Download

1 / 51
510 likes | 675 Views
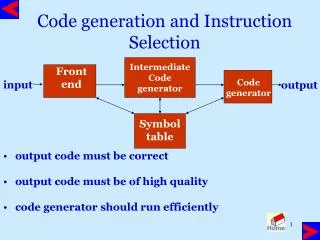
Instruction Selection. Mooly Sagiv Schrierber 317 03-640-7606 Wed 10:00-12:00 html://www.math.tau.ac.il/~msagiv/courses/wcc.html. Already Studied. Source program (string). lexical analysis. Tokens. syntax analysis. Abstract syntax tree. semantic analysis. Abstract syntax tree.

E N D
Instruction Selection Mooly Sagiv Schrierber 317 03-640-7606 Wed 10:00-12:00 html://www.math.tau.ac.il/~msagiv/courses/wcc.html
Already Studied Source program (string) lexical analysis Tokens syntax analysis Abstract syntax tree semantic analysis Abstract syntax tree Translate Tree IR Cannon Cannonical Tree IR
Instruction Selection • Input: • Cannonical IR • Description of translation rules from IR into machine language • Output • Machine code • Unbounded number of registers • Some prologue and epilogue instructions are missing
LABEL(l3) CJUMP(EQ, TEMP t128, CONST 0, l0, l1) LABEL( l1) MOVE(TEMP t131, TEMP t128) MOVE(TEMP t130, CALL(nfactor, BINOP(MINUS, TEMP t128, CONST 1))) MOVE(TEMP t129, BINOP(TIMES, TEMP t131, TEMP t130)) LABEL(l2) MOVE(TEMP t103, TEMP t129) JUMP(NAME lend) LABEL(l0) MOVE(TEMP t129, CONST 1) JUMP(NAME l2)
l3: beq t128, $0, l0 l1: or t131, $0, t128 addi t132, t128, -1 or $4, $0, t132 jal nfactor or t130, $0, $2 or t133, $0, t131 mult t133, t130 mflo t133 or t129, $0, t133 l2: or t103, $0, t129 b lend l0: addi t129, $0, 1 b l2
The Challenge • “Clumps” of trees can be translated into a single machine instruction MOVE lw t1, c(t2) TEMP t1 MEM BINOP PLUS TEMP t2 CONST c
Outline • The “Tiling” problem • An optimal solution • An optimum solution (via dynamic programming) • Tree grammars • The Pentium architecture • Instruction selection for Tiger • Abstract data type for machine instructions
Instruction set inthe Jouette Machine ADD ri rj + rk MUL ri rj * rk SUB ri rj - rk DIV ri rj / rk ADDI ri rj + c SUBI ri rj - c LOAD ri M[rj + c] STORE M[ri + c] rj MOVEM M[ri] M[rj]
The Tiling Problem • Cover the tree with non overlapping tiles from the tree patterns • Minimize “the cost” of the generated code
Example MOVE • Tiger input a[e] := x MEM MEM BINOP BINOP PLUS TEMP FP CONST -4 BINOP PLUS MEM TIMES TEMP te CONST 4 BINOP PLUS TEMP FP CONST -8
STORE M[ r1+ 0] r2 LOAD r2 M[FP+ -4] ADDr1r1 +r2 ADDI r2 r0+ 4 MUL r2 te * r2 LOAD r1 M[FP+ -8] MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM TIMES TEMP te CONST 4 BINOP PLUS CONST -8 TEMP FP
MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM CONST 4 TEMP te TIMES BINOP LOAD r1 M[FP+ -8] ADDI r2 r0+ 4 MUL r2 te * r2 ADDr1r1 +r2 LOAD r2 M[FP+ -4] STORE M[ r1+ 0] r2 PLUS CONST -8 TEMP FP
MOVEM M[ r1]M[ r2 ] ADDI r2 FP+ -4 ADDr1r1 +r2 ADDI r2 r0+ 4 MUL r2 te * r2 LOAD r1 M[FP+ -8] MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM TIMES TEMP te CONST 4 BINOP PLUS CONST -8 TEMP FP
MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP BINOP TEMP FP MEM TEMP te CONST 4 TIMES LOAD r1 M[FP+ -8] ADDI r2 r0+ 4 MUL r2 te * r2 ADDr1r1 +r2 ADD r2 FP+ r2 MOVEM M[ r1]M[ r2 ] BINOP PLUS CONST -8 TEMP FP
The Tiling Problem • Cover the tree with non overlapping tiles from the tree patterns • Minimize “the cost” of the generated code • Assures that every tree can be covered • Tree patterns for all the “tiny” tiles
STORE M[ r1+ 0] r2 LOAD r2 M[r2+ 0] ADDI r2 FP+ -4 ADDr1r1 +r2 LOAD r1 M[r1 +0] ADD r1 FP+ r1 ADDI r2 r0+ 4 MUL r2 te * r2 ADDI r1 r0 + -8 MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM TIMES TEMP te CONST 4 BINOP PLUS CONST -8 TEMP FP
MOVE MEM MEM BINOP PLUS TEMP FP CONST -4 PLUS BINOP BINOP ADDI r1 r0 + -8 ADD r1 FP+ r1 LOAD r1 M[r1+ 0] ADDI r2 r0+4 MUL r2 te * r2 ADDr1r1 +r2 ADDI r2 r0+ -4 ADD r2 FP+ r2 LOAD r2 M[r2+ 0] STORE M[ r1] r2 CONST 4 MEM TEMP te TIMES BINOP PLUS CONST -8 TEMP FP
Optimal vs. Optimum Tiling • Optimum Tiling • Minimum cost of tile sum • Optimal Tiling • No two adjacent tiles can be combined to reduce the cost
STORE M[ r1+ 0] r2 LOAD r2 M[FP+ -4] ADDr1r1 +r2 ADDI r2 r0+ 4 MUL r2 te * r2 LOAD r1 M[FP+ -8] MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM TIMES TEMP te CONST 4 BINOP PLUS CONST -8 TEMP FP
STORE M[ r1+ 0] r2 LOAD r2 M[r2+ 0] ADDI r2 FP+ -4 ADDr1r1 +r2 LOAD r1 M[r1 +0] ADD r1 FP+ r1 ADDI r2 r0+ 4 MUL r2 te * r2 ADDI r1 r0 + -8 MOVE MEM MEM BINOP PLUS PLUS CONST -4 BINOP TEMP FP BINOP MEM TIMES TEMP te CONST 4 BINOP PLUS CONST -8 TEMP FP
Optimum Tiling LOAD r1 M[FP+ -8] ADDI r2 r0+ 4 MUL r2 te * r2 ADDr1r1 +r2 LOAD r2 M[FP+ -4] STORE M[ r1+ 0] r2 LOAD r1 M[FP+ -8] ADDI r2 r0+ 4 MUL r2 te * r2 ADDr1r1 +r2 ADD r2 FP+ r2 MOVEM M[ r1]M[ r2 ]
Architecture and Tiling Algorithm • RISC • Cost of operations is uniform • Optimal tiling usually suffices • CISC • Optimum tiling may be significantly better
Optimal Tiling using “Maximal Munch” • Top-down traversal of the IR tree • At every node try the relevant tree patterns in “cost-order” • Generate assembly code in reverse order • Tiny tiles guarantees that we can never get stack
static void munchStm(T_stm s) { switch(s->kind) { case T_MOVE: T_exp dst = s->u.MOVE.dst, src=s->u.MOVE.src; if (dst->kind==T_MEM) if (dst->u.MEM->kind==T_BINOP && dst->u.MEM->u.BINOP.op==T_PLUS && dst->u.MEM->u.BINOP.right.kind==T_CONST) { T_exp e1 =dst->u.MEM->u.BINOP.left, e2=src; /* MOVE(MEM(BINOP(PLUS, e1, CONST c,), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); } else if (dst->u.MEM->kind==T_BINOP && dst->u.MEM->u.BINOP.op==T_PLUS && dst->u.MEM->u.BINOP.left.kind==T_CONST) { T_exp e1 =dst->u.MEM->u.BINOP.right, e2=src; /* MOVE(MEM(BINOP(PLUS, CONST c, e1), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); }
static void munchStm(T_stm s) { switch(s->kind) { case T_MOVE: T_exp dst = s->u.MOVE.dst, src=s->u.MOVE.src; if (dst->kind==T_MEM) if (… ) { /* MOVE(MEM(BINOP(PLUS, e1, CONST c,), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); } else if (…) { /* MOVE(MEM(BINOP(PLUS, CONST c, e1), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); } else if (src->kind==T_MEM) { T_exp e1= dst->u.MEM, e2=src->u.MEM; /* MOVE(MEM(e1), MEM(e2)) */ munchExp(e1), munchExp(e2); emit(“MOVEM”) ; } else { T_exp e1=dst->u.MEM, e2=src; /* MOVE(MEM(e1), e2) */ munchExp(e1), munchExp(e2); emit(“STORE”) ; }
case T_MOVE: T_exp dst = s->u.MOVE.dst, src=s->u.MOVE.src; if (dst->kind==T_MEM) if (… ) { /* MOVE(MEM(BINOP(PLUS, e1, CONST c,), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); } else if (…) { /* MOVE(MEM(BINOP(PLUS, CONST c, e1), e2) */ munchExp(e1); munchExp(e2); emit(“STORE”); } else if (…) { /* MOVE(MEM(e1), MEM(e2)) */ munchExp(e1), munchExp(e2); emit(“MOVEM”) ; } else { /* MOVE(MEM(e1), e2) */ munchExp(e1), munchExp(e2); emit(“STORE”) ; } else if (dst->kind==T_TEMP) { T_exp e=src; /* MOVE(TEMP t, e) */ munchExp(e); emit(“ADD”); } else assert(0);
static void munchStm(T_stm s) { MOVE(MEM(BINOP(PLUS, e1, CONST c), e2) munchExp(e1); munchExp(e2); emit(“STORE”); MOVE(MEM(BINOP(PLUS, CONST c, e1), e2) munchExp(e1); munchExp(e2); emit(“STORE”); MOVE(MEM(e1), MEM(e2)) munchExp(e1), munchExp(e2); emit(“MOVEM”) ; MOVE(TEMP t, e) munchExp(e); emit(“ADD”); JUMP(e) … CJUMP(e) … LABEL(l) }
static void munchExp(T_exp e) { MEM(BINOP(PLUS, e, CONST c)) munchExp(e); emit(“LOAD”); MEM(BINOP(PLUS, CONST c, e1) munchExp(e); emit(“LOAD”); MEM(CONST c) emit(“LOAD”); MEM(e) munchExp(e); emit(“LOAD”); BINOP(PLUS, e, CONST c) munchExp(e); emit(“ADDI”); BINOP(PLUS, CONST c, e) munchExp(e); emit(“ADDI”); BINOP(CONST c) munchExp(e); emit(“ADDI”); BINOP(PLUS, e1, e2) munchExp(e1; munchExp(e2); emit(“ADD”); … TEMP t
Example MOVE • Tiger input a[e] := x MEM MEM BINOP BINOP PLUS TEMP FP CONST -4 BINOP PLUS MEM TIMES TEMP te CONST 4 BINOP PLUS TEMP FP CONST -8
Optimum Tiling • Maximal munch does not necessarily produce optimum results • The number of potential code sequences is quite big • But Dynamic Programming yields an optimum solution in linear time • Assign optimum cost to every sub-tree • Two phase solution • Find the optimum cost for every subtree in a bottom up traversal • Generate the optimum solution in a top down traversal • Skip subtrees
Dynamic Programming • For each subtree with root n • For each tile t which matches n of cost c • Calculate the cost of t as: c + ci • The cost of the subtree rooted at n is the minimum of all matching tiles • Generate the optimum code during top-down traversal
Example MEM BINOP PLUS CONST 1 CONST 2
BINOP BINOP e PLUS PLUS CONST 1 CONST 2 BINOP PLUS e2 e1 CONST C BINOP CONST c e PLUS
MEM BINOP PLUS CONST 2 CONST 1
MEM e MEM BINOP e2 e1 PLUS MEM BINOP e CONST c PLUS MEM BINOP CONST c PLUS e
Top-Down Code Generation LOAD(2) MEM ADDI(2) BINOP PLUS CONST 2 CONST 1 ADDI(1) ADDI(1) ADDI r1r0 + 1 LOAD r1 M[r1 + 2]
The “Schizo”-Jouette Machine • In the spirit of Motorola 68000 • Two types of registers • data registers • address registers • Arithmetic performed on data registers • Load and Store using address registers • Machine instruction to convert between addresses and data
Tree Grammars • A generalization of dynamic programming • Input • A (usually ambiguous) context free grammar describing the machine tree patterns • non-terminals correspond to machine types • every production has machine cost • A linearized IR tree • Output • A parse-tree with the minimum cost
d TEMP t a TEMP t d +(d, d) d +(d, CONST) d +(CONST, d) d MEM(+(a, CONST)) d MEM(+(CONST, a)) d MEM(CONST) d MEM(a) d a a d Partial Grammar for Schizo-Jouette MEM(+(CONST 1, CONST 2))
Six general purpose registers The multiply requires that the left arg. is eax Two-address instructions Arithmetic on memory Several addressing modes Variable-length instructions Instructions with side-effects Good register allocation For t1 t2 * t3 mov eax, t1 mul t2 mov t3, eax For t1 t2 + t3 mov t1, t2 add t1, t3 add [ebp –8], ecx mov eax, [ebp –8] add eax, ecx mov [ebp-8], eax Simple Instruction-Selection in the Pentium Architecture
Instruction-Selection in the Tiger Compiler • Use maximal munch • Store the generated code in an abstract data type • The following phases are machine-independent • Control flow of the program is explicitly represented • Special representation of MOVE • Register allocation can remove
/* assem.h */ typedef struct {Temp_labelList labels;} AS_targets; AS_targets AS_Targets(Temp_labelList labels); typedef struct AS_instr_ *AS_instr; typedef enum {I_OPER, I_LABEL, I_MOVE} AS_instr_kind; struct AS_instr_ { AS_instr_kind kind; union {struct {string assem; Temp_tempList dst, src; AS_targets jumps;} OPER; struct {string assem; Temp_label label;} LABEL; struct {string assem; Temp_tempList dst, src;} MOVE; } u; }; AS_instr AS_Oper(string a, Temp_tempList d, Temp_tempList s, AS_targets j); AS_instr AS_Label(string a, Temp_label label); AS_instr AS_Move(string a, Temp_tempList d, Temp_tempList s);