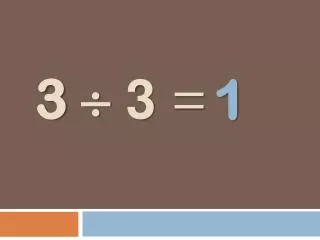Download

1 / 97
970 likes | 1.11k Views
第 3 章 栈与队列. 目录. 1. 栈. 2. 栈的 应用举例. 3. 栈与递归. 4. 队列. 5. 应用实例. 3.1 栈. 3.1.1 栈的定义及其运算. 栈 ( Stack ) 是限定插入和删除运算只能在表尾进行的线性表。 通常称允许插入、删除的这一端为栈顶,另一端称为栈底。 当表中没有元素时称为空栈。 其中数据元素的个数 n 定义为表的长度。. 图 3.1 是一个栈的示意图,通常用指针 top 指示栈顶的位置,用指针 bottom 指向栈底。栈顶指针 top 动态反映栈的当前位置。.

E N D
目录 1.栈 2. 栈的应用举例 3. 栈与递归 4. 队列 5. 应用实例
3.1 栈 3.1.1 栈的定义及其运算 栈(Stack)是限定插入和删除运算只能在表尾进行的线性表。 通常称允许插入、删除的这一端为栈顶,另一端称为栈底。 当表中没有元素时称为空栈。 其中数据元素的个数n定义为表的长度。
图3.1是一个栈的示意图,通常用指针top指示栈顶的位置,用指针bottom指向栈底。栈顶指针top动态反映栈的当前位置。图3.1是一个栈的示意图,通常用指针top指示栈顶的位置,用指针bottom指向栈底。栈顶指针top动态反映栈的当前位置。 图3.1所示的栈中,元素是以a1, a2,…,an的顺序进栈,而出栈 的次序却是an,an-1,…,a1。 也就是说,栈的修改是按后进先 出的原则进行的。因此,栈又称为 后进先出(Last In First Out)的线性表,简称为LIFO表。
栈的ADT声明如下: ADT Stack {Typedef struct Stack S; InitStack(S,maxSize); 说明:构造空栈S,即栈的初始化 StackSize(S); 说明:求栈中元素的数目 isEmpty(S); 说明:判栈S是否为空栈 isFull(S); 说明:判栈S是否已“满”
GetTop(S,e); 说明:取栈顶元素 Push (S,e); 说明:值为e的数据元素进栈(插入、压栈) Pop(S); 说明:栈顶元素出栈(删除、退栈) };
3.1.2 栈的顺序存储结构 栈的顺序存储结构称为顺序栈,是用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。 因为栈底位置是固定不变的,栈顶位置是随着进栈和退栈 操作而变化的,故需用一个变量top来指示当前栈顶位置, 通常称top为栈顶指针,参看图3.2。
我们先以整数元素为例,给出顺序栈的基本算法,在下一节,将给出顺序栈的模板类接口定义以及基本运算的实现代码和应用实例。我们先以整数元素为例,给出顺序栈的基本算法,在下一节,将给出顺序栈的模板类接口定义以及基本运算的实现代码和应用实例。 Typedef struct { int *elem; // elem是数据元素数组 int top; // 栈顶指针 int maxSize; // 栈容量 }sqStack;
void InitStack(S,maxSize) // 栈初始化 { S.top=-1; S.elem=new int[maxSize]; } bool isEmpty(S) //判栈空否? { return S.top==-1; } bool isFull (S) // 判栈满否? { return top==S.maxSize-1; } boolPush (sqStack S, int e) // 值为e的数据元素进栈(插入 、 压栈) { if(isFull(S)) // 栈满(溢出)无法进栈, 返回false { cout << " ERROR: overflow !!\n"; return false; } S.elem[++S.top] = e ; return true ; //栈顶指针增1元素进栈, 返回true }
bool Pop(sqStack S) // 栈顶元素出栈(删除) { if(isEmpty(S)) // 栈空无法删除, 返回false { cout << “ ERROR: underflow !!\n”; return false ; } S.top--; return true; // 元素出栈 } bool GetTop(sqStack S, int &e) // 取栈S的栈顶元//素 { if(isEmpty(S)) // 栈空(下溢) { cout << “ ERROR: underflow !!\n”; return false ; } e=S.elem[S.top] ; return true ; // 元素存e, 栈顶指针不变(元素没出栈) }
栈的使用非常广泛,常常会出现在一个程序中需要同时使用多个栈的情形。为了不因栈上溢而产生错误中断,要给每个栈预分较大空间,但各个栈实际所用最大空间很难估计。而且各个栈的实际容量在使用期间是变化的,往往会出现某个栈发生上溢,而另一个栈还是空的。栈的使用非常广泛,常常会出现在一个程序中需要同时使用多个栈的情形。为了不因栈上溢而产生错误中断,要给每个栈预分较大空间,但各个栈实际所用最大空间很难估计。而且各个栈的实际容量在使用期间是变化的,往往会出现某个栈发生上溢,而另一个栈还是空的。 试设想,若令多个栈共享空间,则将提高空间的使用效率,并减少发生栈上溢的可能性。
假设在程序中需设两个栈,并共享一维数组空间v[m]。则利用“栈底位置不变”的特性,可将两个栈的栈底分别设在数组空间的两端,然后各自向中间伸展(如图3.3所示),仅当两个栈的栈顶相遇时才可能发生上溢。由于两个栈之间可以做到互补余缺,使得每个栈实际可利用的最大空间大于m/2。显然,两个栈顶的初值分别为-1和m。假设在程序中需设两个栈,并共享一维数组空间v[m]。则利用“栈底位置不变”的特性,可将两个栈的栈底分别设在数组空间的两端,然后各自向中间伸展(如图3.3所示),仅当两个栈的栈顶相遇时才可能发生上溢。由于两个栈之间可以做到互补余缺,使得每个栈实际可利用的最大空间大于m/2。显然,两个栈顶的初值分别为-1和m。
3.1.3 栈的链式存储结构 栈的链式存储结构称为链栈,它是运算受限的单链表,其插入和删除操作仅限制在表头位置上进行。 由于只能在链表头部进行操作, 故链栈没有必要象单链表那样 附加上头结点。栈顶指针就是 链表的头指针,如图3.4所示, 链栈就是无头结点的单链表 (头指针改称栈顶指针),因 此不再重新讨论。
3.2栈的应用举例 栈的应用非常广泛,只要问题满足LIFO原则,均可使 用栈做数据结构。 //顺序栈的模板类接口定义以及基本运算的实现代码 template <class T> class sqStack { protected: int *elem ; // 指向存放数据元素的数组指针 int top ;// 栈顶指针 int maxSize; // 栈容量 public: sqStack(int ms=10); // 构造函数
sqStack (const sqStack<T>&); // 复制构造函数 ~sqStack() { delete[] elem; } // 析构函数 sqStack& operator=(const sqStack<T>&); // “=”运算符重载 bool isEmpty() { return top == -1 ; } // 判栈“空”否? bool isFull() // 判栈“满” 否? { return top == maxSize-1; } bool Push(T); // 进栈 (插入、压栈) bool Pop(); // 出栈 (删除、退栈) bool GetTop(T &); // 取栈顶元素 };
template <class T>sqStack<T>::sqStack(int ms) // 构造“空” 栈 { if(ms<=0) { cout<<"ERROR:invalid MaxSize!!\n"; return; } elem=new T[ms]; MaxSize=ms; top=-1; } template <class T>bool sqStack<T>::Push(T e) // 元素e压栈 { if(isFull()) // 栈满(溢出) { cout << “ ERROR: overflow !!\n”; return false; } elem[++top]=e; // 栈顶指针增1, 元素进栈 return true; }
template <class T>bool sqStack<T>::Pop() //栈顶元素出栈, 被删元素存e { if(isEmpty()) // 栈空(下溢) { cout << “ ERROR: underflow !!\n”; return false; } top--; //栈顶指针减1(元素出栈) return true; } template <class T>bool sqStack<T>::GetTop(T &e) // 取栈顶元素 { if(isEmpty(S)) // 栈空(下溢) { cout << “ ERROR: underflow !!\n”; return false; } e=elem [top]; // 元素存e, 栈顶不变(元素没出栈)
return true; } template <class T>sqStack<T>::sqStack(const sqStack<T>& obj) //由顺序栈obj复制构造新栈 { MaxSize=obj.MaxSize; //被构造栈与obj容量应相同 elem=new T [MaxSize]; top = obj.top; //申请空间, 栈顶指针赋值 for(int j=0; j<=top; j++) elem[j]= obj.elem[j]; // 复制数据元素 }
template<classT>sqStack<T>&sqStack<T>::operator=(const sqStack<T>&origin) //"="运算符重载 { if(MaxSize!=origin.MaxSize) //栈容量不等 //需释放原来的存放数据元素空间,重新为当前栈申请空间 {delete[] elem; MaxSize=origin.MaxSize; elem=new T [MaxSize]; } top=origin.top; //栈顶指针赋值 for(int j=0; j<=top; j++) elem[j]=origin.elem[j]; //复制数据元素 }
【例3.1】用栈实现程序设计语言中的子程序调用【例3.1】用栈实现程序设计语言中的子程序调用 和返回。 假设有一个主程序main和三个子程序A1,A2和A3,其调用关系如图3.5所示。
从图3.5可知,主程序main调用子程序A1,子程序A1完成之后,返回到主程序的r处继续执行。但是,因为子程序A1又调用了子程序A2,所以在A2执行完毕并返回之前,A1是不可能结束的。类似地,A2也必须在A3执行完毕并返回之后才能从t处继续进行。其调用与返回的过程如图3.6所示。从图3.5可知,主程序main调用子程序A1,子程序A1完成之后,返回到主程序的r处继续执行。但是,因为子程序A1又调用了子程序A2,所以在A2执行完毕并返回之前,A1是不可能结束的。类似地,A2也必须在A3执行完毕并返回之后才能从t处继续进行。其调用与返回的过程如图3.6所示。 显然,调用次序和返回次序是 相反的,最后调用到的子程序 最先返回。为了保证各个被调 用子程序能正确地返回,可以 在程序运行期间设置一个工作 栈来保存返回地址。
当调用某一个子程序时,将该子程序的返回地址进栈;当某一子程序执行完毕时将当前栈顶的返回地址出栈,并按该地址返回。注意,某一子程序P执行完毕,当前栈顶内容一定是P的返回地址。因为只有当执行P时所调用的其它子程序都已返回,P才能结束,这就保证了当P返回时,其相应的返回地址正好是在当前栈顶,参看图3.7。当调用某一个子程序时,将该子程序的返回地址进栈;当某一子程序执行完毕时将当前栈顶的返回地址出栈,并按该地址返回。注意,某一子程序P执行完毕,当前栈顶内容一定是P的返回地址。因为只有当执行P时所调用的其它子程序都已返回,P才能结束,这就保证了当P返回时,其相应的返回地址正好是在当前栈顶,参看图3.7。
【例3.2】 表达式转换(中缀表达式改写成后缀表 示法) 算术表达式有三种表示方法:⑴<操作数> <操作符> <操作数>,如A+B,称为中缀(infix)表示;⑵<操作符> <操作数> <操作数>,如+AB称为前缀(prefix)表示;⑶<操作数> <操作数> <操作符>,如AB+,称为后缀(postfix)表示。 在后缀表达式中,没有括号,也不存在优先级的差别,计算过程完全按照运算符出现的先后次序进行,整个计算过程仅需一遍扫描便可完成,显然比中缀表达式的计算要简单得多。因此,程序设计语言的编译系统要将通常的中缀表达式转换成后缀表达式
例如,A*(B+C)的后缀表达式是ABC+*, 因’+’运算符在前,’*’ 运算符在后,所以应先做加法,后做乘法。 再如,表达式A/B*C+D*(E-A)+C/(D*B) 的后缀形式是AB/C*DEA-*+CDB*/+ . 怎样设计算法把运算符放在两个运算对象中间的中缀表达 式转换为后缀形式呢? 观察一下两种形式的表达式,我们注意到操作数在两种形 式中出现的次序是相同的。所以在扫描表达式时,凡遇到 操作数就马上输出,剩下的事情就是处理所遇到的运算符。 解决的办法是把遇到的运算符存放到栈中,直到某个适当 时刻再将运算符退栈并输出。
我们来看两个例子: (1)要由表达式A+B*C产生出后缀表达式ABC*+,必须按照如表3.1所示的操作顺序执行(栈向右增长)。到达第4步时必须确定是’*’进入栈顶,还是’+’退栈;由于’*’的优先级更高,应该是’*’进栈,从而产生第5步;现在已从表达式中取完所有的符号,于是我们输出运算符栈中所有剩余的运算符得到: ABC*+ (2)表达式A*(B+C)/D 的后缀形式为ABC+* D/,当遇到左括号时必须入栈,遇到右括号时,必须依次把栈中元素退栈。直到相应的左括号为止,然后去掉左右括号。如表3.2所示。
这些例子启发我们,算术运算符和括号可用如表3.3所示分级方案实现。其规则是:这些例子启发我们,算术运算符和括号可用如表3.3所示分级方案实现。其规则是: 只要运算符在栈中的优先级isp(in-stack priori ty)大于或等于新运算符进来时的优先级icp(in-c oming priority),则运算符就从栈中取出。 isp(x)和icp(x)是函数,它们返回运算符按上述 给定的优先级值。
具体算法如下: //将表达式的中缀形式转换为后缀形式 #include <fstream.h> #include "SQStack.h" ofstream ofile; // 创建输出流文件 void postfix(char*e); // 将中缀表达式e转换为后缀形式输出的原型声明 void InitStack(S,maxSize) // 栈初始化 { S.top=-1; S.elem=new int[maxSize]; } bool isEmpty(S) //判栈空否? { return S.top==-1; }
bool isFull (S) // 判栈满否? { return top==S.maxSize-1; } bool Push (sqStack S, int e) // 值为e的数据元素进栈(插入、压栈) { if(isFull(S)) // 栈满 { cout << “ ERROR: overflow !!\n”; return false; } S.elem[++S.top]=e; //栈顶指针增1元素进栈 return true ; } void main() { char s[30]; int i, n; // s 存从输入流读入的待翻译的表达式字符串 ifstream infile; // 创建输入文件infile
infile.open(“expression.in”); // infile与磁盘文件expression.in 相关联 ofile.open("expression.out"); // ofile与磁盘文件expression.out相关联 infile >> n; // 从文件读入要翻译的表达式数 for(i=0; i<n; i++) // 从文件逐一读入n个中缀表达式 {infile >> s; ofile <<“ \n infix: ”<<s <<" \npostfix: "; postfix(s); // 转换中输出对应的//后缀表达式 } ofile <<endl; infile.close(); ofile.close(); }
int isp(char x) // 返回栈中运算符的优先级(in- stack priority) { if(x==‘*’||x==‘/’)return 2; else if(x=='+'||x=='-') return 1; else if(x=='(')return 0; else return -1; } int icp(char x) // 返回读入运算符的优先级(in-coming priority) { if(x=='*'||x=='/')return 2; else if(x=='+'||x=='-') return 1; else return 3; } void postfix(char *e) // 将中缀式e转换为后缀式输出
{ char y, x= *e; sqStack<char> stack ; stack.Push(‘#’); // 栈底予置一“#” while(x!=‘\0’) // x不是“空白符”(结束符) { if(x==‘)’) // 判断x是右括号吗? 是则执行退栈, 直到 '(' do{ stack.GetTop(y); stack.Pop(); if(y!='(') ofile.put(y); }while(y!='('); else // x不是右括号, 判是其它运算符?不是,则输出(操作数) if(x!=‘(’&&x!=‘+’&&x!=‘-’&&x!=‘*’&&x!=‘/’) ofile.put(x); else// x是运算符
{ do{ // 栈顶算符优先级>=读入算符优先级, 则弹 //出算符//栈的运算符并输出 stack.GetTop(y); // 取栈顶算符 if(isp(y)>=icp(x)) // 弹出算符 { ofile.put(y); Stack.Pop(); } else break; }while(true); stack.Push(x); // 刚刚读入运算符进栈 } //end_if(x!='(' … e++; x=*e; // 取表达式e的下一符号 } // 结束while(x!='\0')循环 while(stack.GetTop(x), stack.Pop(),x!=‘#’) ofile.put(x); // 输出栈中其余运算符 (#不输出) }
3.3 栈与递归 递归(recursion)是最常用的算法设计思想,采用递归 的方法来编写求解程序,使程序非常简洁而清晰,本节重点 讨论递归在计算机内的实现,以及怎样把一个递归的子程序 变换成一个等价的非递归的子程序,读者将会看到,在这里 起关键作用的是栈。 3.3.1 栈的定义及其运算 若一个对象部分地包含它自己, 或用它自己给自己定义, 则称这个对象是递归的;若一个过程直接地或间接地调用自己, 则称这个过程是递归的过程。
在以下三种情况下,常常用到递归方法。 ⑴ 定义是递归的;如,我们熟悉的Factorial函数,Ackerman函数,Fibnocci函数等。 ⑵ 数据结构是递归的;例如,单链表结构,每个结点 的next域指向的仍然是单链表的结点。我们后面将要 学习的二叉树、广义表等数据结构,它们的定义就是 递归的(具有固有的递归特性)因此自然采用递归方 法进行处理。
⑶ 问题的解法是递归的。 例如,汉诺塔(Tower of Hanoi)问题传说婆罗门庙 里有一个塔台,台上有三根标号为A,B,C的用钻石 做成的柱子,在A柱上放着64个金盘,每一个都比 下面的略小一些。把A柱上的金盘全部移到C柱上的 那一天就是世界末日。移动的条件是:一次只能移 动一个金盘,移动过程中大金盘不能放在小金盘上 面。庙里的僧人一直在移个不停。因为全部的移动 是264 -1次,如果移动一次需要一秒的话,需要500 亿年。
用递归方法求解问题是将一个较复杂的(规 模较大)的问题转换成一个与原问题同类型 的稍简单(规模稍小)的问题来解决,使之 比原问题进了一步(更靠近边界条件一步), 直至到达边界条件(直接求解,不再递归)。
3.3.2 递归子程序的实现 要理解递归算法,就必须了解计算机内递归是如何实现的?我们通过例子说明之。 【例3.3】汉诺塔问题:设需移动的金盘数为n(问题的规模),当n=1时,只要将编号为1的金盘从柱A直接移至柱C即可;当n>1时,需利用柱B作辅助柱子。
算法思路:若能设法将压在编号为n的金盘之上的n-1个金盘从柱A依照上述法则移至柱B;则可先将编号为n的金盘从柱A移至柱C,然后再将柱B上的n-1个金盘依照上述法则移至柱C。而如何将n-1个金盘从一个柱移至另一个柱的问题是一个和原问题具有相同特征属性的问题,只是问题的规模小了1;因此可以用同样的方法求解。算法思路:若能设法将压在编号为n的金盘之上的n-1个金盘从柱A依照上述法则移至柱B;则可先将编号为n的金盘从柱A移至柱C,然后再将柱B上的n-1个金盘依照上述法则移至柱C。而如何将n-1个金盘从一个柱移至另一个柱的问题是一个和原问题具有相同特征属性的问题,只是问题的规模小了1;因此可以用同样的方法求解。
void Hanoi(int n, char A, char B, char C) { if(n= =1) cout<<”move disk 1: “<<A<<”→”<<C; // 将1号盘从A移到C else { Hanoi(n-1,A,C,B); // 将A上编号为1~n-1的盘移至B上, C 用作过渡 cout<<”move disk “<<n<<“: “<<A<<“→“<<C; // 将n号盘从A移到C Hanoi (n-1,B,A,C); // 将B上编号为1~n-1的盘移至C上, A 用作过渡 } }
图 3.8显示了问题规模n=4时Hanoi塔问题的调用过程
显然,递归算法Hanoi在执行过程中,需多次调 用它本身。那末,递归子程序是如何执行的呢? 和汇编程序设计中主程序和子程序之间的链 接和信息交换相类似,在高级语言编制的程 序中,主调程序和被调子程序之间的链接和 信息交换也须通过栈来进行。
通常,当程序在运行期间调用另一个程序时,在运行通常,当程序在运行期间调用另一个程序时,在运行 被调程序之前,系统必须完成3件工作: ① 将所有的实在参数、返回地址等信息传递 给被调子程序保存; ② 为被调子程序的局部变量分配存储区; ③ 将控制转移到被调子程序的入口。
而从被调子程序返回主调程序之前,系统也应完成而从被调子程序返回主调程序之前,系统也应完成 3件工作: ① 保存被调子程序的计算结果: ② 释放被调子程序的数据区; ③ 恢复被调子程序保存的返回地址将控制转 回到主调程序。 当有多个程序间构成嵌套调用时,按照“后调用先返 回”的原则。
上述程序之间的信息传递和控制转移必须通过“栈”上述程序之间的信息传递和控制转移必须通过“栈” 来实现; 即系统将整个程序运行时所需的数据空间安排在一 个栈中。每当调用一个程序时,就为它在栈顶分配 一个存储区;每当退出一个程序时,就释放它的存 储区;则当前正运行程序的数据区必然在栈顶。 递归程序的运行子程序类似于例3.1中多个程序的嵌 套调用;只是主调程序和被调子程序是同一个程序而 已。
3.3.3 递归技术相关问题 ⒈ 递归与分治法 任何一个可用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可,…。而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。 分治法的思想:将一个难以直接解决的大问题,分割成 一些规模较小的相同问题,以便各个击破,分而治之。
如果原问题可分割成k个子问题(1<k≤n),且这些子问题都可解,并可利用这些子问题的解求出原问题的解,那么分治法就是可行的。如果原问题可分割成k个子问题(1<k≤n),且这些子问题都可解,并可利用这些子问题的解求出原问题的解,那么分治法就是可行的。 由分治法产生的子问题往往是原问题的较小模式, 这就为使用递归技术提供了方便。在这种情况下,反 复应用分治手段,可以使子问题与原问题类型一致而 其规模却不断缩小,最终使子问题缩小到很容易直接 求出其解。这自然导致递归过程的产生。分治与递归 像一对孪生兄弟,经常同时应用在算法设计之中,并 由此产生许多高效算法。
⒉ 递归与迭代 递归与迭代都是基于程序设计语言的控制结构,迭代用重复结构,递归用选择结构。 例如,求解阶乘函数的递归算法如下: long Factorial (long n) { if(n==0) return 1; else return n*Factorial(n-1); }
迭代算法如下: long Factorial (long n) { long i , p = 1; for (i=2; i<=n; i ++) p*=i; return p ; } 任何能用递归解决的问题也能用迭代方法解决。