC, we are studying the impact of architecture on sparse kernel performance. for more information ... http://www.tops-scidac.org