Download

1 / 14
140 likes | 358 Views
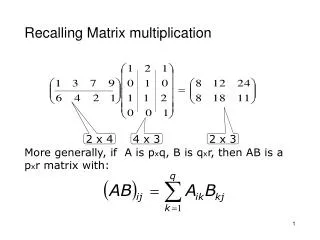
Matrix Multiplication. To make this discussion easier we will assume square matrices The product of two n by n matrices A and B is given by Note that all valid products are of the form. Sequential Matrix Multiplication. MODULE matrix1; CONST n = 3; TYPE

E N D
Matrix Multiplication • To make this discussion easier we will assume square matrices • The product of two n by n matrices A and B is given by • Note that all valid products are of the form ICSS571 - Matrix Multiplication
Sequential Matrix Multiplication MODULE matrix1; CONST n = 3; TYPE matrix = ARRAY [0..n-1],[0..n-1] OF INTEGER; VAR a,b,c : matrix; i,j,k : INTEGER; BEGIN FOR i := 1 TO n - 1 DO FOR j := 0 TO n - 1 DO c[i,j] := 0; FOR k := 0 TO n-1 DO c[i,j] := c[i,j] + a[i,k] * b[k,j]; END END END END matrix1. The complexity of this algorithm is clearly (n3). For the 3 by 3 matrix case this requires 27 multiplications Gee would’nt it be neat to do this in parallel ICSS571 - Matrix Multiplication
Dissection Time a00 a01 a02 a10 a11 a12 a20 a21 a22 b00 b01 b02 b10 b11 b12 b20 b21 b22 x = a00*b00+a01*b10+a02*b20 a00*b01+a01*b11+a02*b21 a00*b02+a01*b12+a02*b22 a10*b00+a11*b10+a12*b20 a10*b01+a11*b11+a12*b21 a10*b02+a11*b12+a12*b22 a20*b00+a21*b10+a22*b20 a20*b01+a21*b11+a22*b21 a20*b02+a21*b12+a22*b22 ICSS571 - Matrix Multiplication
Parallelize • Organize the PE grid as a N x N x N cube • Place the data in the processors so that each computes a sum for one of the Cij’s so the multiplication can be done in one step • All that is left to sum the products ICSS571 - Matrix Multiplication
Parallelize a02*b20 a02*b21 a02*b22 a12*b20 a12*b21 a12*b22 a22*b20 a22*b21 a22*b22 Sum Reduction a01*b10 a01*b11 a01*b12 a11*b10 a11*b11 a11*b12 a21*b10 a21*b11 a21*b12 a00*b00 a00*b01 a00*b02 a10*b00 a10*b01 a10*b02 a20*b00 a20*b01 a20*b02 ICSS571 - Matrix Multiplication
The Algorithm The algorithm for parallel matrix multiplication • Load the arrays into the cube • Everyone multiplies • Do a REDUCE.SUM from back to front • Result is in the front 3x3 plane of the cube ICSS571 - Matrix Multiplication
Sequential Matrix Multiplication MODULE matrix2; CONST n = 3; TYPE matrix = ARRAY [0..n-1],[0..n-1] OF INTEGER; CONFIGURATION grid [0..n-1],[0..n-1],[0..n-1]; CONNECTION front: grid[i,j,k] -> grid[0,j,k]; VAR a,b,c : grid OF INTEGER; i,j,k : INTEGER; BEGIN (* load the processor planes *) c:=a*b; SEND.front:#SUM(c,c); (* retrieve the result *) END matrix2. The complexity of this algorithm is clearly O(log2n). However, the number of processors required is O(n3) ICSS571 - Matrix Multiplication
Using Fewer Processors b22 b12 b02 b21 b11 b01 b20 b10 b00 a02 a01 a00 a12 a11 a10 a22 a21 a20 ICSS571 - Matrix Multiplication
Using Fewer Processors b22 b12 b02 b21 b11 b01 b20 b10 a02 a01 a12 a11 a10 a22 a21 a20 ICSS571 - Matrix Multiplication
Using Fewer Processors b22 b12 b02 b21 b11 b20 a02 a12 a11 a22 a21 a20 ICSS571 - Matrix Multiplication
Using Fewer Processors b22 b12 b21 a12 a22 a21 ICSS571 - Matrix Multiplication
Using Fewer Processors b22 a22 ICSS571 - Matrix Multiplication
Improving Efficiency a00*b00+a01*b10+a02*b20 a00*b01+a01*b11+a02*b21 a00*b02+a01*b12+a02*b22 a10*b00+a11*b10+a12*b20 a10*b01+a11*b11+a12*b21 a10*b02+a11*b12+a12*b22 a20*b00+a21*b10+a22*b20 a20*b01+a21*b11+a22*b21 a20*b02+a21*b12+a22*b22 b22 b12 b02 b21 b11 b01 b20 b10 b00 a02 a01 a00 a12 a11 a10 a22 a21 a20 ICSS571 - Matrix Multiplication
Improving Efficiency ICSS571 - Matrix Multiplication