Download
1 / 48
480 likes | 658 Views
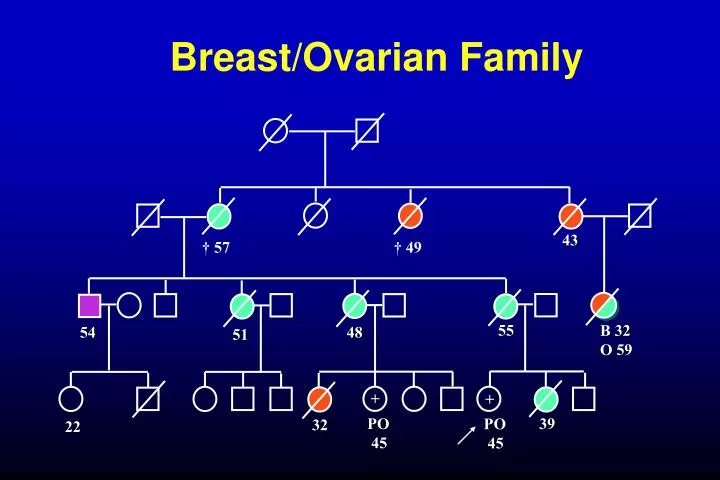
Breast/Ovarian Family. 43 . † 57 † 49. 55 . B 32 O 59. 54. 48. 51. +. +. PO 45. 39 . PO 45. 32. 22. Inherited predisposition. More BRCA-like genes Rare, moderately strong variants Common genetic variation.

E N D
Breast/Ovarian Family 43 † 57 † 49 55 B 32 O 59 54 48 51 + + PO 45 39 PO 45 32 22
Inherited predisposition More BRCA-like genes Rare, moderately strong variants Common genetic variation
Role of normal genetic variation in determining individual risk. How useful is this information in selection for screening and prevention? How do we find the genes? Breast cancer as an example
Evidence that genetic variation affects risk Measure of variation = familial clustering Risk in close blood relative compared to risk in population as a whole = roughly 2-fold.
Is family clustering genetic? Incidence % per year MZ twin 1.31 DZ twin 0.5 Mother/sister 0.36 Patient’s contralateral breast 0.66 (Peto & Mack, Nat Genet 26, 411 (2000))
How much genetic predisposition is there? How is it distributed? Determines potential for discriminating individual risks risk
Breast/Ovarian Family 43 † 57 † 49 55 B 32 O 59 54 48 51 + + PO 45 39 PO 45 32 22
Familial clustering of breast cancer OBS EXP Excess 177 106 71 13 1.47 11.5 Population BRCA1/2 mutation Fraction of excess familial clustering attributable to BRCA1/2 = 15-20%
Familial clustering of breast cancer Roughly 15-20% due to BRCA1/2 ATM Chk-2 Ha-ras PTEN Risk to 1o relative of case 2 Excess familial risk 1
What sort of genes may account for familial risk apart from BRCA1/2? Common low-penetrant genes BRCA3 etcBRCA1, 2 1.510 Relative risk Allele freq. XsFRR Number Allele freq. XsFRR Number 1% .25 3500.2% 16 5 10% 2.3 35 30% 5.3 16
Patterns of breast cancer in families 1500 cases, population based BRCA1/2 excluded What model fits best?
Best fit = combined result of several factors, individually of small effect = log-normal distribution of risk in population.
Distribution of genotypes inpopulation and cases by genotype risk 0.040 SD = 1.2 0.030 Population Cases 0.020 0.010 0.000 0.01 0.10 1.00 10.00 100.00 Relative risk
Proportion of population and cases above specified risk: SD = 1.2 1 0 0 % 88% C a s e s P o p u l a t i o n Proportion above given risk (x) 5 0 % 46% 10% 0 % 3% 12% 0 % 2 0 % 4 0 % 6 0 % 8 0 % Risk of breast cancer by age 70
Effects of normal genetic variation on breast cancer risks Population 10% 50% Cancers 46% 12% Individual risk by age 70 > 1 : 8< 1 : 30
Proportion of population and cases above specified risk: SD = 0.8 1 0 0 % 80% C a s e s P o p u l a t i o n Proportion above given risk (x) 5 0 % 31% 10% 0 % 4% 11% 0 % 2 0 % 4 0 % 6 0 % 8 0 % Risk of breast cancer by age 70
Proportion of population and cases above specified risk: SD = 0.3 Proportion above given risk (x) Risk of breast cancer by age 70
Gail model of breast cancer risk Nurses Health Study Analysis Excellent prediction of breast cancer incidence in specified population. Poor prediction of risk to individual. 2.8-fold between upper and lower deciles cut-off for tamoxifen use defined 33% of population with 44% of cases. (Rockhill, JNCI 93, 358 (2001))
- find genes - interactions - validation 1/5 1/5 40x risk
Association studies arg cys C T V indirect direct linkage disequilibrium Problems: recombination origins different time multiple origins
Common variant : common disease Rare variants Marker Disease allele
Candidate genes Estrogen synthesis and degradation; ER Cell cycle checkpoints DNA repair TGFb pathway IGF pathway Carcinogen metabolism
Sample sets Initial : 2000 cases, 2000 controls Confirmatory : 2000 cases, 2000 controls Cases - Population based, East Anglia simple epidemiology data, survival; paraffin blocks Controls - EPIC cohort, East Anglia extensive epidemiological data, follow-up, serum, mammography, bone density, etc
Percentage polygenic variance explained. 90% power p = 10-4 multiplicative 6000 5000 4000 1% 2% Sample size 3000 5% 2000 10% 1000 0 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 Allele Frequency Power (Antoniou & Easton, submitted)
Provisional positive associations : breast cancer 98 snps 47 candidate genes Risk Br Ca Fraction to age 70 of excess Freq OR PAF (5.7%) RR TGFb 14% 1.25 2.9% 6.8% 0.2% BRCA2 7% 1.31 2.1% 7.4% 0.3% XRCC3 15% 1.34 4.4% 7.4% 0.5% ERa 20% 1.27 5% 6.8% 0.5% Chk2 0.5% 2.4 0.6% 16% 0.5% ~2.0%
BRCA2 N372H association with breast cancer risk Finns HH HDB HH UK set 3 HH UK set 2 HH UK set 1 HH Joint HH p=0.02 Joint NH Joint NN 0.1 10 1
OR breast cancer CYP17 t -34 c (cc Vs. tt) Tee et al. In prep. 3133 Fiegelson et al. 2001 Haiman et al. 1999 1081 Mitrunen et al. 2000 Kristensen et al. 1999 Spurdle et al. 2000 744 Miyoshi et al. 2000 Conclusion: This SNP has no main effect on breast cancer risk! Kuligina et al. 2000 Hamajima et al. 2000 310 Huang et al. 1999 Helzlouler et al. 1998 230 Weston et al. 1998 Bergman-Jungestrom et al. 1999 226 Young et al. 1999 Ye & Parry, 2002 Mutagenesis 17:119-126 N Weston et al. 1998 0.1 1 10 100
Why a p value of p = 0.01 is not persuasive True False associationassociation Prior probability of result (snp causing 1% of FRR, 100,000 snps in genome) 1/1000 999/1000 Probability given result has p = 0.01 99/100 1/100 99/100,000 999/100,000 Assuming random choice of ‘candidate’ gene only ~ 10% results at p = 0.01 are true (~50%, at p = 0.001)
Summary of results 96 snps, 47 genes ~2000 cases, 2000 controls 0.001 p = 0.01/0.0004 for comparison of distributions p-value 0.01 0.05 0.10 observed chance 1.00 0 10 20 30 40 50 60 70 80 90 100 SNP
% of excess FRR explained 0.5 1 1.3 2 relative risk
Some reasons why human association studies may be difficult Inappropriate genetic models eg rare/multiple alleles Regulatory vs coding polymorphisms Numbers : inadequate statistical power Genetic background effects; interactions weak ‘main effect’, high-order interactions ‘null’ result = balance of susceptible and resistant on different BG Phenotypic heterogeneity eg ER+/ER-; histology Cancer/no cancer endpoint lacks power
Intermediate phenotypes Serum estradiol and CYP19Exon 10 t>c 3’UTR Serum SHBG and SHBGExon 8 g>a or D356N 20 60 18 50 16 40 14 30 12 10 20 tt tc cc gg ga aa P homogeneity = 0.0005P trend <0.0001 P homogeneity = 0.006P trend = 0.006 (Ponder, Dowsett labs; EPIC; unpublished)
Implications for breast cancer risk 2 fold increase in estradiol 30% increase in risk of breast cancer tt genotype of CYP19c>t associated with 14% increase in estradiol: equivalent to 1.04 fold increase in breast cancer risk
Where next? Empirical vs candidate approaches Snp genotyping now ~17c/genotype : ? screen 600 “enriched” cases/600 controls vs 1150 coding snps ~$240,000
Candidate gene approaches Candidates from cell biology Epidemiology Regulatory variants Quantitative phenotypes Leads from mouse models
Mouse/human collaborations 1. Candidate susceptibility genes/regions mapped in susceptible/resistant crosses refined by amplicons/deletions in tumours allele-specific differences in expression/somatic change (easier in mouse because extended haplotypes) loci involved in control of gene regulation loci influencing intermediate phenotypes set up large cross and score multiple phenotypes
How tightly should the region be defined? 300 kb Say 5 genes First pass = find all coding region snps at >5% Construct haplotypes, select minimum snp set = ? 30 snps Genotype 30 snps in 2000 cases/2000 controls = 120,000 genotypes Genotyping cost ~$20,000 @ 17c/genotype BUT : currently requires ~1000 snps at a time
Mouse/human collaborations 2. Interactions Identification of interacting loci potentially approachable in mouse Develop and evaluate programmes to search for higher order interactions; ? applicability to man
Mouse/human collaborations 3. Stages of cancer development ? Distinguish loci that influence multiplicity latency; progression invasion metastasis and resistance to these ? Loci that affect treatment response
Mouse/human collaborations 4. “End game” - which is the active gene, snp? strain comparisons of variants dissection of complex QTLs transgenic models
A new horizon in medicine? “‘Risk factor’ analysis will facilitate environmental modification, screening and therapeutic management of people before they develop symptoms” (Bell, BMJ 1998) “Differences in social structure, lifestyle and environment account for much larger proportions of disease than genetic differences …… Those who make medical and scientific policies ….. would do well to see beyond the hype” (Holtzman & Marteau, NEJM 2000)
Strangeways Research Laboratories - University of Cambridge Bruce Ponder Doug Easton Paul Pharoah Antonis Antoniou UCSF Alison Dunning Mitul Shah Allan Balmain Fabienne Lesueur Julian Lipscombe Mandy Toland Bettina Kuschel Joe Gray Annika Auranen Nick Day; EPIC Mark Sternlicht Katie Healey NCI Craig Luccarini Kent Hunter Jenny He Louise Tee Biochemistry, Cambridge Gary Dew Jim Metcalfe Cancer Research UK; MRC
TGFb Pro/Leu t/c -509 10 PP vs LL OR 1.25 (1.1 - 1.4) p = 0.01 tt vs cc OR 1.30 (1.1 - 1.5) p = 0.01 tP 0.25 0.11 0.60 cP cL
Which SNP is the functional variant? tt ProPro Pro10 homozygotes have increased risk regardless of c-509t genotype ct ProPro cc ProPro ct LeuPro cc LeuPro cc LeuLeu 0.1 1.0 10 Odds Ratio
TGFbin vitro secretion Time Course End Point 4 Pro10 3 Ratio P:L TGFb1 ng/ml 2 Leu10 1 0 0 6 12 18 hours CMV-P CMV-L CMV-L+ßgal CMV-P+ßgal CMV-E+ßgal untransfected cells CMV-L+CMV-E CMV-P+CMV-E (Metcalfe, Ponder labs, 2002)
Funnel Plot For TGFb L10P OR (PP Vs. LL) N 4517 ABC 875 HDB 939 Finn Hishido et al. 404 * * Cohort study 146 cases 2929 controls Ziv et al. 3075 Frei 238 0.1 1 10