Download

1 / 36
360 likes | 477 Views
Microarray data repositories. Mark Lambrecht The Arabidopsis Information Resource http://www.arabidopsis.org. Bioinformatics : process. Bioinformatics is involved in storing managing integrating retrieving analysing biological data; genome data, gene expression, proteomic data.

E N D
Microarray data repositories Mark Lambrecht The Arabidopsis Information Resource http://www.arabidopsis.org
Bioinformatics : process • Bioinformatics is involved in • storing • managing • integrating • retrieving • analysing biological data; genome data, gene expression, proteomic data
Part I : challenges in constructing MA data repositories • Part II : Existing microarray data repositories • case study : integrating microarray information in Arabidopsis Information Resource
Goal • To store gene expression info to allow for • generation and interpretation of experimental data • integration of data in data repository • Dealing with • integrity • testing quality of data, QA (log(R/G) vs log(RG) • high-throughput • exchange of data
A trivial problem ? Organisation of data determines scope of analysis and results generated by analyses ! Organisation for a few experiments not necessary, but in case of 20, 300, 1000 MA experiments ? Organisation of data has to reflect as good as possible biological reality and thus expert bioinformaticians with core biological background needed. Most complex: integrating MA data in existing biological repository.
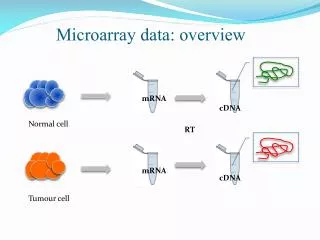
Problem 1 : generation and interpretation of experimental data • Raw data as generated by a technology platform : • oligo microarrays • cDNA microarrays • Affymetrix microarrays • Data dependent on platform (expression scales, linearity, absence of ‘interconversion’ standard)
Interpretation • Data is • redundant • non-redundant • annotation of data : manually, automatic (data cleaning step) Example : annotation of Affymetrix probe sets. • Integrated (secondary) data • composition of related data from different sources
Key challenge • Keeping track of data processing, refinement, revision • Effect of data modelling, data collection, data management infrastructure
Example : Affymetrix data platform • 12-20 probe pairs (PM, MM)/probe set • DAT file : binary image • CEL file : quantitative representation • CHP file : gene expression measurements
Example : Affymetrix platform • Raw data : probe array images (.DAT files) • Interpreted data • probe intensity data files (.CEL files) • probe set summarized data (.CHP files) • replicate summarized data • normalized data across experiments • filtered data • annotation information
Example: cDNA microarrays • EST/cDNAs are PCR amplified and attached to glass slides by automation • Example : normalization by ‘tip’ groups • Raw data generated by image analysis programs (2 channel laser scanning device) • Processed data : preclustering files (.pcl files) • NCBI Locuslink : problem of annotation of ESTs (fully-sequenced organism). • Problems : biochemical manipulations, PCR product concentration, hybr efficiency, cross-hybridization
Data review • Review, possibly correct experimental results • data : quality assessment (quality metrics : work in progress…) • technology • LIMS = laboratory information management system, validation (QC) tools, tracking systems : complex! • analyze and correct process steps, failures • interpret analysis results
Data comparability • Each MA experiment is different ; scanner used, probes, glass type, tips, hybridization conditions, etc… has to be tracked in database • Computational factors : hypothesis testing, analytic factors
Data collection : warehouse • Goals: single source expression data • Rationale : support periodic or continuous accumulation of data for effective exploration and analysis of massive amounts of data • Data structure : • central object characterized by measurement attribute • dimension object ; organized in classification hierarchies • Key challenge : applying warehouse concept to the gene expression data domain
Problem 2 : MA data integration in MA repository • Alternatives • light ; data items in autonomous repositories cross-referenced • loose : autonomous repositories accessed through common view • tight : integrated in a common data repository => resolution of semantic problems required.
Associations • Shallow : data collection and sorting • deep : determine semantic relationships
Complexity • Determined by number of data types involved in integration • Quality of data in different repositories : • example: integrate MA database with poorly described experiments in model organism database. • Key challenge: understanding the analysis and performance requirements and finding the best alternative addressing them
Problem 3 : Integrating MA data in biological data warehouse • New challenges: several sources and platforms have to be integrated (Affymetrix, cDNA spotted arrays, oligo). • Providing enhanced expression data context for analysis
Methodology • Independent data collection • different image analysis software suites • different ‘treatment’ of raw data • different analysis of treated data by software suites (Spotfire, GeneSpring, Partek, GXExplorer, Genesis, Stanford software Xcluster Treeview,…) • Statistical packages : S+, R , SAS
Methodology • Employ common formats for exporting or extracting gene expression data / sample data / gene annotation data • MAGE group : a common language to describe and exchange microarray data information, describes : • microarray design • microarray manufacturing information • microarray experiment setup • gene expression data and analysis results
Methodology : MAGE • MAGE-ML has been automatically derived from Microarray Gene Expression Object Model (MAGE-OM), which is developed and described using the Unified Modelling Language (UML) – a standard language for describing object models. • MIAME : minimum information about a microarray experiment • Use of ontologies or controlled vocabularies (too many <-> not enough), microarray ontology • Classification : e.g. aging : death to natural causes, obesitas/diabetes example
Example sample description Sample description This is an example of the information requested for a sample (biomaterial) description for a microarray experiment (kindly provided by M. Hofmann and S. Schmidtke, LION bioscience AG) with notes added by C. Stoeckert, U. Penn. Organism: mus musculus [ NCBI taxonomy browser ] Note that the source of the term "NCBI taxonomy browser" is provided. We will need to come up with a controlled vocabulary of sources and/or IDs. Cell source: in-house bred mice (contact: norma.howells@itg.fzk.de) Cell type: thymocytes (complex mixture of cells isolated from thymus. mostly T-lymphocytes and epithelial cells of different differentiation stage) [no matching for this cell type found in GXD "Mouse Anatomical Dictionary"] Note: what we are going for here is not really the type of cell but rather the type of cell source as in paraffin sample, biopsy, etc. This will be clarified in the concepts. Sex: female [ MGED ] Age: 3 - 4 weeks after birth [ MGED ] Growth conditions: normal Note the need for further structuring of this type of information. controlled environment 20 - 22 oC average temperature housed in cages according to German and EU legislation specified pathogen free conditions (SPF) 14 hours light cycle 10 hours dark cycle
Example sample description Developmental stage: stage 28 (juvenile (young) mice) [ GXD "Mouse Anatomical Dictionary" ] Organism part: thymus [ GXD "Mouse Anatomical Dictionary" ] Strain or line: C57BL/6 [International Committee on Standardized Genetic Nomenclature for Mice] Genetic Variation: Inbr (J) 150. Origin: substrains 6 and 10 were separated prior to 1937. This substrain is now probably the most widely used of all inbred strains. Substrain 6 and 10 differ at the H9, Igh2 and Lv loci. Maint. by J,N, Ola. [International Committee on Standardized Genetic Nomenclature for Mice ] Individual: - Individual genetic characteristics: the same as in "Genetic Variation" Disease state: normal Targeted cell type: primary thymocytes (complex mixture of cells isolated from thymus. mostly T-lymphocytes and epithelial cells of different differentiation stage [ no matching for this cell type found in GXD "Mouse Anatomical Dictionary"] Cell line: no cell line; primary cells Treatment: in vivo [MGED] intraperitoneal injection of Dexamethasone into mice, 10 microgram per 25 g bodyweight of the mouse Compound: drug [MGED] synthetic glucocorticoid Dexamethasone, dissolved in PBS Clinical Information: - Separation technique: mice were killed 4 hours post injection and the thymus was taken out. Thymozytes were prepared by meshing the thymus through sterile gauze several times until a suspension of individual cells was obtained. RNA was prepared from thymozytes using a Qiagen RNA preparation kit.
Data analysis in warehouse environment • Goal : focus rapidly on data set of interest (single experiment, aggregate of several experiments/replicates,…) • Mechanisms: free text search, key word search, • Exploration : • identify data of biological interest • clustering, classification • Consistent analysis and exploration • Data analysis evolves and is of secondary importance to storing data.
Outlook • Data management technology will provide continuously enhanced tools • Complexity will rise as new types of data generated appear • Expertise needed in application ; • image analysis • data modelling • data analysis : classification/statistics and data management and software • DBA, software engineering, software QA + prod.
Part II : existing microarray data repositories • NCBI Geo : • different types of expression data • Submitter • Platform • Sample • Series
Existing microarray data repositories • ArrayDB • NCGR’s GeneX • Stanford Microarray Database (SMD) (see later) They all have • clone viewers • histogram • scatter plots • analysis software as plug-ins
Attached to other data repositories • Attached to biological pathway databases • KEGG • GenMAPP http://www.genmapp.org/intro.html
Case study • Arabidopsis microarray data • AFGC : Arabidopsis functional genomics consortium • online demonstration • Describing goals of MA data repository : • use cases scenario
Usecases for an expression database • Remember : these are all functions to be provided by the MA database and interfaces ! (complex queries with DBMS could be simple for individual analysis). • General functionalities • 1. Retrieve/download all the genes that have been arrayed. • 2. Retrieve/download the genes or array elements that have been arrayed using a specific technology or manufacturer or version • 3. Return array elements/genes by gene name, locus name, nucleotide accession, Protein accession, and sequence (nucleotide and aa). • 4. Download the raw( or processed) data for one ExprHybridization. • 5. Download/retrieve the summary data for one ExpressionSet. • 6. Browse ExpressionSets (experiments).
Usecases for an expression database • Simple Queries • 7. Select an ExprHybridization and retrieve processed data for a gene by name, accession or sequence • 8. Select an ExpressionSet and retrieve summary data for a gene by name, accession or sequence. • 9. Select an experiment (ExpressionSet) and retrieve the genes that were up-/down-regulated, or varied X-fold (up or down), or uncertain, etc. • 10. Retrieve experiments (ExpressionSets) by researcher's name, keyword, germplasm, classification, experiment type (time course, treated/untreated, dose response),and/or treatment (or only experimental variable treatment) • 11. Retrieve detailed information about an experiment.
Usecases for an expression database More complex queries 12. Retrieve all the experiments in which gene X was up/down/expressed/etc. 13. Retrieve only the experiments that satisfy a given condition/s in which gene X was up/down/expressed/etc 14. Retrieve summary data for Gene X in all the experiments that satisfy a set of experimental conditions (germplasm, treatment, anatomical part, etc). 15. A user is browsing through experiments and wants a list of genes that are distinctive for a pairwise comparison, e.g. a search for auxin–upregulated or –downregulated genes. • Advanced queries • 16. Taking different samples and different genes, can the genes be divided in certain clusters. • 17. Given the expression values of gene X in an experiment, return other genes with similar expression values in the same experiment or across experiments
Practical implementation of MA repository • DBMS : Sybase • Mixture of build/buy • transact SQL ( Oracle’s procedural SQL) • analysis Spotfire /GeneSpring • Building own analysis software in Perl, Python, C • Compliant with MAGE standards / MAML