Download

1 / 23
410 likes | 2.11k Views
Reliability and Validity of Research Instruments. An overview. Measurement error. Error variance--the extent of variability in test scores that is attributable to error rather than a true measure of behavior. Observed Score=true score + error variance

E N D
Reliability and Validity of Research Instruments An overview
Measurement error • Error variance--the extent of variability in test scores that is attributable to error rather than a true measure of behavior. Observed Score=true score + error variance (actual score obtained) (stable score) (chance/random error) (systematic error)
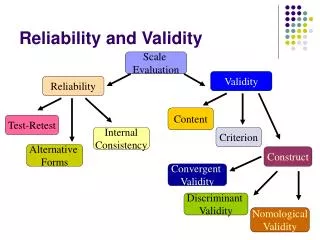
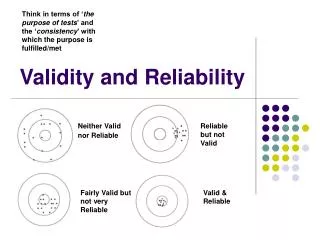
Validity • The accuracy of the measure in reflecting the concept it is supposed to measure.
Reliability • Stability and consistency of the measuring instrument. • A measure can be reliable without being valid, but it cannot be valid without being reliable.
Validity • The extent to which, and how well, a measure measures a concept. • face • content • construct • concurrent • predictive • criterion-related
Face validity • Just on its face the instrument appears to be a good measure of the concept. “intuitive, arrived at through inspection” • e.g. Concept=pain level • Measure=verbal rating scale “rate your pain from 1 to 10”. Face validity is sometimes considered a subtype of content validity. Question--is there any time when face validity is not desirable?
Content validity • Content of the measure is justified by other evidence, e.g. the literature. • Entire range or universe of the construct is measured. • Usually evaluated and scored by experts in the content area. • A CVI (content validity index) of .80 or more is desirable.
Construct validity • Sensitivity of the instrument to pick up minor variations in the concept being measured. Can an instrument to measure anxiety pick up different levels of anxiety or just its presence or absence? Measure two groups known to differ on the construct. Ways of arriving at construct validity • Hypothesis testing method • Convergent and divergent • Multitrait-multimatrix method • Contrasted groups approach • factor analysis approach
Concurrent validity • Correspondence of one measure of a phenomenon with another of the same construct.(administered at the same time) Two tools are used to measure the same concept and then a correlational analysis is performed. The tool which is already demonstrated to be valid is the “gold standard” with which the other measure must correlate.
Predictive validity • The ability of one measure to predict another future measure of the same concept. If IQ predicts SAT, and SAT predicts QPA, then shouldn’t IQ predict QPA (we could skip SATs for admission decisions) If scores on a parenthood readiness scale indicate levels of integrity, trust, intimacy and identity couldn’t this test be used to predict successful achievement of the devleopmental tasks of adulthood? The researcher is usually looking for a more efficient way to measure a concept.
Criterion related validity • The ability of a measure to measure a criterion (usually set by the researcher). • If the criterion set for professionalism is nursing is belonging to nursing organizations and reading nursing journals, then couldn’t we just count memberships and subscriptions to come up with a professionalism score. Can you think of a simple criterion to measure leadership? Concurrent and predictive validity are often listed as forms of criterion related validity.
Reliability • Homogeneity, equivalence and stability of a measure over time and subjects. The instrument yields the same results over repeated measures and subjects. Expressed as a correlation coefficient (degree of agreement between times and subjects) 0 to +1. Reliability coefficient expresses the relationship between error variance, true variance and the observed score. The higher the reliability coefficient, the lower the error variance. Hence, the higher the coefficient the more reliable the tool! .70 or higher acceptable.
Stability • The same results are obtained over repeated administration of the instrument. • Test-restest reliability • parallel, equivalent or alternate forms
Test-Retest reliability • The administration of the same instrument to the same subjects two or more times (under similar conditions--not before and after treatment) • Scores are correlated and expressed as a Pearson r. (usually .70 acceptable)
Parallel or alternate forms reliability • Parallel or alternate forms of a test are administered to the same individuals and scores are correlated. • This is desirable when the researcher believes that repeated administration will result in “test-wiseness” Sample: ”I am able to tell my partner how I feel” “My partner tries to understand my feelings”
Homogeneity • Internal consistency (unidimensional) • Item-total correlations • split-half reliability • Kuder-Richardson coefficient • Cronbach’s alpha
Item to total correlations • Each item on an instrument is correlated to total score--an item with low correlation may be deleted. Highest and lowest correlations are usually reported. • Only important if you desire homogeneity of items.
Spit Half reliability • Items are divided into two halves and then compared. Odd, even items, or 1-50 and 51-100 are two ways to split items. • Only important when homogenity and internal consistency is desirable.
Kuder-Richardson coefficient (KR-20) • Estimate of homogeneity when items have a dichotomous response, e.g. “yes/no” items. • Should be computed for a test on an initial reliability testing, and computed for the actual sample. • Based on the consistency of responses to all of the items of a single form of a test.
Cronbach’s alpha • Likert scale or linear graphic response format. • Compares the consistency of response of all items on the scale. • May need to be computed for each sample.
Equivalence • Consistency of agreement of observers using the same measure or among alternate forms of a tool. • Parallel or alternate forms (described under stability) • Interrater reliability
Intertater reliability • Used with observational data. • Concordance between two or more observers scores of the same event or phenomenon.
Critiquing • Was reliability and validity data presented and is it adequate? • Was the appropriate method used? • Was the reliability recalculated for the sample? • Are the limitations of the tool discussed?