Download

1 / 9
90 likes | 250 Views
ECE 4110–5110 Digital System Design. Lecture #32 Agenda Improvements to the von Neumann Stored Program Computer Announcements N/A. von Neumann Computer.

E N D
ECE 4110–5110 Digital System Design Lecture #32 • Agenda • Improvements to the von Neumann Stored Program Computer • Announcements • N/A
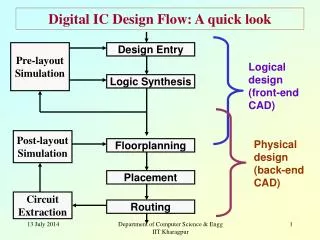
von Neumann Computer • Bottleneck- we have seen that the von Neumann computer is serial in its execution of instructions- this is good for simplicity, but can limit performance- there are many techniques to improve the performance of this computer 1) Functional Timing 2) Memory Architecture 3) Algorithmic Branch Prediction 4) Pipelines
von Neumann Improvements • 1-Functional Timing- the simplest implementation of the von Neumann has each control signal asserted in one state, but the register transfer not occurring until the next state.- this is due to the timing of the Flip-Flops and Registers A B D Q D Q B doesn’t see the LOAD signal and Valid Data until the subsequent Clock Edge CLK tCQ tcomb CLK (from controller) LOAD AQ A(0) A(1) BQ A(0)
von Neumann Improvements • Functional Timing- a delay (or phase) can be added to the clock that the B-register sees. This creates a single-shot structure which executes in 1 cycle A B D Q D Q CLK tphase CLKA tphase CLKB (from controller) LOAD AQ A(0) A(1) tCQ BQ A(0) tCQ
von Neumann Improvements • Functional Timing- this allows multiple register transfers in one clock cycleex) Clock 1 : MAR <= PC Clock 2 : IR <= MAR PC <= PC + 1- it still takes two clock edges, but due to phasing, these edges occur within one system clock cycle- note that control signals going to the phased block need to be phased also: - IR_Load - PC_Inc - the phase timing needs to wait long enough for combinational logic signals to propagate and for Register delays (Setup/Hold/tCQ)
von Neumann Improvements • 2-Memory Architecture- the main bottleneck is trying to get Opcodes, Operands, and Data out of memory- memory systems run slower than CPU’s so access needs to be slowed to accommodate the memory technology (i.e., DRAM = Capacitors)- Cache memory is a technique to improve the speed of memory access- Cache is smaller, faster, SRAM that is placed on the same chip as the CPU.- Cache improves performance based on two assumptions: 1) Code Blocks tend to be executed more than once (i.e, loops) 2) The overhead of accessing slow memory one word at a time is reduced by pulling large blocks of memory out at once - Latency = the timing overhead associated with accessing memory
von Neumann Improvements • 3-Algorithmic Branch Predicting- algorithms can be developed to “predict” a potential branch- this would allow the memory controller to load up a portion of Cache with the code that could be potentially executed if the branch was taken ex) Loop: DECX BEQ Loop BRA Compute - The code for “Loop” is loaded into Cache because it will probably be executed more than once - the code residing at “Compute” will be executed (once the loop ends), so it is loaded into an unused portion of Cache in parallel to the execution of “Loop”
von Neumann Improvements • Multi-Level Cache- Multiple levels of cache can be used to try to reduce memory access time even further - L1 (Level 1) cache – smallest and fastest - L2 (Level 2) cache - a little larger and a little slower than L1 - but still faster than DRAM- the CPU will always try to execute out of the fastest RAM- the CPU will 1) check whether the code to be executed is in L1 cache 2) if not, check whether the code is in L2 cache 3) if not, the memory controller will load L1 with the code from DRAM- NOTE: cache will have both Instruction and Data storage
von Neumann Improvements • 4-Pipelining Wash 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 Non-pipelined Pipelined Dry 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 non-pipelined dish cleaning Time pipelined dish cleaning Time Fetch-instr. 1 2 3 4 5 6 7 8 Decode 1 2 3 4 5 6 7 8 Fetch ops. 1 2 3 4 5 6 7 8 Pipelined Execute 1 2 3 4 5 6 7 8 Instruction 1 Store res. 1 2 3 4 5 6 7 8 Time pipelined instruction execution