Download

1 / 51
510 likes | 789 Views
英文連續語音辨識之初步研究 An Initial Study on English Continuous Speech Recognition. 指導教授:陳柏琳博士 研究生:許庭瑋 陳冠宇 中華民國 九十六 年 七 月 十三 日. 大綱. 簡介 基本語音辨識流程 當前英文語音辨識研究的發展 本論文使用之英文音素定義與辨識用詞典 詞內三連音素狀態分享之聲學模型建立 台師大大詞彙連續語音辨識器 研究內容與實驗 前端語音特徵擷取探討 語言模型調適 聲學模型訓練 實驗語料介紹、設定、結果 結論與未來展望.

E N D
英文連續語音辨識之初步研究An Initial Study on English Continuous Speech Recognition 指導教授:陳柏琳博士 研究生:許庭瑋 陳冠宇 中華民國 九十六 年 七 月 十三 日
大綱 • 簡介 • 基本語音辨識流程 • 當前英文語音辨識研究的發展 • 本論文使用之英文音素定義與辨識用詞典 • 詞內三連音素狀態分享之聲學模型建立 • 台師大大詞彙連續語音辨識器 • 研究內容與實驗 • 前端語音特徵擷取探討 • 語言模型調適 • 聲學模型訓練 • 實驗語料介紹、設定、結果 • 結論與未來展望
MFCC, LDA, HLDA, MLLT, CMS, CMVN 詞二連、詞三連語言模型調適 詞內三連音素狀態分享之聲學模型 基本語音辨識流程 • 語音訊號段落: • 對應文字詞序列: Bayes Theory p(O) 省略
當前英文語音辨識研究簡介 • 目前國外發展語音辨識器之學術單位、科技公司與機構
當前英文語音辨識研究簡介(續) • 語音評比語料: • 2002年3月開始,美國國際電腦科學組織 (International Computer Science Institution , ICSI)的語音研究團隊著手進行美國國防部先進研究計畫機構(DARPA)委託的EARS (Effective Affordable Reusable Speech-to-text Program)計畫,設計適當的評比語料,供辨識器研究者做測試。如大量轉寫文字(Rich Transcription)的評比語料:RT03、RT04 • 語音訓練語料: • 美國語言資料協會(Linguistic Data Consortium, LDC)提供有關於Switchboard、Switchboard Cellular及Callhome等語音語料。在EARS計畫中,就有幾千小時的語音資料來自於LDC,這些語料被稱為費雪集合(Fisher Collection)
當前英文語音辨識研究簡介(續) • 國外三家現階段大詞彙連續語音辨識器之內容特色
當前英文語音辨識研究簡介(續) • 國外三家現階段大詞彙連續語音辨識器之內容特色
本論文使用之英文音素定義與辨識用詞典 • 英文音素定義 • 40個相異單連音素分成6大類 • 再加入代表靜音(silence)的sil和代表字與字之間暫停(pause)的sp
本論文使用之英文音素定義與辨識用詞典(續) • 英文詞典:選自美國發音之Festlex CMU,共有105,626個英文詞彙 … ("begin" nil (((b ih g) 0) ((ih n) 1))) … ("coffee" nil (((k aa f) 1) ((iy) 0))) … ("hello" nil (((hh ax l) 0) ((ow) 1))) … ("yes" nil (((y eh s) 1))) … … begin b ih g ih n … coffee k aa f iy … hello hh ax l ow … yes y eh s … 經前處理後之Festlex CMU詞典 原Festlex CMU詞典
(Hidden Markov Model) (Gaussian Mixture Model) 英文音素之隱藏式馬可夫聲學模型 • 以單連音素ax為例 1維高斯分佈圖 2維高斯分佈圖 高斯分佈:平均值 (mean)共變異矩陣(Covarience Matrix) (對角化假設) (39維)
英文詞句:We were away with William in Sea World 對應單連音素:w iy w er… …s iy w er l d 三連音素 三連音素 英文詞句 單連音素對應 三連音素詞內內文相依 Hello World hh ax l ow w er l d hh+ax hh-ax+l ax-l+ow l-ow w+er w-er+l er-l+d l+d 詞內三連音素狀態分享之聲學模型建立 內文相依 (Context dependence)
詞內三連音素狀態分享之聲學模型建立(續) • 主要四步驟: • 建立單連音素聲學模型 • 由單連音素模型建立三連音素模型 • 建立狀態分享之三連音素模型 • 增加三連音素模型之高斯混合數目
1. 建立單連音素聲學模型 (40種)
2.由單連音素模型建立三連音素模型 40*40*40 =64000(種)產生資料稀疏問題(Data Sparseness)
3. 建立狀態分享之三連音素模型 • 利用模型間的狀態(State)分布做連結(Tying) • 以樹為基礎之分群法(Tree-based Clustering) • 步驟 1 : • 將所有訓練語料的三連音素模型的每個狀態依據條件置於根(Root)群集中
[2] [3] [4] 3. 建立狀態分享之三連音素模型(續) • 步驟 2 : 自定分裂決策樹之問題條件,建立決策樹(Decision Tree) : 問題條件 決策樹
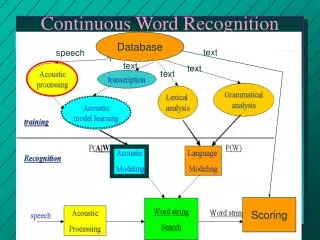
台師大大詞彙連續語音辨識器 • 聲學比對 – 將音素及語句中每個可能的段落做比對,計算 相似度語言解碼 – 使用Viterbi動態規劃搜尋,對聲學相似度和語 言機率進行解碼,找出機率最大的可能詞序列 • 二階段解碼過程 • 第一階段(聲學比對):詞彙數複製搜尋(Tree-Copy Search) • 用較低階的語言模型(詞二連Bigram)來搜尋,以產生詞圖 • 第二階段:詞圖重新評分(Word Graph Rescoring) • 在詞圖上用較高階的語言模型(詞三連Trigram)重新搜尋
前端語音特徵擷取探討 • 語音強健性技術 : 消除通道雜訊(Channel Effects) • 倒頻譜平均消去法(CMS) • 倒頻譜正規化法(CMVN) :降低不同維度間的語音特徵機率分布的差異 • 資料相關線性特徵轉換:進ㄧ步降低維度並找出較具代表性或鑑別力的特徵 • 線性鑑別分析(LDA) • 異質性線性鑑別分析(HLDA) • 最大化相似度線性轉換(MLLT)
前端語音特徵擷取探討 • 線性鑑別分析(LDA)︰統計訓練資料,找出特徵空間中重要的基底矩陣 ,使轉換後的特徵能保有重要的成份或具有較高的鑑別力。缺點為假設各類別分布的變異量相同,資料經轉換後各類別的共變異矩陣非對角化, 造成後端HMM估測失真。 • 類別間變異量愈大 (共變異矩陣以B表示) • 類別內變異量愈小 (共變異矩陣以W表示) • 異質性線性鑑別分析(HLDA):假設各類別分布的變異量為異質性 • 最大化相似度線性轉換(MLLT) :保留矩陣維度,使轉換後類別的共變異矩陣對角化 , ,
前端語音特徵擷取探討(續) • 基礎語音特徵擷取 • 梅爾倒頻譜係數(MFCC) • 梅爾倒頻譜係數配合倒頻譜平均消去法 (MFCC+CMS) • 梅爾倒頻譜係數配合倒頻譜正規化法 (MFCC+CMVN) • 鑑別式特徵擷取 • 線性鑑別分析配合最大相似度線性轉換加上倒頻譜正規化法 (LDA+MLLT+CMVN) • 異質性線性鑑別分析配合最大相似度線性轉換加上倒頻譜正規化法 (HLDA+MLLT+CMVN)
語言模型調適 • 語言模型調適法 • 背景語料 • 大量語料,涵蓋許多領域和主題,可從中訓練一般性的自然語言規則 • 調適語料 • 調適背景語言模型,和辨識任務相關的語料 • 方法: • 詞頻數混合法(Count Merging) • 模型插補法(Model Interpolation)
其中 是詞 的歷史詞序列 語言模型調適(續) • 語言模型調適法 • 方法: • 詞頻數混合法(Count Merging) : Data level 結合-CA表在調適語料中出現的次數-CB表在背景語料中出現的次數 • 模型插補法(Model Interpolation) : Model level 結合
聲學模型訓練 • 三連音素聲學模型 • 音素模糊矩陣 • 非監督式聲學模型訓練 • 信心度評估
三連音素聲學模型 • HMM狀態中,依據每個HMM模型所分配到訓練語料段落數,分配1至128個不等的高斯混合數目
刪除 取代 插入 相符 相符 音素模糊矩陣 • 利用英文辨識器之第二階段辨識結果,與正確轉寫文字做單連音素、三連音素之比對,統計發生「取代」的個數,利用音素模糊矩陣(Confusion Matrix)法統計並正規化(Normalized)容易辨識錯誤的個數。 • 聲學模型訓練階段 (觀測單連音素變化) • 辨識器搜尋階段 (觀測三連音素變化) • 兩個音素之間的模糊機率(Likelihood) • 音素 「取代」(Substitution)成 的次數正規化值,以 表示,其中 且 正確單連音素: w iy w eh …辨識單連音素: w w aw ae … 模糊矩陣示意圖
實驗語料介紹 • 語音語料 • 台灣腔英語(EAT) • 麥克風語料 (取樣頻率為16 KHz) • 依英語系、非英語系與男、女性別做分類 • 語料內容有英文單字、片語、數字與單字連續語音 • 美國之音(VOA) • 廣播新聞語料(取樣頻率為16 KHz) • 男、女聲主播、受訪者 • 語料內容有新聞時事、專題節目、英語教學節目、流行音樂與社論 • 文字語料 • 英國國家文字語料庫 (BNC) • 達約一億個詞(102M)有關說、寫的文字語料庫 • 語料包含90%各領域新聞期刊、學術書籍等文字資料;10%會議或廣播新聞等對話資料
實驗設定 • EAT語料 • VOA語料
三連音素聲學模型實驗結果 • VOA語料 Feature : MFCC_CMSLanguage Model :BNC+VOA(1:1) 討論:高斯混合數增加,對辨識率的改變並不大,可能原因為高斯混合數的分配比例是依據訓練語料量增加,又因為訓練語料量不足,故模型中存在資料稀疏問題,使辨識率下降。
三連音素聲學模型實驗結果(續) • EAT語料 Feature : MFCC_CMSLanguage Model: EAT 討論:高斯混合數依規則分配時,詞正確率由40.55%提升至49.53% ,然而增加至規則的4倍時,辨識率卻些微下降。
語言模型調適法實驗結果 • VOA語料 • 詞頻數混合法(Count Merging) Feature: MFCC_CMSMixtures: 76,073 (依規則) 討論:BNC語料不僅包含與VOA統計特性較相關的會議或廣播新聞等文字語料,且BNC語料內容更為豐富,故加入BNC語料能讓詞正確率提高。
語言模型調適法實驗結果(續) • EAT語料 • 詞頻數混合法(Count Merging) Feature: HLDA+MLLT+CMVNMixtures: 26,548 討論:EAT語料中大多為英文單字、片語或數字連續語音,而BNC為開會或是廣播新聞等對話資料,故EAT與BNC語料的統計特性差異較大。
語言模型調適法實驗結果(續) • VOA語料 • 線性插補法(Model Interpolation)
前端語音特徵擷取探討實驗結果 • VOA語料 規則*1 Language Model :BNC+VOA(1:1)
前端語音特徵擷取探討實驗結果(續) • EAT語料 規則*1 Language Model: EAT 討論︰MFCC較MFCC_CMS與MFCC_CMVN詞正確率低,代表 EAT語料之通道效應(Channel Effects)非常嚴重。
信心度評估法 • 信心度評估法是用於判斷辨識結果的可靠度,給辨識結果一個分數(ex.0~1之間的實數值),我們再設定一個門檻值,選出大於門檻值的語料和原本的語料重新訓練。 • 研究指出,非監督式的模型經多次迭代訓練後,可以得到較佳的聲學模型!-迭代:即將現有人工轉寫語料的聲學模型對未轉寫的語料做一次辨 識,再將第一名的辨識結果和現有的人工轉寫語料再次訓練 聲學模型 • 實作時,先求得每個詞句的信心度,再利用viterbi求得第一名的詞序列,而利用先訂好的門檻值來決定詞序列中某個詞是否拿來作聲學模型訓練! • 論文中,我們僅挑選信心度是1的句子來做訓練
:詞圖中的一條完整路徑 :表聲學相似度 :表語言模型 信心度評估法(續)
聲學模型的訓練方式 • 監督式訓練(Supervised Training) • 輕微監督式訓練(Lightly Supervised Training) • 非監督式訓練 • (Unsupervised Training) How are you How are you ?
非監督式聲學模型訓練 • 訓練語料的量越多,對聲學模型的訓練會越有幫助 • 因為可以看到更多以前所沒有看過的語音特徵 • 在語料隨手可得的今天,我們卻沒有辦法很容易地提升自動語音辨識器的效能,因為通常我們所收集到的大量語料是不具有正確轉寫文字(True Transcription) • 這時便可以利用現有的自動語音辨識器去辨識大量未轉寫的語料,省去大量人工轉寫的力氣,以達成非監督式模型訓練
非監督式聲學模型訓練(續) • 非監督式最大化相似度聲學模型訓練 • 並搭配信心度評估方法來過濾可能辨識錯誤的詞段 和正確答案比較 詞正確率:57.84 和正確答案比較 詞正確率:51.73 和正確答案比較 詞正確率:58.20
實驗設定 • EAT語料之非監督式聲學模型訓練
非監督式聲學模型訓練實驗結果 • EAT語料非監督式訓練之詞正確率 討論︰將大量辨識結果全用,詞正確下降。然而利用信心度評估法,可選出信心度較高的語句,對詞正確率有提升效果。
非監督式聲學模型訓練實驗結果(續) • EAT語料非監督式訓練之詞正確率上界
音素模糊矩陣實驗結果 • 聲學模型訓練階段 (觀測單連音素) • EAT測試語料,門檻值設定為0.2 ,單連音素模糊矩陣變異狀況。
音素模糊矩陣實驗結果(續) • 辨識器搜尋階段 (觀測三連音素) • 將三連音素模糊矩陣挑選門檻值大於 值以上的結果,代入英文辨識器,重新計算每個時間點每個狀態的機率值,以 表示, 代表原本三連音素M之狀態機率值所佔比例 • 使用大量EAT語料進行辨識。將其辨識結果與正確轉寫文字比對,建立ㄧ般化(General)模糊矩陣,再將此矩陣應用於辨識階段 • 使用大量EAT語料進行辨識。利用信心度評估法, 挑選適當語句,再與正確轉寫文字比對,建立ㄧ般化模糊矩陣,再將此矩陣應用於辨識階段 α= *
音素模糊矩陣實驗結果(續) • EAT語料ㄧ般化模糊矩陣之詞正確率 討論:使用ㄧ般化模糊矩陣能夠讓詞辨識率提高,配合信心度評估,更能得到較佳詞正確率。
結論 • 本論文初步研究嘗試英文連續語音辨識,我們實作英文連續語音辨識器,並探討其主要組成,包含語音特徵擷取、聲學模型及語言模型等之改進方法。 • VOA與EAT實驗語料最佳設定與詞正確率
未來展望 • 增加聲學模型之訓練語料量,提高三連音素之訓練資料出現次數,以減少資料稀疏問題。 • 豐富語言模型訓練語料,並使用其他層次的語言資訊,如詞類別、語意等。 • 增加系統辨識速度。 • 使用鑑別式聲學模型訓練,如最小化音素錯誤(Minimum Phone Error, MPE)訓練,以提高模型辨識率。 • 探討是否EAT語料中台灣英語發音差異,而導致辨識率下降。