Download

1 / 11
180 likes | 421 Views
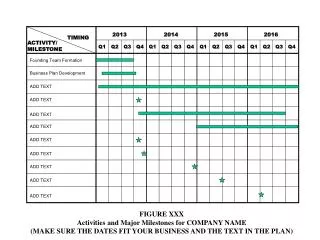
Text Operations: Preprocessing. Introduction. Document preprocessing to improve the precision of documents retrieved lexical analysis, stopwords elimination, stemming, index term selection, thesauri build a thesaurus. Document Preprocessing. Lexical analysis of the text

E N D
Introduction • Document preprocessing • to improve the precision of documents retrieved • lexical analysis, stopwords elimination, stemming, index term selection, thesauri • build a thesaurus
Document Preprocessing • Lexical analysis of the text • digits, hyphens, punctuation marks, the case of letters • Elimination of stopwords • filtering out the useless words for retrieval purposes • Stemming • dealing with the syntactic variations of query terms • Index terms selection • determining the terms to be used as index terms • Thesauri • the expansion of the original query with related term
structure Full text Index terms The Process of Preprocessing Lexicalanalysis Noun groups Manual indexing Docs stopwords stemming structure
Lexical Analysis of the Text • Four particular cases Numbers • usually not good index terms because of their vagueness • need some advanced lexical analysis procedure • ex) 510B.C. , 4105-1201-2310-2213, 12/2/2000, …. Hyphens • breaking up hyphenated words might be useful • ex) state-of-the-art state of the art (Good!) • but, B-1 B 1 (???) • need to adopt a general rule and to specify exceptions on a case by case basis
Lexical Analysis of the Text • Punctuation marks • removed entirely • ex) 510B.C 510BC • if the query contains ‘510B.C’, removal of the dot both in query term and in the documents will not affect retrieval performance • require the preparation of a list of exceptions • ex) val.id valid (???) • The case of letters • converts all the text to either lower or upper case • part of the semantics might be lost • Northwestern University northwestern university (???)
Elimination of Stopwords • Basic concept • filtering out words with very low discrimination values • ex) a, the, this, that, where, when, …. • Advantage • reduce the size of the indexing structure considerably • Disadvantage • might reduce recall as well • ex) “to be or not to be”
Stemming • What is the “stem”? • the portion of a word which is left after the removal of its affixes (i.e., prefixes and suffixes) • ex) ‘connect’ is the stem for the variants ‘connected’, ‘connecting’, ‘connection’, ‘connections’ • Effect of stemming • reduce variants of the same root to a common concept • reduce the size of the indexing structure • controversy about the benefits of stemming
Index Term Selection • Index terms selection • not all words are equally significant for representing the semantics of a document Manual selection • selection of index terms is usually done by specialist Automatic selection of index terms • most of the semantics is carried by the noun words • clustering nouns which appear nearby in the text into a single indexing component (or concept) • ex) computer science
Thesauri • What is the “thesaurus”? • list of important words in a given domain of knowledge • a set of related words derived from a synonymity relationship • a controlled vocabularyfor the indexing and searching • Main purposes • provide a standard vocabulary for indexing and searching • assist users with locating terms for proper query formulation • provide classified hierarchies that allow the broadening and narrowing of the current query request
Thesauri • Thesaurus index terms • denote a concept which is the basic semantic unit • can be individual words, groups of words, or phrases • ex) building, teaching, ballistic missiles, body temperature • frequently, it is necessary to complement a thesaurus entry with a definition or an explanation • ex) seal (marine animals), seal (documents) • Thesaurus term relationships • mostly composed of synonyms and near-synonyms • BT (Broader Term), NT (Narrower Term), RT (Related Term)