Download

1 / 26
270 likes | 604 Views
2.3 Measures of Central Tendency. Mean , median, and mode Weighted mean of a data set and the mean of a frequency distribution Shape of a distribution as symmetric, uniform, or skewed. Mean. The mean of a data set is the sum of the data entries divided by the number of entries.

E N D
2.3 Measures of Central Tendency Mean, median, and mode Weighted mean of a data set and the mean of a frequency distribution Shape of a distribution as symmetric, uniform, or skewed
Mean The mean of a data set is the sum of the data entries divided by the number of entries. Population mean: Sample mean: The lowercase Greek letter µ (pronounced mu) represents the population mean and (read as “x bar”) represents the sample mean. Note that N represents the number of entries in a population and n represents the number of entries in a sample. Recall that the uppercase Greek letter sigma (Σ) indicates a summation of values.
Try it yourself 1 • Finding a Sample Mean The heights (in inches) of the players on the 2009-2010 Cleveland Cavaliers basketball team are listed. What is the mean height? Height of Players 74 78 81 87 81 80 77 80 85 78 80 83 75 81 73 The mean height of the players is about 79.5 inches.
Median The median of a data set is the value that lies in the middle of the data when the data set is ordered. The median measures the center of an ordered data set by dividing it into two equal parts. If the data set has an odd number of entries, the median is the middle data entry. If the data set has an even number of entries, the median is the mean of the two middle data entries.
Try it yourself 2 • Finding the Median The ages of a sample of fans at a rock concert are listed. Find the median age. 24 27 19 21 18 23 21 20 19 33 30 29 21 18 24 26 38 19 35 34 33 30 21 27 30 The median age of the sample of fans at the concert is 24.
Try it yourself 3 • Finding the Median The prices (in dollars) of a sample of digital photo frames are listed. Find the median price of the digital photo frames. 25 100 130 60 140 200 220 80 250 97 The median price of the sample of digital photo frames is $115.
Mode The mode of a data set is the data entry that occurs with the greatest frequency. A data set can have one mode, more than one mode, or no mode. If no entry is repeated, the data set has no mode.
Bimodal If two entries occur with the same greatest frequency, each entry is a mode and the data set is called bimodal.
Try it yourself 4 • Finding the Mode The prices (in dollars per square foot) for a sample of South Beach (Miami Beach, FL) condominiums are listed. Find the mode of the prices. 324 462 540 450 638 564 670 618 624 825 540 980 1650 1420 670 830 912 750 1260 450 975 670 1100 980 750 723 705 385 475 720 The mode of the prices for the sample of South Beach, FL condominiums is $670.
Try it yourself 5 • Finding the Mode In a survey, 1000 U.S. adults were asked if they thought public cellular phone conversations were rude. Of those surveyed, 510 responded “Yes,” 370 responded “No,” and 120 responded “Not Sure.” What is the mode of the responses? (Adapted from Fox TV/Rasmussen Reports) In this sample, there were more people who thought public cell phone conversations were rude than people who did not or had no opinion. Mode is “Yes.”
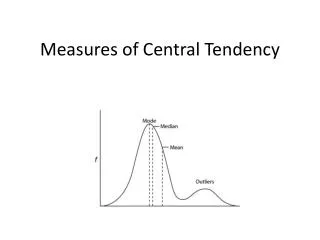
Outlier An outlier is a data entry that is far removed from the other entries in the data set.
Comparing the Mean, the Median, and the Mode Find the mean, the median, and the mode of the sample ages of students in a class shown below. Which measure of central tendency best describes a typical entry of this data set? Are there any outliers?
Comparing the Mean, the Median, and the Mode Mean: 23.7 Median: 22 Mode: 20 Interpretation: The mean takes every entry into account but is influenced by the outlier 65. The median also takes every entry into account, and it is not affected by the outlier. In this case the mode exists, but it doesn’t appear to represent a typical entry.
Try it yourself 6 • Comparing the Mean, the Median, and the Mode Remove the data entry 65 from the data set in the previous example. Then rework the mean, median, and mode. How does the absence of this outlier change each of the measures? Mean: 21.6 Median: 21.5 Mode: 20 The mean in the previous example (23.8) was heavily influenced by the entry 65. Neither the median nor the mode was affected as much by this entry.
Weighted Mean A weighted mean is the mean of a data set whose entries have varying weights. A weighted mean is given by where w is the weight of each entry x.
Finding a Weighted Mean You are taking a class in which your grade is determined from five sources: 50% from your test mean, 15% from your midterm, 20% from your final exam, 10% from you computer lab work, and 5% from your homework. Your scores are 86 (test mean), 96 (midterm), 82 (final exam), 98 (computer lab), and 100 (homework). What is the weighted mean of your scores? If the minimum average for an A is 90, did you get an A?
Finding a Weighted Mean You weighted mean for the course is 88.6. So, you did not get an A.
Try it yourself 7 • Finding a Weighted Mean An error was made in grading your final exam. Instead of getting 82, you scored 98. What is your new weighted mean?
Mean of a frequency distribution The mean of a frequency distribution for a sample is approximated by where x and f are the midpoints and frequencies of a class, respectively.
The mean age of the 50 richest people is approximately 65.3. Try it yourself 8 • Finding the Mean of a Frequency Distribution Use a frequency distribution to approximate the mean age of the 50 richest people.
Symmetric A frequency distribution is symmetric when a vertical line can be drawn through the middle of a graph of the distribution and the resulting halves are approximately mirror images.
Uniform A frequency distribution is uniform (or rectangular) when all entries, or classes, in the distribution have equal or approximately equal frequencies. A uniform distribution is also symmetric.
Skewed left/Skewed right A frequency distribution is skewed if the “tail” of the graph elongates more to one side than to the other. A distribution is skewed left (negatively skewed) if its tail extends to the left. A distribution is skewed right (positively skewed) if it tail extends to the right.