Download
1 / 47
470 likes | 930 Views
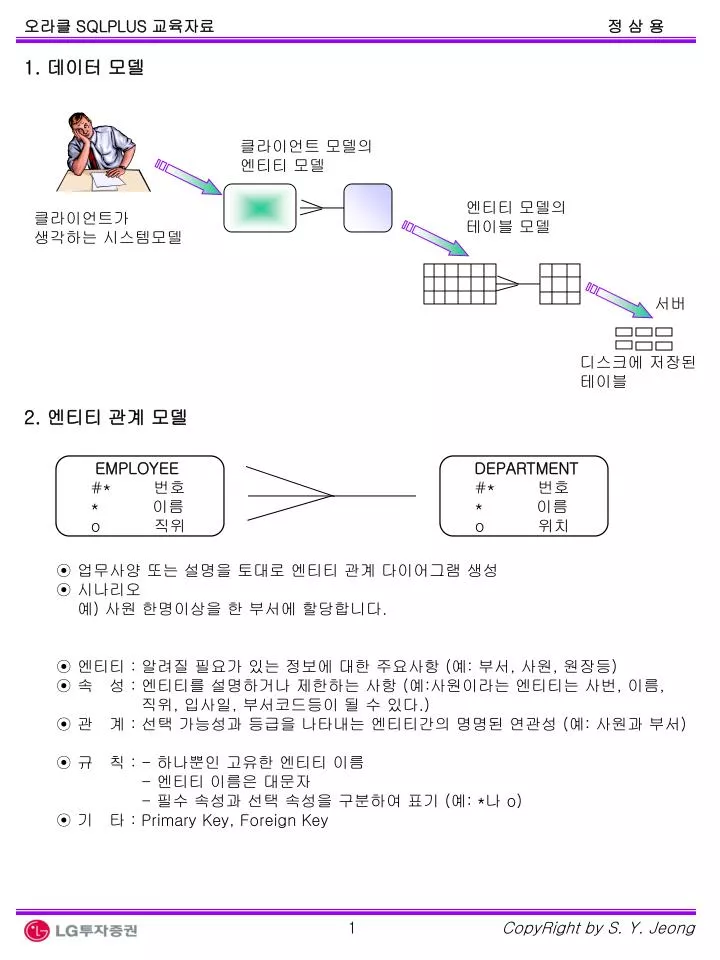
1. 데이터 모델. 클라이언트 모델의 엔티티 모델. 엔티티 모델의 테이블 모델. 클라이언트가 생각하는 시스템모델. 서버. 디스크에 저장된 테이블. 2. 엔티티 관계 모델. EMPLOYEE #* 번호 * 이름 o 직위. DEPARTMENT #* 번호 * 이름 o 위치. ⊙ 업무사양 또는 설명을 토대로 엔티티 관계 다이어그램 생성 ⊙ 시나리오

E N D
1. 데이터 모델 클라이언트 모델의 엔티티 모델 엔티티 모델의 테이블 모델 클라이언트가 생각하는 시스템모델 서버 디스크에 저장된 테이블 2. 엔티티 관계 모델 EMPLOYEE #* 번호 * 이름 o 직위 DEPARTMENT #* 번호 * 이름 o 위치 ⊙ 업무사양 또는 설명을 토대로 엔티티 관계 다이어그램 생성 ⊙ 시나리오 예) 사원 한명이상을 한 부서에 할당합니다. ⊙ 엔티티 : 알려질 필요가 있는 정보에 대한 주요사항 (예: 부서, 사원, 원장등) ⊙ 속 성 : 엔티티를 설명하거나 제한하는 사항 (예:사원이라는 엔티티는 사번, 이름, 직위, 입사일, 부서코드등이 될 수 있다.) ⊙ 관 계 : 선택 가능성과 등급을 나타내는 엔티티간의 명명된 연관성 (예: 사원과 부서) ⊙ 규 칙 : - 하나뿐인 고유한 엔티티 이름 - 엔티티 이름은 대문자 - 필수 속성과 선택 속성을 구분하여 표기 (예: *나 o) ⊙ 기 타 : Primary Key, Foreign Key
SELECT 데이터 검색 INSERT UPDATE DML(데이터 조작어) DELETE CREATE ALTER DROP DDL(데이터 정의어) RENAME TRUNCATE COMMIT ROLLBACK TCL(트랜잭션 제어) SAVEPOINT GRANT REVOKE DCL(데이터 제어) 3. SQL 문 ▣ 기본 SELECT 문 SELECT [DISTINCT] {*, column [alias], …..} FROM table ; ▣ SQL 문 작성 ▪ SQL문은 대소문자 구분안함 ▪ SQL문은 하나이상의 행에 입력할 수 있다. ▪ 키워드(예약어)는 약어로 쓰거나 다음행에 나눠쓸 수 없다. ▪ 절은 일반적으로 서로 다른 행에 쓴다. ▪ 탭과 들여쓰기를 사용하면 좀 더 읽기 쉬운 코드를 작성할 수 있다. ▣ SQL문 실행 ▪ 마지막 절의 끝에 세미콜론(;)을 입력한다. ▪ 버퍼의 마지막 행에 슬래시(/)를 입력한다. ▪ SQL 프롬프트에 슬래시(/)를 입력한다. ▪ SQL 프롬프트에서 SQL*Plus RUN 명령을 실행한다. ▣ 모든 열 선택 SELECT * FROM dept;
▣ 특정 열 선택 SELECT deptno, dept_name FROM dept ; ▣ 열 머리글 기본값 ▪ 기본 맞춤 - 왼 쪽 : 날짜 및 문자 데이터 - 오른쪽 : 숫자 데이터 ▪ 기본표시 : 대문자 ▣ 산술식 ▪ SQL문에서는 FROM 절을 제외한 모든 절에서 산술연산자를 사용할 수 있다. ▪ 연산자 : *, /, +, - SELECT ename, gikgub, sal, (sal + 1000) * 10 FROM emp WHERE sal > gikgub * 10000 ; ▣ 널(NULL) 값 정의 ▪ NULL 값은 알 수 없는 값으로서 사용, 할당 및 작용 불가. ▪ NULL은 0 또는 공백(SPACE)와 다름. ▣ 산술식의 널 값 ▪ NULL 값의 산술식은 NULL 값 ▣ 열 별칭 정의 (ALIAS) ▪ 열 머리글 이름 변경 ▪ 계산시 유용 ▪ 열 이름 바로 다음에 AS 키워드 사용 ▪ 공백 또는 특수문자가 있거나 대소문자 구분시 큰 따옴표 사용 SELECT ename AS name, sal salary FROM emp ; ▣ 연결 연산자 ▪ 열 또는 문자열 연결 ▪ 두개의 세로선(||)으로 연결 ▪ 문자식인 결과 열을 생성합니다. SELECT ename || job as employee FROM emp; ▣ 리터럴 문자열 ▪ 리터럴은 SELECT 목록에 포함된 문자, 숫자 또는 날짜임 ▪ 날짜 및 문자 리터럴 값은 작은 따옴표 사용 ▪ 각 문자열은 각 행이 반환될 때마다 한번 출력됨 SELECT ename || ‘ is a ‘ || job FROM emp ; ▣ 중복행 제거 SELECT 절에서 DISTINCT 키워드를 사용하여 중복행 제거 SELECT DISTINCT deptno FROM emp;
▣ SQL*PLUS ▪ SQL*PLUS LOGIN ▪ TABLE 구조 표시 ▪ SQL문 편집 ▪ SQL*PLUS에서 SQL을 실행 ▪ 저장한 파일 실행 ▪ 파일에서 버퍼로 명령을 로드하여 편집 ▣ TABLE 구조표시 ▪ DESC tablename ▪ DATA TYPE ▣ SQL*PLUS 편집 명령 ▪ A[PPEND] text : text를 현재 행의 끝에 추가 ▪ C[HANGE] /old/new : 현재 행에서 old 텍스트를 new로 바꿈(공백없이) ▪ C[HANGE] / text / : 현재 행에서 text를 삭제 ▪ CL[EAR] BUFF[ER] : SQL 버퍼에서 모든 행을 삭제 ▪ DEL : 현재 행 삭제 ▪ DEL n : n 행 삭제 ▪ DEL m n : m 행부터 n행까지 삭제 ▪ I[NPUT] : 행 수에 제한없이 삽입 ▪ I[NPUT] text : 현 행 다음에 text를 구성하는 한 행을 삽입 ▪ L[IST] : SQL 버퍼의 모든 행을 나열 ▪ L[IST] n : 한 행을 나열 ▪ L[IST] m n : 행의 범위 나열 ▪ R[UN] : 버퍼의 현재 SQL문을 나열하고 실행 ▪ n : 현재 행으로 만들 행 지정 ▪ n text : n 행을 text로 바꿈 ▪ 0 text : 1행 앞에 한 행 삽입 ▪ 현재 행 끝에 하이픈(-)을 입력하여 다음행에 계속 ▣ SQL*Plus 파일 명령 ▪ SAV[E] filename : SQL버퍼의 현재 내용을 파일에 저장. APPEND / REPLACE ▪ GET filename : 저장한 파일 내용을 버퍼에 Load ▪ STA[RT] filename : 이전에 저장한 파일 실행 ▪ @ filename : START와 동일 ▪ ED[IT] : 편집기를 호출하여 afiedt.buf라는 파일에 버퍼내용 저장 ▪ ED[IT] [filename] : 편집기를 호출하여 저장된 파일의 내용을 편집 ▪ SPO[OL] [filename | OFF | OUT] : 질의 결과를 파일에 저장. OFF는 스풀파일을 닫고 OUT은 스풀파일 닫은 후 파일결과를 Print. NUMBER(p,s) 최대자릿수 p 소수점 s째 자리까지 표기하는 숫자값 VARCHAR2(s) 최대 크기가 s인 가변 길이 문자 값 DATE 날짜 및 시간 값 CHAR(s) 크기가 s인 고정길이 문자 값
4. 데이터 제한 및 정렬 ▣ WHERE 절 사용 ▪ FROM 절 다음에 기술 ▣ 문자열 및 날짜 ▪ 문자열 및 날짜값은 작은 따옴표 사용 ▪ 문자 값은 대소문자를 구분하며 날짜 값은 형식을 구분 ▪ 기본 날짜 형식은 DD-MON-YY ▣ 비교 연산자 ▪ =, >, >=, <, <=, <> ▪ BETWEEN ~ AND ~ , IN(list), LIKE, IS NULL ▪ IN은 OR 조건과 같다 (단지 Logic을 간단하게 표현) ▪ LIKE 연산자는 “%”또는 “_”를 사용 (대소문자 구분) ▪ ‘_’를 문자열로 인식하고 싶을때 ‘_’앞에 역 슬래쉬 사용 ▪ AND, OR, NOT 연산자 ( NOT IN, NOT BETWEEN ~ , NOT LIKE, IS NOT NULL ) SELECT emp_no, emp_name, salary FROM emp_table WHERE dept in (‘4620’,’4718’) AND salary BETWEEN 1000 AND 1500 AND emp_name LIKE ‘정%’ AND penalty IS NULL ; ▪ 연산자 우선순위 ( 모든 비교연산자, NOT, AND, OR ) 예제 1) SELECT ename, job, sal FROM emp WHERE job = ‘SALEMAN’ OR job = ‘PRESIDENT’ AND sal > 1500 ; 예제 2) SELECT ename, job, sal FROM emp WHERE (job = ‘SALEMAN’ OR job = ‘PRESIDENT’) AND sal > 1500 ; 해설 : 예제 1은 우선순위에 의해 PRESIDENT 이면서 봉급이 1500보다 크거나 SALEMAN인 데이타 1. 비교 연산자 봉금 1500 보다 큰 조건 실행 2. AND 연산자 PRESIDENT 실행 3. OR 조건 SALEMAN 실행 예제 2는 SALEMAN이거나 PRESIDENT 이면서 봉급이 1500보다 큰 데이타
▣ ORDER BY 절 ▪ ASC : 오름차순, 기본값 ▪ DESC : 내림차순 ▪ ORDER BY 절은 SELECT문의 가장 끝에 위치 ▪ Let the students know that you can also sort by a column number in the SELECT list. SELECT ename, sal FROM emp ORDER BY sal desc ; => ORDER BY 2 DESC ; ▪ Alias 명으로 정렬 가능 ▪ 여러 컬럼이 정렬될때 OREDR BY 절에 기술한 순서로 정렬됨 5. 단일행 함수 ▣ 문자 함수 ▪ LOWER : 알파벳 값을 소문자로 변환 ▪ UPPER : 알파벳 값을 대문자로 변환 ▪ INITCAP : 알파벳 값의 첫 문자를 대문자로 변환 ▪ CONCAT : 첫번째 문자 값을 두번째 문자값과 연결 ( = CONCAT ) ▪ SUBSTR : 문자 값의 위치 m에서 n까지 지정된 문자를 반환(m < 0면 문자 끝에서부터) ▪ LENGTH : 값의 문자수 반환 ▪ INSTR : 명명된 문자의 위치를 반환 ▪ LPAD : 전체 길이가 n인 문자열 값을 오른쪽 정렬하고 나머지 공간은 선택한 문자로 채운다. ( RPAD ) ▪ TRIM : 문자열에서 머리글이나 꼬리말 또는 모두 자를 수 있다. SELECT ename, concat(ename, job), length(ename), instr(ename, ‘A’) FROM emp WHERE substr(job, 1, 5) = ‘SALES’ ;
▣ 숫자 함수 ▪ ROUND : 지정한 소수점 자리로 값을 반올림. ROUND(45.926, 2) => 45.93 ▪ TRUNC : 지정한 소수점 자리까지 남기고 값을 버림. TRUNC(45.926, 2) => 45.92 ▪ MOD : 나눗셈의 나머지 반환. MOD(1600, 300) => 100 ▣ 날짜 사용 ▪ SYSDATE : 날짜와 시간을 반환하는 함수 ▪ DUAL : Dummy Table ▪ 날짜 계산에 산술식 사용 가능 ▪ MONTHS_BETWEEN : 두 날짜간의 달 수 ▪ ADD_MONTHS : 날짜에 달 수 더하기 ▪ NEXT_DAY : 지정한 날짜의 다음 날 ▪ LAST_DAY : 해당 달의 마지막 날 ▪ ROUND : 날짜 반올림 ▪ TRUNC : 날짜 버림 ▣ 암시적 데이터 유형 변환 ▪ 할당문에 사용되는 값의 데이터 유형을 할당 대상의 데이터 유형으로 변환 ▪ VARCHAR2 또는 CHAR => NUMBER ▪ VARCHAR2 또는 CHAR => DATE ▪ NUMBER => VARCHAR2 ▪ DATE => VARCHAR2
▣ 명시적 데이터 유형 변환 ▪ TO_CHAR(date, ‘format’) YYYY : 네자리년도, YEAR : 년도(문자), MM : 두자리 값으로 나타낸 달 MONTH : 달 전체이름(문자), DY : 영문요일(세자약어), DAY : 요일 전체 이름 HH24:MI:SS AM => 15:45:32 PM, DD “of” MONTH => 12 of OCTOBER ddspth : 일자를 문자로 표기 => fourteenth ▪ TO_CHAR(number, ‘fmt’) 9 : 숫자를 표시 0: 0를 강제로 표시 $ : 부동$ 기호를 넣습니다 L : 부동 지역 통화기호를 사용 . : 소수점 출력 , : 천단위 구분자 사용 MI : 오른쪽에 음수표시 PR : 음수를 괄호로 표시 B : 0 값대신 공백으로 표시 ▣ NVL 함수 ▪ NVL(comm, 0) ▪ NVL(hiredate, ‘19990101’) ▪ NVL(name, ‘jsy’) ▪ 산술 연산시 NULL 값의 계산은 NULL로 나오기 때문에 반드시 숫자로 변환 ▣ DECODE 함수 ▪ CASE 또는 IF-THEN-ELSE 문의 역할 SELECT name, sal, DECODE(TRUNC(sal/1000, 0), 0, 0.00, 1, 0.09, 2, 0.20, 3, 0.30, 0.40) TAX_RATE FROM emp ;
6. 여러 테이블의 데이터 표시 ▣ 조인(JOIN) 이란 ▪ 여러 테이블의 데이터를 질의합니다. ▪ WHERE 절에서 조인 조건을 작성 ▪ 동일한 열 이름이 여러 테이블에 있는 경우 열 이름에 테이블 이름 사용 ▣ 카티시안 곱 ▪ 생성 조건 : 1. 조인조건 생략시 2. 조인 조건이 부적합한 경우 3. 첫번째 테이블의 모든 행이 두번째 테이블의 모든 행에 조인된 경우 ▣ 조인유형 ▪ 등가조인 : 기본키와 외래키(foreign 키)의 조인. 확실히 식별 가능 ▪ 비등가조인 : BETWEEN이나 <=, >= 를 사용하여 검색. 데이터는 중복되어 SELECT 안됨 ▪ 포괄조인(OUTJOIN) : 1. 포괄 조인 연산자는 더하기 기호 (+) 2. 정보가 부족한 테이블에 (+) 를 부친다. 3. OUTJOIN을 포함하는 조건은 IN 연산자를 사용할 수 없다. ▪ 자체조인 : 자기 테이블 끼리 조인. 7. 그룹함수를 사용한 집계 ▣ 그룹함수의 종류 ▪ AVG : 값의 평균이며 널 값은 무시. 널 행수 포함 평균 계산시 NVL함수 사용 ▪ COUNT : 행 수. COUTN(*) -> 널 값 포함, COUNT( [DISTINCT] column_name) -> null 값은 무시함[중복무시] ▪ MAX : 컬럼의 최대값 ▪ MIN : 컬럼의 최소값 ▪ STDDEV : 표준편차 ▪ SUM : 컬럼의 합계값이며 널 값 무시 ▪ VARIANCE : 분산이며 널 값 무시 SELECT AVG(nvl(sal, 0)) SELECT COUNT(DISTINCT e_name) SELECT MAX(sal) SELECT STDDEV(sal) SELECT VARIANCE(sal)
▣ 데이터 그룹 생성 ▪ GROUP BY 절 사용 ▪ 그룹함수외에 다른 컬럼 SELECT 시 반드시 GROUP BY 절 사용해야함. ▪ GROUP BY 열을 SELECT 목록에 포함시키지 않아도 됨 SELECT AVG(sal) FROM emp GROUP BY deptno ; ▪ WHERE 절을 사용하여 그룹을 제한할 수 없음. 오류) SELECT deptno, avg(sal) FROM emp WHERE avg(sal) > 2000 groupby deptno; 정정) select deptno, avg(sal) from emp group by deptno having avg(sal) > 2000 ; ▪ HAVING 절 사용하여 GROUP BY 절을 제외시킬 수 있음 SELECT job, sum(sal) FROM emp WHERE job NOT LIKE ‘sales%’ GROUP BY job HAVING sum(sal) > 5000 ORDER BY SUM(sal) ; 8. 하위 질의 ▣ 하위 질의 사용 지침 ▪ 하위 질의를 괄호로 묶는다 ▪ 비교 연산자의 오른쪽에 하위 질의를 넣는다 ▪ 하위 질의에는 ORDER BY 절을 추가하지 마십시오. 하나의 SELECT문에는 하나의 ORDER BY 절을 사용할 수 있음. ▪ 단일 행 하위질의에는 단일행 연산자를 사용한다. ▪ 여러 행 하위 질의에는 여러 행 연산자를 사용한다. ▣ 하위 질의 유형 ▪ WHERE절이나 HAVING절에 조건으로 SUBQUERY사용. ▪ 비교 연산자 사용시 SUB QUERY에서 RETURN하는 값이 단일값이여야 함. SELECT deptno, MIN(sal) FROM emp GROUP BY deptno HAVING MIN(sal) > ( SELECT MIN(sal) FROM emp WHERE deptno = 20 ) ;
▣ 여러 행의 하위질의 ▪ 여러 행을 반환 ▪ 여러 행 비교 연산자 사용 ▪ IN SELECT ename, sal, deptno FROM emp WHERE sal IN ( SELECT MIN(sal) FROM emp GROUP BY deptno ) ; ▪ ANY SELECT empno, ename, job FROM emp WHERE sal < ANY ( SELECT sal FROM emp WHERE job = ‘CLERK’) AND job <> ‘CLERK’ ; 하위질의 값이 950, 800, 1300 일때 이 쿼리는 1300 보다 적은 사무원이 아닌 사원표시. - < ANY 는 최대값보다 적음. > ANY 는 최소값보다 큼. = ANY는IN과 동일. ▪ ALL < ALL 은 최소값보다 적음. > ALL 는 최대값보다 큼. ▣ 여러 열 하위 질의 사용 ▪ 쌍 비교 SELECT ordid, prodid, qty FROM item WHERE (prodid, qty) IN ( SELECT prodid, qty FROM item WHERE ordid = 605 ) AND ordid <> 605 ; ▪ 비쌍 비교 SELECT ordid, prodid, qty FROM item WHERE prodid IN ( SELECT prodid FROM item WHERE ordid = 605 ) AND qty IN ( SELECT qty FROM item WHERE ordid = 605) AND ordid <> 605 ;
9. 출력관련 ▣ & 치환변수 ▪ 앰퍼샌드(&)가 접두어로 붙은 변수를 사용하여 사용자에게 값을 묻습니다. SELECT empno, ename FROM emp WHERE empno = &employee_num ; ▪ SET VERIFY 명령 사용 : SQL*PLUS 가 치환변수를 값으로 바꾸기 전후의 명령 텍스트 표시를 토글 SQL> select * 2 from bdjmst 3 where jmcode = ‘&in_jmcode’ ; Enter value for in_jmcode: kkk old 3: where jmcode = &in_jmcode new 3: where jmcode = 'kkk' ▪ 치환변수의 타입이 스트링시 작은 따옴표로 묶어야 하며 UPPER와 LOWER와 같은 함수도 사용 가능. 예) UPPER(‘&job_title’) ▪ 치환 변수에 사용할 수 있는 항목 - WHERE 조건 - ORDER BY 절 - 열 표현식 - 테이블 이름 - 전체 SELECT 문 SQL> select jmcode, s_jmname 2 from &table 3 where &conditon 4 order by &order_column SQL> / Enter value for table: bdjmst old 2: from &table new 2: from bdjmst Enter value for conditon: jmcode = 'kkk' old 3: where &conditon new 3: where jmcode = 'kkk' Enter value for order_column: jmcode old 4: order by &order_column new 4: order by jmcode
▣ && 치환변수 사용 ▪ 같은 변수 값을 사용하고자 할때 한번만 입력하고 나머지는 재 사용할때 사용 SELECT jmcode, &&column FROM bdjmst ORDER BY &column ; 단, WHERE 조건에 &를 사용하고 SELECT 문에는 &&를 사용한다. ▣ 사용자 변수 정의 ▪ DEFINE : CHAR 데이터 유형의 사용자 변수 생성 ▪ ACCEPT : 사용자 입력 내용을 읽어 변수로 저장 ▪ 공백을 포함하는 변수를 미리 정의하려면 DEFINE 명령을 사용할때 그 값을 작은 따옴표로 묶어야 한다. ▣ ACCEPT 명령 ▪ 사용자 입력을 받아 들일 때 사용자가 정의하는 프롬프트를 생성 ▪ NUMBER 또는 DATE 데이터 유형의 변수를 명시적으로 정의 ▪ 보안상의 이유로 사용자 입력을 숨김 ▪ ACCEPT variable [datatype] [FORMAT format] [PROMPT text] [HIDE] SQL> accept in_order prompt 'sorted column: ' sorted column: s_jmname SQL> select jmcode, s_jmname 2 from bdjmst 3 where rownum <= 10 4 order by &in_order SQL> / JMCODE S_JMNAME ------------ ------------------ KR3201014K10 국민카드426 ▣ DEFINE 및 UNDEFINE 명령 ▪ 정의된 변수는 다음과 같은 경우에 손실됨 - UNDEFINE 명령을 사용하여 변수를 지운 경우 - SQL*Plus 를 종료한 경우 ▪ DEFINE 명령으로 변경내용을 확인할 수 있습니다. ▪ 모든 세션에 대해 변수를 정의하려면 시작 시 변수가 생성되도록 login.sql 파일을 수정하십시요 ▣ DEFINE 명령 사용 SQL> define in_order = s_jmname SQL> select jmcode, s_jmname 2 from bdjmst 3 where rownum <= 10 4 order by &in_order 5 / old 4: order by &in_order new 4: order by s_jmname ……… 10 rows selected.
▣ DEFINE 명령으로 변경된 내용 확인 SQL> define in_order DEFINE IN_ORDER = "s_jmname" (CHAR) ▣ 사용자가 SQL*Plus 환경 정의 ▪ SET 명령을 사용하여 현재 SESSION 제어 SET system_variable value ▪ SHOW 명령을 사용하여 설정한 내용을 확인 SQL> show echo ▪ SET 명령변수 ▣ 사용자가 정의한 내용을 login.sql 파일에 저장 ▪ login.sql 파일은 로그인 시 구현되는 표준 SET 및 기타 SQL*Plus 명령을 포함합니다. ▪ login.sql 을 수정하여 추가 SET 명령을 포함할 수 있습니다. ▣ COLUMN 명령 ▪ 형식 : COL[UMN] [ {column|alias} [option] ] ▪ 옵션 - CLE[AR] : 열 형식을 지움 - FOR[MAT] format : 형식 모델을 사용하여 열 표시를 변경함 - HEA[DING] text : 열 머리글을 설정 - JUS[TIFY] {align} : 열 머리글 왼쪽, 가운데 또는 오른쪽 정렬 - NOPRI[NT] : 열을 숨김 - NUL[L] text : 널 값으로 표시되는 텍스트를 지정함 - PRI[NT] : 열을 표시 - TRU[NCATE] : 첫 행 끝에 표시되는 문자열을 잘라 버림 - WRA[PPEND] : 문자열의 끝을 다음 행으로 줄바꿈함
▣ BREAK 명령 사용 ▪ BREAK ON column [|alias|row] [skip n|dup|page] ON .. [ON report] page : 구분 값이 변경될 때 새 페이지로 구분 skip n : 구분 값이 변경될 때 n 개 행을 건너뜀 dup : 중복 값을 표시 ▪ 중복을 제거하고 행을 구분 SQL> BREAK ON ename ON job ▪ 구분 값을 기준으로 행을 구분 SQL> BREAK ON ename SKIP 4 ON job SKIP 2 ▪ CLEAR 명령을 사용하여 모든 BREAK 설정을 지움 SQL> CLEAR BREAK ▣ TTITLE 및 BTITLE 명령사용 ▪ 머리글과 바닥글을 표시 TTI[TLE] [text|OFF|ON] ▪ 보고서 머리글을 설정합니다. SQL> TTITLE ‘Salary|Report’ : 세로선(|)을 사용하여 제목의 텍스트를 여러 행에 나눠 쓸 수 있음. ▪ 보고서 바닥글을 설정 SQL> BTITLE ‘Confidential’ ▣ 스크립트 파일을 작성하여 보고서 실행 1. SQL SELECT 문을 작성함 : BREAK를 사용하려면 관련 ORDER BY 절을 포함해야 함 2. SELECT 문을 스크립트 파일에 저장함 3. 스크립트 파일을 편집기로 읽어 들임 4. SELECT 문 앞에 형식 명령을 추가함 5. SELECT 문 다음에 종료 문자가 오는지 확인함 ( ; 이나 / 가 옴) 6. SELECT 문 다음에 있는 형식 명령을 지움 7. 변경한 스크립트 파일을 저장 8. SQL*Plus에서 START 파일이름 또는 @파일이름을 입력하여 스크립트 파일을 실행 ▪ REM은 SQL*Plus에서 주 또는 주석을 나타냄
10. 데이터 조작 ▣ 데이터 조작어 ▪ INSERT 문 : 치환 매개변수를 사용하여 대화식 스크립트 가능 (&) : ACCEPT 사용가능 ▪ UPDATE 문 : 여러 열 하위 질의를 사용한 갱신 SQL> UPDATE emp SET (job, deptno) = ( SELECT job, deptno FROM emp WHERE empno = ‘46346’) WHERE job = ( SELECT job FROM emp WHERE empno = ‘46346’ ); ▪ DELETE 문 ▣ 트랜잭션 제어 ▪ COMMIT ▪ SAVEPOINT name : 현재 트랜잭션 내에 저장점을 표시 SQL> UPDATE … SQL> SAVEPOINT update_done ; Savepoint created. SQL> INSERT ….. SQL> ROLLBACK TO update_done ; Rollback complete. ▪ ROLLBACK [TO SAVEPOINT name] : 지정된 저장점으로 롤백 11. 테이블 생성 및 관리 ▣ 데이터베이스 객체 ▪ 테이블 : 기본 저장단위며 행과 열로 구성 ▪ 뷰 : 하나 이상의 테이블에서 데이터 부분집합을 논리적으로 표시 ▪ 시퀀스 : 기본 키 값을 생성 ▪ 인덱스 : 효율적으로 질의할 수 있음 ▪ 동의어 : 객체에 다른 이름을 제공 ▣ 이름 지정 규칙 ▪ 문자로 시작 ▪ 1~30 자까지 가능 ▪ A~Z, a~z, 0~9, _, $, #만 포함해야 합니다. ▪ 동일한 사용자가 소유한 다른 객체의 이름과 중복되지 않아야 함 ▪ Oracle Server의 예약어가 아니어야 합니다. ▣ CREATE TABLE 문 ▪ CREATE TABLE 권한 ▪ 저장 영역이 필요 ▪ 다음을 지정 - 테이블 이름, 열의 이름, 데이터 유형 및 크기
CREATE [GLOBAL temporary] TABLE [schemea.]table (column datatype [DEFAULT expr] [, …..]); - GLOBAL TEMPORARY : 테이블을 임시 테이블로 지정하고 테이블 정의를 모든 세션에서 볼 수 있도록 지정. 임시 테이블의 데이터는 테이블에 데이터를 삽입하는 세션에서만 볼 수 있다. - schema : 소유자 이름과 동일 - table : 테이블 이름 - DEFAULT expr : INSERT 문에서 값을 생략하면 기본값을 지정 - column : 열 이름 - datatype : 열의 데이터 유형 및 길이 ▪ 테이블 생성 확인 SQL> DESCRIBE dept SQL> DESC dept ▣ 오라클 데이터베이스의 테이블 ▪ 사용자 테이블 - 사용자가 생성 및 유지관리하는 테이블의 모음 - 사용자 정보 포함 ▪ 데이터 딕셔너리 - Oracle Server가 생성 및 유지관리하는 테이블의 모음 - 데이터베이스 정보를 포함 - 사용자 이름, 사용자 권한, 데이터베이스 객체이름, 테이블 제약조건, 감사정보 등 포함 ▣ 데이터 딕셔너리 질의 ▪ 사용자가 소유한 개별 객체 유형 SQL> SELECT * FROM user_tables ; ▪ 사용자가 소유한 테이블, 뷰, 동의어 및 시퀀스를 조회 SQL> SELECT DISTINCT object_type FROM user_objects ; ▪ 사용작 소유한 테이블을 설명 SQL> SELECT * FROM user_catalog ;
▣ 데이터 유형 ▣ 하위 질의를 사용한 테이블 생성 ▪ CREATE TABLE 문과 AS subquery 옵션을 결합하여 테이블을 생성하고 행을 삽입 CREATE TABLE table [(column, column, ….)] AS subquery ; ▪ 지정한 열 수를 하위 질의 열 수와 일치 시킴 ▪ 열 이름 및 기본값을 사용하여 열을 정의함 ▣ ALTER TABLE 문 ▪ 새 열 추가 ▪ 새 열의 기본값 정의 ALTER TABLE table ADD (column datatype [DEFAULT expr] [, column datatype] …..); ▪ 기존 열의 데이터 유형, 크기 및 기본 값을 변경 ▪ 기본 값ㅇ르 변경하면 변경 이후에 테이블에 삽입되는 항목에만 영향을 줌 SQL> ALTER TABLE dept30 MODIFY (ename VARCHAR2(15)); ▪ 테이블에서 더 이상 필요하지 않은 열을 한번에 한번씩 삭제 SQL> ALTER TABLE dept30 DROP COLUMN job ;
▣ SET UNUSED 옵션 (Oracle 8. i 에서 사용할 수 있음) ▪ SET UNUSED 옵션을 사용하여 하나 이상의 열을 사용되지 않았음으로 표시 ▪ DROP UNUSED COLUMS 옵션을 사용하여 UNUSED 로 표시된 열을 제거 SQL> ALTER TABLE table SET UNUSED (column) ; 또는 ALTER TABLE table SET UNUSED COLUMN column ; SQL> ALTER TABLE table DROP UNUSED COLUMNS ; ▣ 테이블 삭제 SQL> DROP TABLE dept30 ; ▣ 객체이름 변경 ▪ 테이블, 뷰, 시퀀스 또는 동의어의 이름을 변경하려면 RENAME 문을 실행 SQL> RENAME dept TO department ; ▣ 테이블 절단 ▪ 테이블에서 모든 행을 제거 ▪ 해당 테이블이 사용하는 저장 공간을 해제 ▪ TRUNCATE 를 사용한 행 제거 작업은 롤백할 수 없음 SQL> TRUNCATE TABLE department ; ▣ 테이블에 주석 추가 ▪ COMMENT 문을 사용하여 테이블 또는 열에 주석을 추가할 수 있다 ▪ 주석은 데이터 딕셔너리 뷰를 통해 확인 SQL> COMMENT ON TABLE emp IS ‘Employee Information’ ; - ALL_COL_COMMENTS - USER_COL_COMMENTS - ALL_TAB_COMMENTS - USER_TAB_COMMETS 12. 제약조건 포함 ▪ 제약조건은 테이블 레벨로 규칙을 적용 ▪ 제약조건은 종속된 테이블의 삭제를 방지 ▪ 오라클에서 제공하는 제약조건의 유형 - NOT NULL - UNIQUE - PRIMARY KEY - FOREIGN KEY - CHECK ▣ 제약조건의 지침 ▪ 제약조건에 이름지정하지 않으면 SYS_Cn형식의 이름 자동부여 ▪ 제약조건 생성 시기 : 테이블 생성 시 / 테이블 생성 후 ▪ 열 레벨 또는 테이블 레벨로 제약조건 정의 ▪ 데이터 딕셔너리에 있는 제약 조건 조회 (USER_CONSTRAINTS)
▣ 제약 조건 정의 CREATE TABLE [schema.]table (column datatype [DEFAULT expr] [column_constraint], …… [table_constraint] [, ….]) ; CREATE TABLE emp ( emp_no NUMBER(4), ename VARCHAR2(10), …. deptno NUMBER(2) NOT NULL, CONSTRAINT emp_pk PRIMARY KEY (EMP_NO)); ▣ 제약 조건 정의 ▪ 열 제약 조건 레벨 column [CONSTRAINT constraint_name] constraint_type, ▪ 테이블 제약 조건 레벨 column, …. [CONSTRAINT constraint_name] constraint_type (column, …), ▣ NOT NULL 제약 조건 : 해당 열이 널 값을 허용하지 않습니다. : 예제) deptno NUMBER(7,2) NOT NULL, 이나 deptno NUMBER(7,2) CONSTRAINT emp_deptno_nn NOT NULL, ▣ UNIQUE KEY 제약 조건 : 열 또는 열 집합의 모든 값이 고유하도록 지정 SQL> CREATE TABLE dept ( deptno NUMBER(2), dname VARCHAR2(14), loc VARCHAR2(13), CONSTRAINT dept_dname_uk UNIQUE(dname)); ▣ PRIMARY KEY 제약 조건 SQL> CREATE TABLE dept ( deptno NUMBER(2), dname VARCHAR2(14), loc VARCHAR2(13), CONSTRAINT dept_dname_uk UNIQUE (dname), CONSTRAINT dept_deptno_pk PRIMARY KEY (deptno)); ▣ FOREIGN KEY 제약 조건 : 참조 무결성 제약 조건은 열 또는 열 조합을 외래키로 지정하고 동일한 테이블이나 다른 테이블에 있는 기본 키 또는 고유 키와의 관계를 설정함. SQL> CREATE TABLE emp ( empno NUMBER(4), ename VARCHAR2(10) NOT NULL, …… deptno NUMBER(7,2) NOT NULL, CONSTRAINT emp_deptno_fk FOREIGN KEY (deptno) REFERENCES dept (deptno));
▣ FOREIGN KEY 제약 조건 키워드 ▪ FOREIGN KEY : 테이블 제약 조건 레벨로 하위 테이블의 열을 정의 ▪ REFERENCES : 상위 테이블의 열 및 테이블을 나타냄 ▪ ON DELETE CASCADE : 상위 테이블 삭제되면 하위 테이블의 종속 행도 삭제됨 ▣ CHECK 제약 조건 ▪ 각 행이 만족해야 하는 조건을 정의 ▪ 허용되지 않는 표현식 : - CURRVAL, NEXTVAL, LEVEL 및 ROWNUM 의사 열 참조 - SYSDATE, UID, USER 및 USERENV 함수 호출 - 다른 행의 다른 값을 참조하는 질의 …, deptno NUMBER(2), CONSTRAINT emp_deptno_ck CHECK (DEPTNO BETWEEN 10 AND 99), … ▣ 제약 조건 추가 ALTER TABLE table ADD [CONSTRAINT constraint] type (column) ; ▪ 제약 조건을 추가 또는 삭제할 수 있지만 수정할 수는 없습니다. ▪ 제약 조건을 설정 또는 해제합니다. ▪ MODIFY 절을 사용하여 NOT NULL 제약 조건을 추가합니다. SQL> ALTER TABLE emp ADD CONSTRAINT emp_mgr_fk FOREIGN KEY (mgr) REFERENCES emp(empno); ▣ 제약 조건 삭제 ▪ EMP 테이블에서 관리자 제약 조건을 삭제 SQL> ALTER TABLE emp DROP CONSTRAINT emp_mgr_fk ; ▪ DEPT 테이블에서 PRIMARY KEY 제약조건을 삭제하고 EMP.DEPTNO 열에서 연관된 FOREIGN KEY 제약 조건을 삭제 SQL> ALTER TABLE dept DROP PRIMARY KEY CASCADE ; ▣ 제약 조건 해제 ▪ ALTER TABLE 문의 DISABLE 절을 실행하여 무결성 제약 조건을 해제합니다. ▪ CASCADE 옵션을 적용하여 종속 무결성 제약 조건을 해제합니다. SQL> ALTER TABLE emp DISABLE CONSTRAINT emp_empno_pk CASCADE ; ▣ 제약 조건 설정 ▪ ENALBE 절을 사용하여 현재 테이블 정의에 해제되어 있는 무결성 제약 조건을 설정 SQL> ALTER TABLE emp ENABLE CONSTRAINT emp_empno_pk ; ▣ 계단식 제약 조건 ▪ CASCADE CONSTRAINTS 절은 DROP COLUMN 절과 함께 사용됨 ▪ CASCADE CONSTRAINTS 절은 삭제된 열에 정의된 기본 키와 고유 키를 참조하는 모든 참조 무결성 제약 조건을 삭제함.
▣ 제약 조건 보기 : USER_CONSTRAINTS 테이블을 질의하여 모든 제약 조건의 정의 및 이름을 조회 SQL> SELECT constraint_name, constraint_type, search_condition FROM user_constraints WHERE table _name = ‘EMP’ ; ▪ C는 CHECK를 P는 PRIMARY KEY를 R는 참조 무결성을 U는 UNIQUE KEY를 나타냄 ▪ NOT NULL 제약 조건은 사실상 CHECK 제약 조건입니다. ▣ 제약 조건과 연관된 열 보기 ▪ USER_CONS_COLUMNS 뷰를 통해 제약 조건 이름과 연관된 열을 조회한다. SQL> SELECT constraint_name, column_name FROM user_cons_columns WHERE table_name = ‘EMP’ ; 13. VIEW 생성 ▣ 데이터베이스 객체 종류 ▪ 테이블 : 기본 저장단위로서 행과 열로 구성됨 ▪ 뷰 : 하나 이상의 테이블에서 데이터의 부분집합을 논리적으로 표시 ▪ 시퀀스 : 기본 키 값을 생성 ▪ 인덱스 : 효율적으로 질의할 수 있음 ▪ 동의어 : 객체의 다른 이름 ▣ 뷰 사용 목적 ▪ 데이터 액세스를 제한하기 위해 ▪ 복잡한 질의를 쉽게 작성하기 위해 ▪ 데이터 독립을 허용하기 위해 ▪ 동일한 데이터로부터 다양한 결과를 얻기위해 ▣ 뷰 생성 ▪ CREATE VIEW문에 하위 질의를 포함시킴 CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name [(alias[, alias]…)] AS subquery [WITH CHECK OPTION [CONSTRAINT constraint]] [WITH READ ONLY]; ▪ 하위질의는 복합 SELECT 구문을 포함 ▪ 하위질의는 ORDER BY 절을 포함할 수 없음 ▪ OR REPLACE 뷰가 이미 있어도 다시 생성함 ▪ FORCE 기본 테이블의 존재여부에 관계없이 뷰를 생성 ▪ NOFORCE 기본 테이블이 있는 경우만 뷰를 생성 ▪ WITH CHECK OPTION 뷰를 통해 액세스할 수 있는 행만 삽입 또는 갱신할 수 있도록 지정 ▪ WITH READ ONLY 이 뷰를 통해서는 DML 작업을 수행할 수 없음 ▪ USER_VIEWS 데이터 딕셔너리를 통해 뷰의 이름 및 정의를 볼 수 있음 ▣ 뷰를 통한 DML 작업 수행에 관한 규칙 ▪ 단순 뷰를 통해 DML 작업을 수행할 수 있음 ▪ 뷰가 다음을 포함한 경우 행을 제거할 수 없음 - 그룹함수 - GROUP BY 절 - DISTINCT 키워드 - 의사 열 ROWNUM 키워드
▣ 뷰를 통한 DML 작업 수행에 관한 규칙 ▪ 뷰가 다음을 포함하는 경우 데이터를 수정할 수 없음 - 이전 슬라이드에 언급된 모든 조건 - 표현식에 의해 정의된 열 ( 예: SAL * 12 ) - ROWNUM 의사 열 ▪ 다음과 같은 경우 데이터를 추가할 수 없음 - 뷰가 이에서 언급한 조건 또는 이전 슬라이드에서 언급한 조건을 포함하는 경우 - 기본 테이블에서 뷰에 의해 선택되지 않은 열에 NOT NULL 제약 조건이 있는 경우 ▣ WITH CHECK OPTION 절 사용 ▪ 뷰를 통한 DML 작업이 뷰의 도메인 내에서 수행됨 ▪ 뷰를 통한 삽입 및 갱신 작업이 뷰가 선택할 수 없는 행은 생성하지 않으며 삽입 또는 갱신 되는 데이터에 대해 무결성 제약 조건을 적용하고 데이터의 유효성을 검사할 수 있음. ▣ DML 작업 거부 ▪ 뷰 정의에 WITH READ ONLY 옵션을 추가하여 DML 작업을 거부할 수 있음. ▣ 뷰 제거 ▪ DROP VIEW view_name ; ▣ 인라인 뷰 SELECT a.ename, a.sal, a.deptno, b.maxsal FROM emp a, (SELECT deptno, max(sal) maxsal FROM emp GROUP BY deptno ) b WHERE a.deptno = b.deptno AND a.sal < b.maxsal ; 14. 기타 데이터베이스 객체 ▣ 시퀀스란 ? ▪ 고유번호를 자동으로 생성 ▪ 공유 가능한 객체 ▪ 일반적으로 기본 키 값을 생성하는데 사용됩니다. ▪ 응용 프로그램 코드를 대체합니다. ▪ 시퀀스 값을 메모리에 캐시하면 액세스 효율이 높아집니다. ▣ CREATE SEQUENCE 문 ▪ 시퀀스를 정의하여 시퀀스 번호를 자동으로 생성함 CREATE SEQUENCE sequence [INCREMENT BY n] [START WITH n] [{MAXVALUE n | NOMAXVALUE}] [{MINVALUE n | NOMINVALUE}] [{CYCLE | NOCYCLE}] {{CACHE n | NOCACHE}]; - CYCLE : 시퀀스가 최대값 또는 최소값에 도달한 후 추가 값의 생성여부 지정 - CACHE : 오라클 서버가 미리 할당하여 메모리에 저장할 값의 개수를 지정.
▣ 시퀀스 확인 ▪ USER_SEQUENCES 데이터 딕셔너리 테이블에서 시퀀스 값을 확인 SQL> SELECT sequence_name, min_value, max_value, increment_by, last_number FROM user_sequences ; ▪ LAST_NUMBER 열에는 사용 가능한 다음 시퀀스 번호가 표시 ▣ NEXTVAL 및 CURRVAL 의사 열 ▪ NEXTVAL은 사용 가능한 다음 시퀀스 값을 반환함 ▪ NEXTVAL은 시퀀스 값을 참조할 때마다 고유한 값을 반환 ▪ CURRVAL은 현재 시퀀스 값을 반환 ▪ 다음에서는 NEXTVAL 및 CURRVAL을 사용할 수 없음 - 뷰의 SELECT 목록 - DISTINCT 키워드가 있는 SELECT 문 - GROUP BY, HAVING, ORDER BY 절이 있는 SELECT문 - SELECT, DELETE, UPDATE 문의 하위질의 - CREATE TABLE 또는 ALTER TABLE 문의 DEFAULT 표현식 SQL> INSERT INTO dept(deptno, dname, loc) VALUES (dept_deptno.nextval, ‘MARKETING’, ‘LA’); ▣ 시퀀스 수정 ▪ 시퀀스 소유자이거나 시퀀스에 대한 ALTER 권한이 있어야 한다. ▪ 이후 시퀀스 번호에만 영향을 준다 ▪ 시퀀스를 다른 번호로 다시 시작하려면 시퀀스를 삭제한 후 다시 생성해야 한다. ▪ 일부 검증이 수행된다.(예: 새로은 MAXVALUE 값을 현재 시퀀스번호보다 작을 순 없다. ▪ START WITH옵션은 ALTER SEQUENCE를 사용하여 변경할 수 없다. SQL> ALTER SEQUENCE dept_deptno INCERMENT BY 1 ~~~~~; ▪ 시퀀스 제거는 SQL> DROP SEQUENCE dept_deptno ; ▣ 인덱스 정의 ▪ 스키마 객체입니다. ▪ 포인터를 사용하여 행 검색 속도를 높이기 위해 Oracle Sever가 사용 ▪ 데이터 위치를 빠르게 찾는 신속한 경로 액세스 방법을 사용하여 디스크 I/O를 줄일 수 있음 ▪ 인덱스화된 테이블과 독립되어 존재함 ▪ 오라클 서버에 의해 사용되며 자동으로 유지관리됨 ▣ 인덱스 생성 ▪ 하나 이상의 열에 대한 인덱스를 생성 CREATE INDEX index ON table ( column[, column]…); ▪ 열이 WHERE 절 또는 조인 조건에서 자주 사용되는 경우 ▪ 열에 광범위한 값이 포함된 경우 ▪ 열에 널 값이 많이 포함된 경우 ▪ WHERE 절 또는 조인 조건에서 두개 이상의 열이 함께 자주 사용되는 경우 ▪ 큰 테이블에서 대부분의 질의에 의해 검색되는 범위가 2% ~ 4% 미만인 경우
▣ 인덱스를 생성하지 않은 경우 ▪ 테이블이 작은 경우 ▪ 열이 질의의 조건으로 자주 사용되지 않는 경우 ▪ 대부분의 질의에 의해 검색되는 행이 2%~4% 이상인 경우 ▪ 테이블이 자주 갱신되는 경우 ▣ 인덱스 확인 ▪ USER_INDEXES 데이터 딕셔너리 뷰는 인덱스 이름 및 고유성을 포함 ▪ USER_IND_COLUMNS 뷰는 인덱스 이름, 테이블 이름 및 열 이름을 포함함 ▣ 함수 기반 인덱스 ▪ 함수 기반 인덱스는 표현식을 기반으로 하는 인덱스입니다. ▪ 인덱스 표현식은 테이블 열, 상수, SQL 함수 및 사용자가 정의한 함수에서 생성됨 SQL> CREATE INDEX uppercase_idx ON emp ( UPPER(ename) ); ▪ 인덱스 제거는 SQL> DROP INDEX index ; ▪ 인덱스를 삭제하려면 인덱스 소유자이거나 DROP ANY INDEX 권한이 있어야 함 ▣ 동의어 ▪ 다른 사용자가 소유한 테이블을 참조함 ▪ 긴 객체 이름을 짧게 만듦 SQL> CREATE [PUBLIC] SYNONYM sysnoym_name FOR object ; ▣ 동의어 생성 및 제거 ▪ DEPT_SUM_VU 뷰의 간략한 이름을 생성함. SQL> CREATE SYNONYM d_sum FOR dept_sum_vu ; ▪ 동의어를 삭제합니다. SQL> DROP SYNONYM d_sum ; 15. 사용자 엑세스 제어 ▣ 권한 ▪ 데이터베이스 보안 : 시스템 보안, 데이터 보안 ▪ 시스템권한 : 데이터베이스를 액세스할 수 있음. ▪ 객체권한 : 데이터베이스 객체 내용을 조작할 수 있음 ▪ 스키마 : 테이블, 뷰, 시퀀스 등과 같은 객체의 모음 ▣ 시스템 권한 ▪ 80가지 이상의 권한을 사용할 수 있음 ▪ DBA는 다음과 같은 상위 레벨 시스템 권한을 갖습니다. ( 새 사용자 생성, 사용자 제거, 테이블 제거, 테이블 백업 ) ▣ 사용자 생성 ▪ DBA 는 CREATE USER 문을 사용하여 사용자를 생성함. SQL> CREATE USER user_id IDENTIFIED BY password ; ▣ 사용자 시스템 권한 ▪ DBA는 생성된 사용자에게 특정 시스템 권한을 부여할 수 있음 SQL> GRANT privilege [, privilege…] TO user [, user…] ;
▪ 응용 프로그램 개발자는 다음과 같은 시스템 권한을 갖습니다. - CREATE SESSION : 데이터베이스에 연결합니다. - CREATE TABLE : 사용자의 스키마에 테이블을 생성 - CREATE SEQUENCE : 사용자의 스키마에 시퀀스를 생성 - CREATE VIEW : 사용자의 스키마에 뷰를 생성 - CREATE PROCEDURE : 사용자의 스키마에 내장 프로시저, 함수 또는 패키지를 저장 ▣ 시스템 권한 부여 ▪ DBA는 사용자에게 특정 시스템 권한을 부여할 수 있음 SQL> GRANT create table, create sequence, create view TO scott ; ▣ 롤 생성 및 권한 부여 롤은 사용자에게 부여할 수 있는 관련 권한을 하나로 묶어 명명한 그룹으로서 롤을 사용하 면 권한 부여 및 취소를 쉽게 수행하고 유지관리할 수 있음 SQL> CREATE ROLE manager; SQL> GRANT create table, create view TO manager ; SQL> GRANT manager TO scott, bfx ; ▣ 암호변경 ▪ DBA는 사용자 계정을 생성하고 암호를 초기화함. ▪ ALTER USER 문을 사용하여 암호를 변경할 수 있슴. SQL> ALTER USER scott IDENTIFIED BY tiger ; ▣ 객체 권한 ▪ 객체 권한은 객체마다 다릅니다 ▪ 소유자는 객체에 대한 모든 권한을 갖습니다. ▪ 소유자는 자신의 객체에 대한 특정 권한을 부여할 수 있습니다. SQL> GRANT object_priv [(columns)] => 부여할 객체 권한 / 부여할 테이블 또는 열 ON object => 권한을 부여할 객체 TO {user|role|PUBLIC} => 권한을 부여받을 사용자 [WITH GRANT OPTION]; => 다른 사용자에게 받은 권한 부여가능 ▣ 객체 권한 부여 ▪ 테이블에 대한 권한을 부여 SQL> GRANT select, update(dname, loc) ON dept TO scott ; ▣ WITH GRANT OPTION 및 PUBLIC 키워드 사용 ▪ WITH GRANT OPTION 권한을 부여 받은 사용자는 권한을 다른 사용자 및 롤에 전달할 수 있는데 권한 부여자의 권한이 취소되면 WITH GRANT OPTION을 통해 부여된 객체 권한도 취소된다. ▪ PUBLIC 키워드를 사용하여 모든 사용자에게 엑세스 권한을 부여할 수 있다.
▣ 부여된 권한 확인 ▣ 객체 권한 취소 방법 ▪ REVOKE 문을 사용하여 다른 사용자에게 부여된 권한을 취소합니다. ▪ WITH GRANT OPTION을 통해 다른 사용자에게 부여된 권한도 취소됩니다. SQL> REVOKE {privilege [, privilege…] | ALL} ON object FROM {user[, user…..] | role | PUBLIC} [CASCADE CONSTRAINTS] ; SQL> REVOKE select, insert ON dept FROM scott ; 16. 변수 선언 ▣ PL/SQL 블록 구조 ▪ DECLARE –선택사항 - 변수, 커서, 사용자가 정의한 예외사항 ▪ BEGIN –필수 - SQL 문 - PL/SQL 문 ▪ EXCEPTION –선택사항 오류가 발생할 때의 수행작업 ▪ END ; - 필수 DECLARE v_variable VARCHAR2(5); BEGIN SELECT column INTO v_variable FROM table_name ; EXCEPTION WHEN exception_name THEN ……. END ;
▣ 블록유형 ▪ 블록유형 : PL/SQL의 모든 단위는 하나 이상의 블록으로 구성되며 이러한 블럭은 완전히 분리되거나, 다른 블럭안에 중첩될 수 있다 ▪ 익명블럭 : 익명블럭은 이름이 지정되지 않은 블록 [DECLARE] …. BEGIN -- STATEMENTS [EXCEPTION] END ; ▪ 하위프로그램 : 매개변수를 사용할 수 있는 명명된 PL/SQL 블럭이며 호출할 수 있다. 하위프로그램을 프로시저나 함수로 선언할 수 있다. - 프로시저 PROCEDURE proc_name IS BEGIN -- STATEMENTS [EXCEPTION] END ; - 함수 FUNCTION fun_name RETURN datatype IS BEGIN -- STATEMENTS RETURN value ; [EXCEPTION] END ; ▣ 변수 사용 다음의 경우에 변수를 사용합니다. - 데이터 임시 저장 - 저장된 값 조작 - 재 사용 - 유지 관리의 용이성 ▣ PL/SQL 에서 변수 처리 ▪ 선언 부분에서 변수를 선언하고 초기화합니다. ▪ 실행 부분에서 변수에 새 값을 할당합니다. ▪ 매개변수를 통해 값을 PL/SQL 블록에 전달합니다. ▪ 출력 변수를 통해 결과를 봅니다. ▣ 변수유형 ▪ 사진의 데이터 유형은 BLOB ▪ 연설 텍스트의 데이터 유형은 LONG RAW ▪ 영화의 데이터 유형은 BFILE ▪ 이름은 VARCHAR2
▣ PL/SQL 변수 선언 ▪ 구문 identifier [CONSTANT] datatype [NOT NULL] [:= | DEFAULT expr]; ▪ 예제 Declare v_date CHAR(8); v_deptno NUMBER(2) NOT NULL := 10 ; v_location VARCHAR2(13) := ‘Korea’ ; c_comm CONSTANT NUMBER := 1400 ; ▪ 이름 지정 규칙을 따른다. - 서로 다른 블록에 있는 두 변수는 동일한 이름을 가질 수 있다 - 변수이름은 블록에서 사용되는 테이블의 열의 이름과 동일하면 안된다. ▪ NOT NULL 및 CONSTANT 로 지정된 변수를 초기화한다. ▪ 할당연산자(:=) 또는 DEFAULT 예약어를 사용하여 식별자를 초기화 ▪ 식별자를 한 행에 하나씩 선언 ▣ 기본 스칼라 데이터 유형 ▪ VARCHAR2 (maximum_length) ▪ NUMBER [(precision, scale)] ▪ DATE ▪ CHAR [(maximum_length)] ▪ LONG ▪ LONG RAW : 이진 데이터 및 바이트 문자열의 기본 유형이며 최대 길이는 32,760byte. ▪ BOOLEAN ▪ BINARY_INTEGER : -2,147,483,647과 2,147,483,647 사이에 있는 정수의 기본 유형 ▪ PLS_INTEGER : -2,147,483,647과 2,147,483,647 사이에 있는 부호표시 정수의 기본유형 ▣ %TYPE 속성 ▪ 다음에 따라 변수를 선언합니다. - 데이터 베이스 열 정의 - 이전에 선언한 다른 변수 ▪ %TYPE에 다음을 접두어로 붙입니다. - 데이터베이스 테이블 및 열 - 이전에 선언한 변수 이름 ▣ %TYPE 속성을 사용하여 변수 선언 v_name emp.ename%TYPE; v_balance NUMBER(7,2); v_min_balance v_balance%TYPE := 10; ▣ LOB 데이터 유형 변수 ▪ CLOB(Character Large Object) : 단인 바이트 문자 데이터의 대형블록을 저장 (책) ▪ BLOB(Binary Large Object) : 대형 이진 객체를 DB에 행 내에 순서대로 또는 행 외부에 무순서 저장(사진) ▪ BFILE(Binary FILE) : 대형 이진 객체를 DB 외부에 있는 운영 체제 파일에 저장(영화) ▪ NCLOB(National language Character Large Object) : 단일 바이트 또는 고정 너비 멀티 바이트 NCHAR 데이터를 데이터베이스에 순서대로 또는 순서없이 저장합니다.
▣ 바이드 변수 ▪ 바이드 변수는 호스트 환경에서 선언한 변수로서 런타임 값 (숫자 또는 문자)을 하나 이상의 PL/SQL 프로그램과 주고 받는데 사용합니다. PL/SQL 프로그램은 바인드 변수를 다른 변수와 마찬가지로 사용합니다. ▪ 바이드 변수 생성 - VARIABLE return_code NUMBER - VARIABLE return_name VARCHAR2(30) ▪ SQL*Plus 환경에서는 PRINT 명령을 사용하여 바이드 변수의 현재 값을 표시할 수 있다 SQL> VARIABLE rtn_data VARCHAR2(31); SQL> BEGIN SELECT s_jmname INTO :rtn_data FROM bdjmst WHERE jmcode = ‘xxxxxxx’ ; END ; / SQL> PRINT rtn_data ; ▣ 비 PL/SQL 변수 참조 ▪ 변수에 값 할당 호스트 변수를 참조하려면 참조대상에 콜론(:)을 접두어로 붙여 선언된 PL/SQL 변수와 구분 예제 ) VARIABLE g_monthly_sal NUMBER ACCEPT p_annual_sal PROMPT ‘Please enter the annual salary: ‘ DECLARE v_sal NUMBER(9,2) := &p_annual_sal ; BEGIN :g_monthly_sal := v_sal /12 ; END ; / PRINT g_monthly_sal ▣ DBMS_OUTPUT.PUT_LINE ▪ Oracle 지원 패키지 프로시저입니다. ▪ PL/SQL 블록에서 데이터를 표시하는 또 하나의 방법입니다. ▪ SET SERVEROUTPUT ON을 사용하여 SQL*Plus에서 사용 가능하도록 설정합니다. SET SERVEROUTPUT ON ACCEPT p_annual_sal PROMPT ‘Please enter the annual salary: ‘ DECLARE v_sal NUMBER(9,2) := &p_annual_sal ; BEGIN v_sal := v_sal / 12 ; DBMS_OUTPUT.PUT_LINE (‘The monthly salary is ‘ || TO_CHAR(v_sal)); END ; /
17.실행문 작성 ▣ PL/SQL 블록 구문 및 지침 ▪ 명령문은 여러 행에 나누어 쓸 수 있습니다. ▪ PL/SQL 블록은 행에 슬래시(/)가 있으면 종결됩니다. ▪ 렉시칼 단위를 구분하는 기준은 다음과 같습니다. 공백, 구분자, 식별자, 리터럴, 주석 식별자 ▪ 최고 30자까지 가능합니다. ▪ 예약어는 큰 따옴표로 묶어야 합니다. ▪ 영문자로 시작해야 합니다. ▪ 데이터베이스 테이블 열 이름과 동일하면 안됩니다. 리터럴 ▪ 문자 및 날짜 리터럴은 작은 따옴표로 묶어야 합니다. ▪ 숫자는 단순 값이나 과학적 표기법으로 나타낼 수 있습니다. ▣ 코드에 주석달기 ▪ 단일 행 주석에는 대시 두 개 (--)를 접두어로 붙입니다. ▪ 여러 행 주석은 기호 /* 와 */ 사이에 작성한다. ▣ PL/SQL 의 SQL 함수 ▪ 다음은 프로시저 문에서 사용할 수 있습니다. 단일 행 숫자, 단일 행 문자, 데이터 유형 변환, 날짜 ▪ 다음은 프로시저 문에서 사용할 수 없음 DECODE, 그룹함수(AVG, MIN, MAX, COUNT, SUM, STDDEV, VARIANCE) - 그룹 함수는 테이블의 행 그룹에 적용되므로 PL/SQL 블록의 SQL문에서만 사용가능. ▣ 데이터 유형 변환 ▪ TO_CHAR ▪ TO_DATE ▪ TO_NUMBER ▣ 중첩 블록 및 변수 범위 ▪ 실행문이 사용 가능한 경우 언제라도 명령문을 중첩할 수 있다. ▪ 중첩 블록은 하나의 명령문이 된다. ▪ EXCEPTION 섹션은 중첩 블록을 포함할 수 있다. ▪ 객체의 범위는 객체를 참조할 수 있는 프로그램 영역이다. ▪ 블록은 상위 블록을 조회할 수 있다. ▪ 블록은 하위 블록을 조회할 수 없다. ▣ PL/SQL의 연산자 ▪ NULL을 포함하는 비교 결과는 항상 NULL이다 ▪ NULL에 논리 연산자 NOT을 적용하면 결과는 NULL이 된다 ▪ 조건 제어문에서 조건의 결과가 NULL이면 연관된 일련의 명령문이 실행되지 않는다 ▣ 프로그래밍 지침 ▪ 주석을 사용하여 코드 문서화 ▪ 코드에 대해 대소문자 규칙 개발 예) SQL문 –대문자, PL/SQL 키워드 –대문자, 데이터 유형 –대문자, 식별자와 매개변수 –소문자, 데이터베이스 테이블과 열 - 소문자 ▪ 식별자와 기타 객체에 대한 이름 지정 규칙 개발 ▪ 들여쓰기를 사용하여 가독성 향상
▣ 코드 이름 지정 규칙 ▪ 지역변수와 공식 매개변수의 이름은 데이터베이스 테이블의 이름보다 우선순위가 높다 ▪ 열의 이름은 지역변수의 이름보다 우선순위가 높다. 18. Oracle Server를 사용한 대화식 처리 ▣ PL/SQL의 SELECT 문 DECLARE v_deptno NUMBER(2); v_loc VARCHAR2(15); BEGIN SELECT deptno, loc INTO v_deptno, v_loc FROM dept WHERE dname = ‘SALES’ ; END ; ▣ PL/SQL에서 데이터 검색 DECLARE v_sum_sal emp.sal%TYPE; v_deptno NUMBER NOT NULL := 10; BEGIN SELECT SUM(sal) INTO v_sum_sal FROM emp WHERE deptno = v_deptno ; END ; ▣ PL/SQL 을 사용하여 데이터 조작 BEGIN INSERT INTO emp(empno, empname, job, sal) VALUES (empno_sequence.NEXTVAL, ‘JEONG’, ‘PROGRAMMER’, 2400); END ; ▣ COMMIT 문과 ROLLBACK 문 ▪ 첫번째 DML 명령으로 트랜잭션을 초기화하여 COMMIT 또는 ROLLBACK을 수행함 ▪ COMMIT 및 ROLLBACK SQL 문을 사용하여 트랜잭션을 명시적으로 종료함 COMMIT [WORK]; SAVEPOINT savepoint_name ; ROLLBACK [WORK] ; ROLLBACK [WORK] TO [SAVEPOINT] savepoint_name ; ▪ 블록에 명시적 잠금 명령(예: LOCK TABLE 및 SELECT …. FOR UPDATE)을 포함할 수도 있습니다.
▣ SQL 커서 속성 ▪ SQL 커서 속성을 사용하면 SQL 문의 결과를 테스트할 수 있습니다. ▪ 블록의 EXCEPTION 섹션에서 SQL%ROWCOUNT, SQL%FOUND, SQL%NOTFOUND, SQL%ISOPEN 속성을 사용하여 데이터 조작문의 실행 부분에 대한 정보를 모을 수 있다. VARIABLE rows_deleted VARCHAR2(30) DECLARE v_ordid NUMBER := 65 ; BEGIN DELETE FROM item WHERE ordid = v_ordid; :rows_deleted := (SQL%ROWCOUNT || ‘ rows deleted.’) ; END ; / PRINT rows_deleted 19. 제어구조 작성 ▣ IF 문 ▪ 구문 IF condition THEN statements ; [ELSEIF condition THEN statements; ] [ELSE statements;] END IF ; IF v_start > 100 THEN v_start := 2 * v_start ; ELSEIF v_start >= 50 THEN v_start := .5 * v_start ; ELSE v_start := .1 * v_start ; END IF ;
▣ 기본 루프 (LOOP) ▪ 구문 LOOP statement1 ; ….. EXIT [WHEN condition] ; END LOOP ; ▪ 예제 DECLARE v_ordid item.ordid%TYPE := 601 ; v_count NUMBER2) := 1 ; BEGIN LOOP INSERT INTO item(ordid, itemid) VALUES (v_ordid, v_count) ; v_count := v_count + 1 ; EXIT WHEN v_count > 10 ; END LOOP ; END ; ▣ FOR LOOP ▪ 구문 FOR counter IN [REVERSE] lower_bound..upper_bound LOOP statement1; …… END LOOP; ▪ 카운터는 루프 내에서만 참조할 수 있으며 루프 밖에서는 정의되지 않습니다. ▪ 카운터의 기존 값을 참조하려면 표현식을 사용하십시요 ▪ 카운터를 할당 대상으로 참조하지 마십시오 DECLARE v_lower NUMBER := 1 ; v_upper NUMBER := 100; BEGIN FOR i IN v_lower..v_upper LOOP …… END LOOP ; END; ▣ WHILE LOOP ACCEPT p_new_order PROMPT ‘Enter the order number: ‘ ACCEPT p_items PROMPT ‘Enter the number of items in this order: ‘ DECLARE v_count NUMBER(2) := 1 ; BEGIN WHILE v_count <= &p_items LOOP …… v_count := v_count + 1 ; END LOOP ; END ;
▣ 중첩 루프 및 레이블 BEGIN << Outer_loop>> -- 레이블 LOOP v_counter := v_counter + 1 ; EXIT WHEN v_counter > 10 ; << Inner_loop>> LOOP ……. EXIT Outer_loop WHEN total_done = ‘YES’ ; -- Leave both loops EXIT WHEN inner_done = ‘YES’ ; -- Leave inner loop only ….. END LOOP Inner_loop ; … END LOOP Outer_loop; END; 20. 조합 데이터 유형 사용 ▣ 조합 데이터 유형 ▪ 조합 데이터 유형에는 RECORD, TABLE, NESTED TABLE 및 VARRAY 등이 있슴 ▣ PL/SQL 레코드 ▪ 필드라고 불리는 PL/SQL 테이블, 레코드, 임의의 스칼라 데이터 유형 중 하나 이상의 구성요소를 포함해야 함 ▪ 3GL의 레코드 구조와 유사함 ▪ 데이터베이스 테이블의 행과 동일하지 않습니다. ▪ 필드 모음을 하나의 논리 단위로 처리합니다. ▪ 테이블에서 데이터 행을 인출하여 처리하는데 편리합니다. ▪ 사원이름, 급여, 입사일 등과 같은 필드를 포함하는 레코드의 경우에는 데이터를 하나의 논리 단위로 처리할 수 있다 ▣ PL/SQL 레코드 생성 ▪ 구문 TYPE type_name IS RECORD (field_declaration[, field_declaration]… ); identifier type_name ; 여기서 field_declaration은 다음과 같습니다. field_name {field_type | variable%TYPE | table.column%TYPE | table%ROWTYPE} [[NOT NULL] {:= | DEFAULT} expr] ▪ type_name : 레코드 유형의 이름이며 레코드를 선언할 때 이 식별자 사용 ▪ field_name : 레코드 필드의 이름 ▪ field_type : 필드의 데이터 유형이며 REF CURSOR를 제외한 모든 PL/SQL데이터 유형을 나타냄. %TYPE과 %ROWTYPE 속성을 사용할 수 있다 ▪ expr : field_type 또는 초기값 ▪ NOT NULL 제약조건이 있는 필드에는 널을 할당할 수 없으므로 NOT NULL 필드는 반드시 초기화 해야 함
▣ PL/SQL 레코드 생성 ▪ 신입사원의 이름, 직위, 급여등을 저장할 변수를 선언 ▪ NOT NULL 제약조건을 추가할 수 있으며 반드시 초기화 하여야 합니다. ▪ 예제 … TYPE emp_record_type IS RECORD (ename VARCHAR2(10), job VARCHAR2(9), sal NUMBER(7,2), dept emp.dept%TYPE); emp_record emp_record_type ; … ▪ 레코드 참조 record_name.field_name ▣ %ROWTYPE 속성 ▪ 데이터베이스 테이블 또는 뷰의 열 모음에 따라 변수를 선언합니다. ▪ %ROWTYPE에 데이터베이스 테이블 이름을 접두어로 붙입니다. ▪ 레코드 필드의 이름과 데이터 유형은 테이블 또는 뷰의 열에서 가져옵니다 ▪ 선언 DECLARE emp_record emp%ROWTYPE ; ▪ 참조 emp_reocord.sal := 1000 ; ▪ 예제 DECLARE emp_rec emp%ROWTYPE ; BEGIN SELECT * INTO emp_rec FROM emp WHERE empno = &emp_num ; INSERT INTO retired_emp(emp, name, job, mgr, hiredate, leavedate) VALUES (emp_rec.emp, emp_rec.name, emp_rec.job, emp_rec.mgr, emp_tec.hiredate, sysdate ); COMMIT ; END ; ▣ PL/SQL 테이블 ▪ 다음 두개의 구성요소로 구성됨 - BINARY_INTEGER 데이터 유형의 기본 키 - 스칼라 또는 레코드 데이터 유형의열 ▪ 크기 제한이 없으므로 동적으로 증가한다 ▪ 테이블 유형의 객체를 PL/SQL 테이블이라고 하며 테이터베이스 테이블로 모델링된다. (데이터베이스 테이블과 동일하지 않음) ▪ 배열과 유사함
▣ PL/SQL 테이블 생성 ▪ 구문 TYPE type_name IS TABLE OF {column_type | variable%TYPE | table.column%TYPE } [NOT NULL] [INDEX BY BINARY_INTEGER] ; identifier type_name ; ▪ 테이블의 데이터 유형을 선언 ▪ 예제 … TYPE ename_table_type IS TABLE OF emp.ename%TYPE INDEX BY BINARY_INTEGER; ename_table ename_table_type ; … ▪ PL/SQL 테이블 구조 기본키 열 BINARY_INTEGER 스칼라 ▪ PL/SQL 테이블에는 하나의 열과 하나의 기본 키가 있는데 둘 중 어느 것에도 이름을 지정할 수 없습니다. 열은 스칼라 또는 레코드 데이터 유형일 수 있지만 기본 키는 BINARY_INTEGER 유형이어야 합니다. ▣ PL/SQL 테이블 생성 DECLARE TYPE ename_table_type IS TABLE OF emp.ename%TYPE INDEX BY BINARY_INTEGER; TYPE hiredate_table_type IS TABLE OF DATE INDEX BY BINARY_INTEGER; ename_table ename_table_type; BEGIN ename_table(1) := ‘CAMERON’ ; hiredate_table(8) := SYSDATE + 7; IF ename_table.EXISTS(1) THEN INSERT INTO …. END; ▪ table.EXISTS(I) 문은 인덱스 I가 있는 행이 적어도 하나 이상 반환되어야 TRUE를 반환합니다. EXISTS 문을 사용하여 존재하지 않는 테이블 요소를 참조할 때 발생하는 오류를 방지합니다.
▣ PL/SQL 테이블 메소드 사용 다음 메소드를 사용해서 PL/SQL 테이블을 쉽게 사용할 수 있습니다. ▣ 레코드로 구성된 PL/SQL 테이블 ▪ 허용된 PL/SQL 데이터 유형을 사용하여 테이블 변수를 정의 ▪ 부서정보를 저장할 PL/SQL 변수를 선언 ▪ 예제 DECLARE TYPE dept_table_type IS TABLE OF dept%ROWTYPE INDEX BY BINARY_INTEGER; dept_table dept_table_type ; ▣ 레코드로 구성된 PL/SQL 테이블 예제 DECLARE TYPE emp_table_type IS TABLE OF emp.Ename%TYPE INDEX BY BINARY_INTEGER ; e_table e_table_type ; BEGIN e_tab(1) := ‘SMITH’ ; UPDATE emp SET sal = 1.1 * sal WHERE Ename = e_tab(1) ; COMMIT ; END ; /
21. 명시적 커서 작성 ▣ 명시적 커서 제어 (프로그래머가 선언) ▣ 커서선언 ▪ 구문 CURSOR cursor_name IS select_statement ; ▪ 커서 선언 부분에 INTO 절을 포함시키지 마십시오 ▪ 특정 시퀀스로 행을 처리해야 하는 경우 질의에 ORDER BY 절을 사용하십시오 ▪ 예제 DECLARE v_empno emp.empno%TYPE ; v_ename emp.ename%TYPE ; CURSOR emp_cur IS SELECT empno, ename FROM emp ; BEGIN … ▣ 커서열기 OPEN cursor_name ; ▪ 커서를 열어 질의를 실행하고 활성집합을 식별함 ▪ 질의에 의해 반환되는 행이 없으면 예외사항이 발생하지 않습니다 ▪ 커서 속성을 사용하여 인출 후의 결과를 테스트합니다 ▪ OPEN의 역할 - 중요한 처리정보를 포함하는 컨텍스트 영역에 대한 메모리를 동적으로 할당 - SELECT 문의 구문을 분석 - 입력 변수를 바인드함. 즉, 해당 메모리 주소를 확보하여 입력 변수의 값을 설정 - 활성집합, 즉 검색조건을 만족하는 행 집합을 식별합니다. OPEN문을 실행하면 활성 집합의 행을 변수로 가져오지 않습니다. - 포인터 위치를 활성 집합의 첫번째 행 앞으로 지정함. ▪ FOR UPDATE 절을 사용하여 커서를 선언한 경우 OPEN 문은 해당 행을 잠급니다. ▣ 커서에서 데이터 인출 ▪ 구문 FETCH cursor_name INTO [variable1, variable2, …] ▪ 현재 행 값을 변수로 가져옵니다. ▪ 동일한 개수의 변수를 포함시킴 ▪ 각 변수를 해당 열에 위치적으로 대응시킴 ▪ 커서의 행 포함 여부를 테스트함. 아니오 예 Empty? DECLARE OPEN FETCH CLOSE 활성 집합식별 현재 행을 변수에 로드 활성집합 해제 명명된 SQL 영역 생성 기존행테스트
▣ 커서에서 데이터 인출 ▪ 예제 DECLARE v_empno emp.empno%TYPE ; v_ename emp.ename%TYPE ; CURSOR emp_cursor IS SELECT empno, ename FROM emp ; BEGIN OPEN emp_cursor ; FOR I IN 1..10 LOOP FETCH emp_cursor INTO v_empno, v_ename ; …. END LOOP ; END ; ▣ 커서 닫기 ▪ 구문 CLOSE emp_cursor ; ▪ 사용자에 대해 열리는 최대 커서 수를 제한할 수 있으며 이 값은 데이터베이스 필드의 OPEN_CURSORS 매개변수에 의해 결정되며 기본적으로 50입니다. ▣ 명시적 커서 속성 ▪ 커서의 상태정보를 제공합니다. ▣ 복수 인출 제어 ▪ 루프를 사용하여 명시적 커서에서 여러 행을 처리함 ▪ %NOTFOUND 속성을 사용하여 실행되지 못한 인출에 대한 테스트를 작성 ▪ 명시적 커서 속성을 사용하여 각 인출 작업이 성공적으로 수행되었는지 테스트 함. ▣ %ISOPEN 속성 ▪ 커서가 열려 있는 경우에만 행을 인출함 ▪ %ISOPEN 커서 속성은 인출 전에 커서가 OPEN되어 있는지 테스트 하는데 사용 ▣ %NOTFOUND 및 %ROWCOUNT 속성 ▪ %ROWCOUNT 커서 속성을 사용하여 정확한 행수 검색 ▪ %NOTFOUND 커서 속성을 사용하여 루프 종료 시기를 결정(첫번째 NOTFOUND는 NULL값) ▪ 예제 ….. EXIT WHEN emp_cursor%ROWCOUNT > 10 OR emp_cursor%NOTFOUND ; …..
▣ 커서 FOR 루프 ▪ 예제 DECLARE CURSOR emp_cursor IS SELECT ename, deptno FROM emp ; -- emp_record emp_cursor%ROWTYPE ;은 선언하지 않음. 자동으로 연결됨. BEGIN FOR emp_record IN emp_cursor LOOP IF emp_record.deptno = 30 THEN DBMS_OUTPUT.PUT_LINE (‘Employee ‘ || emp_record.ename ); END IF ; END LOOP ; END ; ▣ 하위 질의를 사용하는 커서 FOR 루프 ▪ 커서를 선언하지 않아도 됩니다 ▪ 예제 SET SERVEROUTPUT ON BEGIN FOR emp_record IN (SELECT ename, deptno FROM emp ) LOOP IF emp_record.deptno = 30 THEN DBMS_OUTPUT.PUT_LINE(‘Employee ‘ || emp_record.ename); END IF ; END LOOP ; END ; / 22. 고급 명시적 커서 개념 ▣ 매개변수 사용 커서 ▪ 구문 CURSOR cursor_name [(parameter_name datatype, …)] IS select_statement ; ▪ 커서가 열리고 질의가 실행되면서 커서에 매개변수 값을 전달함 ▪ 매번 다른 활성 집합을 사용하여 명시적 커서를 여러 번 엽니다. DECLARE CURSOR emp_cur (p_deptno NUMBER, p_job VARCHAR2) IS SELECT empno, ename FROM emp WHERE deptno = p_deptno AND job = p_job ; BEGIN OPEN emp_cur(10, ‘CLERK’) ; 이나 FOR emp_record IN emp_cur(10, ‘CLERK’) LOOP ….
▣ FOR UPDATE 절 ▪ 구문 SELECT .. FROM FOR UPDATE [OF column_reference] [NOWAIT] ; ▪ 명시적 잠금을 사용하여 트랜잭션 기간 동안 액세슬르 거부할 수 있다 ▪ 갱신 또는 삭제 전에 행을 잠금합니다. ▪ FOR UPDATE 절은 ORDER BY 가 있는 경우에도 SELECT 문의 마지막 절입니다 ▪ NOWAIT는 다른 세션에서 해당 행을 잠근 경우 Oracle 오류를 반환함 ▪ 예제 DECLARE CURSOR emp_cursor IS SELECT empno, ename, sal FROM emp WHERE deptno = 30 FOR UPDATE OF sal NOWAIT ; ▣ WHERE CURRENT OF 절 ▪ 구문 WHERE CURRENT OF cursor ; ▪ 커서를 사용하여 현재 행을 갱신 및 삭제합니다 ▪ 커서 질의에 FOR UPDATE 절을 포함시켜 먼저 행을 잠금니다. ▪ WHERE CURRENT OF 절을 사용하여 명시적 커서에서 현재 행을 참조합니다. ▪ 예제 DECLARE CURSOR sal_cur IS SELECT sal FROM emp WHERE deptno = 30 FOR UPDATE OF sal NOWAIT ; BEGIN FOR emp_record IN sal_cursor LOOP UPDATE emp SET sal = emp_record.sal * 1.1 WHERE CURRENT OF sal_cur ; END LOOP ; COMMIT ; END ; ▣ 하위 질의 포함 커서 ▪ 예제 DECLARE my_cur IS SELECT t1.deptno, t1.name, t2.STAFF FROM dept t1, ( SELECT deptno, count(*) STAFF FROM emp GROUP BY deptno ) t2 WHERE t1.deptno = t2.deptno AND t2.STAFF >= 5 ;
23. 예외 처리 ▣ PL/SQL 로 예외처리 ▪ 예외사항 : 실행중에 발생하는 PL/SQL의 식별자입니다 ▪ 예외발생 : - 오라클 오류가 발생함 - 사용자가 명시적으로 발생시킴 ▪ 처리방법 : - 처리기로 트랩합니다 - 호출 환경으로 전달합니다 예외 트랩 예외 전달 DECLARE BEGIN EXCEPTION END ; DECLARE BEGIN EXCEPTION END ; 예외발생 예외발생 예외사항이 트랩되지 않음 예외트랩 호출환경에 예외전달 ▣ 예외 유형 ▪ 미리 정의한 오라클 서버 예외사항 ▪ 미리 정의하지 않은 오라클 서버 예외 사항 ▪ 사용자가 정의한 예외사항 명시적으로 발생 ▣ 예외트랩 ▪ 구문 EXCEPTION WHEN exception1 [OR exception2 … ] THEN statement1 ; statement2 ; [WHEN exception3 [OR exception4 .. ] THEN statement1 ; statement2 ; [WHEN OTHERS THEN statement1 ; statement2 ; ] ▪ WHEN OTHERS 는 마지막 절입니다 ▪ EXCEPTION 키워드는 예외 처리 부분을 시작합니다 ▪ 여러 개의 예외 처리기를 사용할 수 있습니다 ▪ 블록을 종료하기 전에 하나의 처리기만 처리합니다 암시적으로 발생
▣ 미리 정의한 Oracle Server 오류 트랩 ▪ 예외 처리 루틴에서 표준 이름을 참조합니다
▣ 미리 정의한 예외사항 ▪ 구문 BEGIN EXCEPTION WHEN NO_DATA_FOUND THEN statement1; statement2; WHEN TOO_MANY_ROWS THEN statement1; WHEN OTHERS THEN statement1; statement2 ; END ; ▪ PRAGMA EXCEPTION_INIT는 예외 이름과 오라클 오류번호를 연결하도록 컴파일러에 지시 ▪ PRAGMA : 의사 명령어로 명령문이 컴파일러 지시어임을 나타내는 키워드 DECLARE e_emps_remaining EXCEPTION ; PRAGMA EXCEPTION_INIT (e_emps_remaining, -2292) ; -- 무결성제약 v_deptno dept.deptno%TYPE := &p_deptno; BEGIN DELETE FROM dept WHERE deptno = v_deptno ; COMMIT ; EXCEPTION WHEN e_emps_remaining THEN DBMS_OUTPUT.PUT_LINE (‘Cannot remove dept ‘ || to_char(v_deptno) ); END ; ▣ 예외 트랩 함수 ▪ SQLCODE 오류 코드의 숫자 값을 반환(0: 정상 1:사용자 정의한 예외사항 100:NOT FOUND 음수:에러) ▪ SQLERRM 오류 번호와 연관된 메시지를 반환함 DECLARE v_error_code NUMBER ; v_error_message VARCHAR2(255); BEGIN … EXCEPTION …. WHEN OTHERS THEN ROLLBACK ; v_error_code := SQLCODE ; v_error_message := SQLERRM ; END ;
▣ 사용자가 정의한 예외사항 ▪ 예제 DECLARE e_invalid_product EXCEPTION; BEGIN UPDATE product SET descript = ‘&product_desc’ WHERE prodid = &product_number ; IF SQL%NOTFOUND THEN RAISE e_invalid_product ; END IF; COMMIT ; EXCEPTION WHEN e_invalid_product THEN DBMS_OUTPUT.PUT_LINE ( ‘Invalid product number.’); END ; ▣ 예외 전달 DECLARE e_no_rows exception; e_integrity exception; PRAGMA EXCEPTION_INIT (e_integrity, -2292); BEGIN FOR c_record IN emp_cursor LOOP BEGIN SELECT … IF SQL%NOTFOUND THEN RAISE e_no_rows ; END IF ; EXCEPTION WHEN e_integrity THEN … WHEN e_no_rows THEN … END; END LOOP ; EXCEPTION WHEN NO_DATA_FOUND THEN … WHEN TOO_MANY_ROWS THEN … END; ▪ 현재 블록에 해당 예외처리가 없으면 예외사항 처리기를 찾을 때까지 다음 포함된 블록으로 계속해서 전달된다
▣ RAISE_APPLICATION_ERROR ▪ 구문 raise_application_error ( error_number, message [, { TRUE | FALSE } ] ) ; ▪ 사용자가 정의한 오류 메시지를 내장 하위 프로그램에서 실행하는 프로시저 ▪ 내장 하위 프로그램 실행을 통해서만 호출함 ▪ error_number : -20000 ~ -20999 까지 지정 ▪ message : 사용자가 지정하는 메시지로 최대 2048byte의 문자열 ▪ 다음 두 부분에서 사용합니다. - 실행부분 - Exception 섹션 ▪ 다른 오라클 서버 오류와 동일한 방식으로 사용자에게 오류조건을 반환함 ▪ 예제 ….. DELETE FROM emp WHERE mgr = v_mgr ; IF SQL%NOTFOUND THEN RAISE_APPLICATION_ERROR(-20202, ‘This is not a valid manager’); END IF ; ….
