Download

1 / 35
350 likes | 696 Views
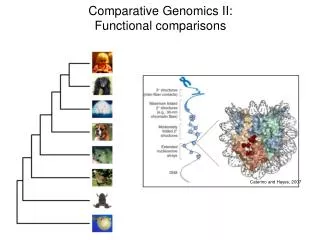
Genome Analysis II Comparative Genomics. Jiangbo Miao Apr. 25, 2002 CISC889-02S: Bioinformatics. Why Comparative Genomics ?. It tells us what are common and what are unique between different species at the genome level.

E N D
Genome Analysis IIComparative Genomics Jiangbo Miao Apr. 25, 2002 CISC889-02S: Bioinformatics
Why Comparative Genomics ? • It tells us what are common and what are unique betweendifferent species at the genome level. • Genome comparison may be the surest and most reliableway to identify genes and predict their functions andinteractions. – e.g., to distinguish orthologs from paralogs • The functions of human genes and other DNA regions canbe revealed by studying their counterparts in lowerorganisms.
Outline • All-against-all Self-comparison of Proteome • Between-proteome Comparisons • Family and Domain Analysis • Ancient Conserved Regions (ACRs) • Horizontal Gene Transfer • Functional Classification of Genes • Gene-order Comparisons
All-against-all Self-comparison • How? • Making a database of the proteome • Use each protein as a query in a similarity search against the database (BLAST, WU-BLAST or FASTA) • Generate a matrix of alignment scores (P or E value) : A conservative cutoff E value : 10e-6 • Why? • Number of Gene Families This comparison distinguishes unique proteins from proteins arisen from gene duplication, and also reveals the # of gene families. • Paralogs Significantly matched pairs of protein sequences may be paralogs.
Cluster Analysis • To sort out relationships among all of the proteins found to be related in the above search. • Clustering organizes the proteins into groups by some objective criterion: • P or E value ( < 0.01-0.05) • Distance between each pair of sequences in a multiple seq. alignment (# of amino acid changes between the aligned seq.) • Methods: • By Making Sub-graphs • By Single Linkage
Clustering by making subgraphs • Each protein sequence is a vertex; • Each matched pair of sequences with a significant score is joined by an edge • The edges are weighted according to the P/E value • Simple Algorithm: Remove weaker links (From the weakest one) • Rubin et al. (2000) • Edges of E value > 10-6 are removed • Remaining subgraphs comprise sequences that share a significant relationship to each other but not to other seq. • Criterion: the group should mutually share >= 2/3 of all of the edges from this group to all proteins in the proteome : This algorithm favors the selection of proteins with the same domain structure reflecting that these proteins are most probably paralogs
Clustering by single linkage • Based on the distance criterion • A group of related sequences found in the all-against-all proteome comp. is subjected to a MSA (CLUSTALW). • A distance matrix is made • Use this matrix to cluster the sequence by a neighbor-joining algorithm (the same procedure as that used to make a phylogenetic tree) • Cluster representation: Tree or Dendrogram • As smaller groups are chosen, the most strongly supported clusters are more likely to be made up of paralogs(?)
Core Proteome • All-against-all comparison reveals the # of protein/gene families in an organism. • This number represents the core proteome of the organism from which all biological functions have diversified. * In Hemophilus, 1247 out of 1709 proteins do not have paralogs * Core proteome of the multicellular organisms is only twice that of yeast
Outline • All-against-all Self-comparison of Proteome • Between-proteome Comparisons • Family and Domain Analysis • Ancient Conserved Regions (ACRs) • Horizontal Gene Transfer • Functional Classification of Genes • Gene-order Comparisons
Between-Proteome Comparisons : Why? • To identify orthologs, gene families, and domains • Orthologs: (proteins that share a common ancestry & function) • A pair of proteins in two organisms that align along most of their lengths with a highly significant alignment score. • These proteins perform the core biological functions shared by the two organisms. • Two matched sequences (X in A, Y in B) may not be orthologs (Y and Z are paralogs in B, X and Z are orthologs) • Identify true orthologs • highest-scoring match (best hit) • E value < 0.01 • > 60% alignment over both proteins
Between-Proteome Comparisons: How? • Choose a yeast protein and perform a database similarity search of the worm proteome (WU-BLAST): a yeast-versus-worm search • Group the worm seqs that match the yeast query seq with a high P value (10-10 to 10-100), also include the yeast query seq in the group • From the group made in 2, choose a worm seq and make a search of the yeast proteome, using the same P limit • Add any matching yeast seq to the group made in 2 • Repeat 3 & 4 for all initially matched seqs in the group • Repeat 1-5 for every yeast protein • As 1-6, perform a comparable worm-versus-yeast search • Coalesce the groups of related seqs. and remove any redundancies so that every sequence is represented only once. • Eliminate any matched pairs in which less than 80% of each seq is in the alignment
Between-Proteome Comparison: Result * The sequences also align to 80%, so they represent highly conserved sets of genes
Cluster of orthologous group (COG) • Motivation In the above database search, A protein seq will not only match the orthologous seq in the second proteome, but also those paralogous seqs of the orthologous seq. • Objective To identify all matching proteins as an orthologous group related by both speciation (ortholog) and gene duplication (paralog) events. • Meaning COGs usually correspond to classes of metabolic function • Application (example) • Produce a COG database by analysis of microbial & yeast genomes • Search a newly identified microbial protein in this database • Significant match will provide an indication of its metabolic function
Comparison of Proteome to EST database • Why? • For many organisms(Eukaryotic), complete genome seq not available • While a large collection of EST seqs are available • An EST database of an organism can also be analyzed for the presence of gene families, orthologs, and paralogs. • e.g. a protein from the yeast or fly proteome can be used as a query of a human EST database • (translate EST seq in all six possible reading frames) • Problem EST seqs are usually short( the equivalent of 100-150 amino acids) • Solution • identify overlapping EST seq : a longer alignment can be produced • perform an exhaustive search for a protein family
Search for orthologs to a protein family in EST database • [Retief et al. (1999)] Use FAST-PAN to scan EST database with multiple queries from a protein family, sorts the alignment scores, and produces charts and alignments of the matches found. • Example • Protein family: glutathione transferase proteins • Mammalian EST database • TFASTY3 search system • Shown are matches of two mouse ESTs to a query seq
Search for orthologs to a protein family in EST database • A large number of known glutathione transferase proteins was first subjected to MSA, and a phylogenetic tree was made to identify classes of proteins within the family • The object was to choose class representatives result Class Flow chat Search
Outline • All-against-all Self-comparison of Proteome • Between-proteome Comparisons • Family and Domain Analysis • Ancient Conserved Regions (ACRs) • Horizontal Gene Transfer • Functional Classification of Genes • Gene-order Comparisons
Family and Domain Analysis • What is domain? • Proteins are modular & often comprise separate domains • Domains represent modules of structure and function • Domain Comparison • Comparison of the domain content of a proteome with that of another proteome reveals the biological roles of diverse domains in different organisms. • Example : an analysis of fly, worm, & yeast proteomes • 744 families and domains were common to all three org. • > 2000 fly & worm proteins are multidomain proteins (1/3 in yeast)
Ancient Conserved Regions (ACRs) • What is ACR? In some phylogenetically diverse groups of organisms, there are conserved proteins or protein domains that have been conserved over long periods of evolutionary time. • How to find ACRs? • Database similarity search of the SwissProt database with human, worm, yeast and E. coli genes • Identify matches with sequence from a different phylum than the query sequence • The number of ACRs may be estimated by the proportion of genes that match database sequence of known function e.g. 70% prokaryotic genomes contain ACRs
Horizontal Gene Transfer • Horizontal Transfer (HT) the acquisition of genetic material from a different organism and these transferred material then becomes a permanent addition to the recipient (HT is a significant source of genome variation for bacteria) • Comparisons of bacterial genomes reveal that they are mosaics of ancestral (vertical) and horizontally transferred seqs. • 12.8% of the genome of E. coli is due to HT DNA (the highest level) • How to detect HT? • Fact: each genome of bacterial species has a unique base composition • HT can be detected as an island of seq with different composition • If the amino acid composition of transferred genes is typical, these islands may be detected by a codon usage analysis • The time of the transfer may be estimated by the degree of “blend”
Outline • All-against-all Self-comparison of Proteome • Between-proteome Comparisons • Family and Domain Analysis • Ancient Conserved Regions (ACRs) • Horizontal Gene Transfer • Functional Classification of Genes • Gene-order Comparisons
Functional Classification of Genes • Genes that are significantly similar in an organism, i.e., paralogous seqs, frequently are found to have a related biological function. • Classification Scheme • Eight related groups of E. coli genes: enzymes, transport elements, regulators, membranes, structural elements, protein factors, leader peptides, and carriers. 90% of E. coli genes fell into these same broad categories • Special Commission, e.g. Enzyme Commission of (IUBMB) provides a kind of detailed classes based on the biochemical reactions they catalyze • Examine relationships among multiple enzymes that perform the same biochemical function in the same organism. (these enzymes showed variations in metabolic regulation of their activity)
Outline • All-against-all Self-comparison of Proteome • Between-proteome Comparisons • Family and Domain Analysis • Ancient Conserved Regions (ACRs) • Horizontal Gene Transfer • Functional Classification of Genes • Gene-order Comparisons
Gene Order Comparison • Observations about gene order • Gene order is highly conserved in closely related species but becomes changed by rearrangements over evolutionary time • Groups of genes that have a similar biological function tend to remain localized in a group or cluster • Chromosomal Rearrangement • Occasional chromosomal breaks (random chromosomal location) • Random rejoining of the fragments by a DNA repair mechanism • Rearrangement Analysis • By comparing the location of orthologs
Computational Analysis of Genome Rearrangements • Challenges • The number and types of rearrangements that have occurred • When they occurred? • Example: a comparison of human and mouse chromosomes • Computational Approach • Genome alignment • Alignment reduction : reconstruct the number and types of rearrangement
Computational Analysis of Genome Rearrangement Human chromosomes were cut into > 100 pieces and reassembled into a reasonable facsimile of the mouse chromosome.
A B A B Computational Analysis of Gene Rearrangement • Lines indicate homologous position • The more rearrangements there are, the more intersections will occur • [Sankoff & Goldstein(1989)] devised a shuffling model for estimating the # of rearrangements given the # of intersections. Circular
Computational Analysis of Gene Rearrangement Assume that those rearrangements have occurred by some transposition or recombination events And identify the rearrangements by “undoing” those events. The goal is to minimum the number of rearrangements, which represents a genetic distance between the two genome sequences
Clusters of Genes on Chromosomes • In a given organism, genes are found in a given order that is maintained on the chromosomes. • On the other hand, genes with a related function are frequently found to be clustered at one chromosome location • Example : tryptophan genes in different prokaryotic organisms • Observation: • At least some of the trp genes are also clustered together on the chromosomes of other species of Bacteria & Archaea • The order of genes within the cluster is conserved within the first four species (bacteria) • The order is much less conserved in the last three species (Archaea) • Gene fusions, which generate a new protein that performs both biochemical functions of the single-gene, parent proteins.
Cluster of Genes on Chromosomes • How to identify those clusters or coordinately regulated genes? [Overbeek et al. (1999)] • Perform a full reciprocal search between the proteomes of two org. • Protein pairs that gave a best hit with the other genome & had an E value < 10-5 were identified, called a bidirectional best hit (BBH) • Pairs of close BBH (PCBBH) that are within 300 bp of each other on the chromosomes of the respective organisms and that are transcribed from the same strand, i.e., are in a “typical” operon, were then identified • A score for these pairs was formulated. When the # of organisms in which the pair is observed is greater and the phylogenetic distance between the organisms is larger, this score is higher : 40% of these pairs with higher score correspond to proteins that are known to act in a common metabolic pathway. A significant proportion of the pairs of PCBBH correspond to genes that have a related function and lie on the same pathway.