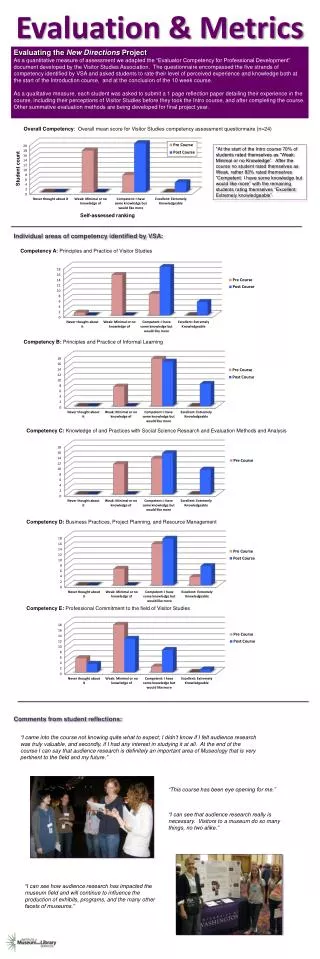
Download

1 / 8
90 likes | 126 Views
Brief talk about popular evaluation metrics in Continual Learning

E N D
Evaluation Protocols and Metrics for Continual Learning Andrea Cossu andrea.cossu@continualai.org
What to monitor https://arxiv.org/pdf/1812.00420.pdf Performance on current step Performance on past steps Performance on future steps Resource consumption ● Memory / CPU / GPU / Disk usage Model size growth (with respect to the first model) Execution time Data efficiency
CL Metrics three simple ones Average accuracy on the current step ● Standard Machine Learning → if you can’t learn, forgetting has no meaning Average Accuracy among all previous steps ( + the current step) ● It usually decreases over time → forgetting ● It can increase in presence of backward transfer learning Average Accuracy among all steps (past + present + future) ● Take into consideration forward transfer learning
CL Metrics three popular ones We have trained the model sequentially on T steps ACC (Average Accuracy) After training on step T, average accuracy over all steps BWT (Backward Transfer) Accuracy on step i after training on step T – accuracy on step i after training on step i Averaged over all steps FWT (Forward Transfer) Accuracy on step i after training on step i-1 – accuracy on step i at model initialization Averaged over all steps i without including the first one Lopez-Paz, Ranzato - GEM for CL: https://arxiv.org/pdf/1706.08840.pdf
The wild world of CL There are all sort of crazy ways to measure performance of a CL strategy Must have: general metrics about efficiency, computational cost, ability to remember previous tasks Should have: metrics tailored to the specific contribution like FWT, BWT, data efficiency (Learning Curve Area based on the b- shot performance) Lesort et. al. CL for robotics: https://arxiv.org/pdf/1907.00182.pdf
A note on streaming / online CL Minibatch size = 1 (or very small), training epochs = 1 The concept of step still applies! ● Each sample belongs to a specific step… ● … but each sample could represent a separate step Model must be updated after each sample Data efficiency is key in online learning
Training vs. Test – The CL way Do not test on training set : ML = Declare the use of task labels at test time : CL (also at training time) Multi-head ● Separate output layer for each task / step ● Task / step label at test time → select the appropriate head ● Strong assumption for CL → state it clearly!! Single-head ● Single, expanding output layer → no knowledge of task / step label at test time