Download
1 / 1
10 likes | 178 Views
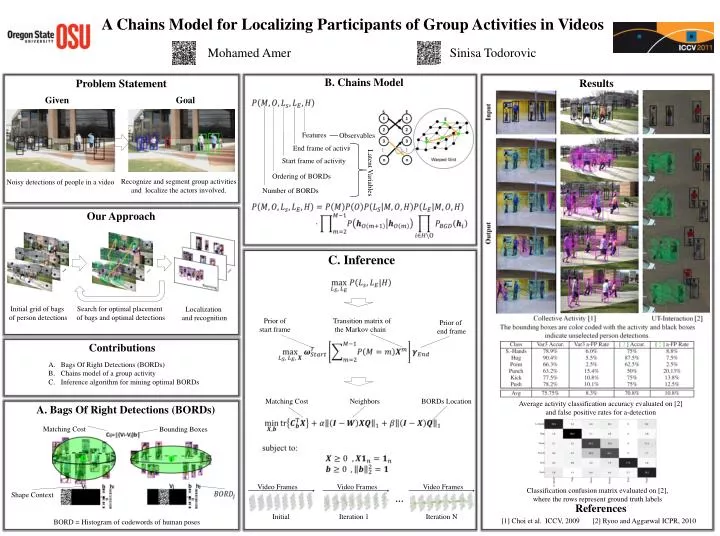
A Chains Model for Localizing Participants of Group Activities in Videos. Mohamed Amer. Sinisa Todorovic. B. Chains Model. Results. Problem Statement. Search for optimal placement of bags and optimal detections. Initial grid of bags of person detections. Localization and recognition.

E N D
A Chains Model for Localizing Participants of Group Activities in Videos Mohamed Amer Sinisa Todorovic B. Chains Model Results Problem Statement Search for optimal placement of bags and optimal detections Initial grid of bags of person detections Localization and recognition Given Goal Observables Features End frame of activity Start frame of activity Latent Variables Ordering of BORDs Number of BORDs Our Approach C. Inference Video Frames Video Frames Video Frames • Recognize and segment group activities • and localize the actors involved. • Noisy detections of people in a video Prior of start frame Transition matrix of the Markov chain Prior of end frame Contributions • Bags Of Right Detections (BORDs) • Chains model of a group activity • Inference algorithm for mining optimal BORDs Average activity classification accuracy evaluated on [2] and false positive rates for a-detection • A. Bags Of Right Detections (BORDs) Matching Cost BORDs Location Neighbors Matching Cost Bounding Boxes Classification confusion matrix evaluated on [2], where the rows represent ground truth labels Shape Context … Initial Iteration 1 Iteration N References BORD = Histogram of codewords of human poses [1] Choi et al. ICCV, 2009 [2] Ryoo and Aggarwal ICPR, 2010





