Download

1 / 14
140 likes | 265 Views
Good Science. Benefit to Society. Human genes claimed in granted U.S. patents Jensen and Murray, Science 310:239-240 (14 Oct. 2005).

E N D
Good Science Benefit to Society
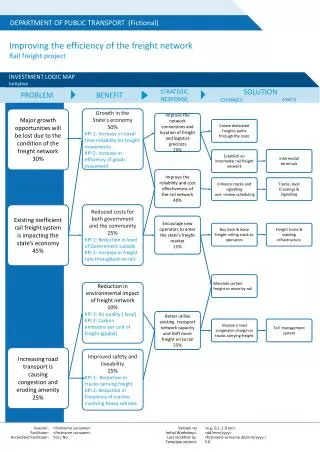
Human genes claimed in granted U.S. patents Jensen and Murray, Science 310:239-240 (14 Oct. 2005) “Specifically, this map is based on a BLAST homology search linking nucleotide sequences disclosed and claimed in granted US utility patents to the set of protein-encoding mRNA transcripts contained in the NCBI databases… …we do not consider claims on genes defined through amino acid sequences… Our results reveal that nearly 20% of human genes [in the NCBI’s gene database at the time of writing] are explicitly claimed as U.S. IP.” Chromosome 20 of the human genome each horizontal line represents a patent family
Human genes claimed in granted U.S. patents Jensen and Murray, Science 310:239-240 (14 Oct. 2005) 9% 28% 63%
Patents claiming N genes N [genes claimed in patent] Human genes claimed in granted U.S. patents 63% of human gene patents privately owned does not tell the full story…a single patent may cover thousands of genes (Incyte Pharmaceuticals has IP rights over >2000 genes) Jensen and Murray, Science 310:239-240 (14 Oct. 2005) Patents by number of unique genes claimed per patent
Don’t think plant-associated bacteria have a problem? • 703 USPTO applications and patents contain claims to DNA or amino acid sequences from or used in Pseudomonas • 304 of these are granted patents • Here’s claim 1 of a patent on DNA molecules and polypeptides of Pseudomonas syringae: 1. An isolated nucleic acid molecule comprising a nucleotide sequence which (i) encodes a protein or polypeptide comprising an amino acid sequence of SEQ. ID. No. 3, SEQ. ID. No. 5, SEQ. ID. No. 7, SEQ. ID. No. 9, SEQ. ID. No. 11, SEQ. ID. No. 13, SEQ. ID. No. 15, SEQ. ID. No. 17, SEQ. ID. No. 20, SEQ. ID. No. 22, SEQ. ID. No. 24, SEQ. ID. No. 26, SEQ. ID. No. 28, SEQ. ID. No. 30, SEQ. ID. No. 32, SEQ. ID. No. 34, SEQ. ID. No. 36, SEQ. ID. No.38, SEQ. ID. No. 40, SEQ. ID. No. 42, SEQ. ID. No. 44, SEQ. ID. No. 46, SEQ. ID. No. 48, SEQ. ID. No. 50, SEQ. ID. No. 52, SEQ. ID. No. 54, SEQ. ID. No. 56, SEQ. ID. No. 58, SEQ. ID. No. 60, SEQ. ID. No. 62, SEQ. ID. No. 64, or SEQ. ID. No. 66; or (ii) hybridizes, under stringency conditions comprising a hybridization medium which includes 0.9M SSC at a temperature of 37° C., to a DNA molecule comprising a nucleic acid sequence complementary to SEQ. ID. No. 2, SEQ. ID. No.4, SEQ. ID. No.6, SEQ. ID. No.8, SEQ. ID. No. O, SEQ. ID. No. 12, SEQ. ID. No.14, SEQ. ID. No.16, SEQ. ID. No.19, SEQ. ID. No.21, SEQ. ID. No. 23, SEQ. ID. No. 25, SEQ. ID. No. 27, SEQ. ID. No. 29, SEQ. ID. No. 31, SEQ. ID. No. 33, SEQ. ID. No. 35, SEQ. ID. No. 37, SEQ. ID. No. 39, SEQ. ID. No. 41, SEQ. ID. No. 43, SEQ. ID. No. 45, SEQ. ID. No. 47, SEQ. ID. No. 49, SEQ. ID. No. 51, SEQ. ID. No. 53, SEQ. ID. No. 55, SEQ. ID. No. 57, SEQ. ID. No. 59, SEQ. ID. No. 61, SEQ. ID. No. 63, or SEQ. ID. No. 65; or (iii) comprises a nucleotide sequence which is complementary to the nucleic acid molecules of (i) and (ii).
12,511 USPTO documents contain sequence claims and description related to uses in or by Pseudomonas • Here’s a claim from a 2002 patent appthat could soon be granted to Elitra Pharmaceuticals, for use of multifunctional bacterial replicons in inhibiting growth of Escherichia coli, Staphylococcus aureus,, Enterobacter cloacae, Helicobacter pylori, Neisseria gonorrhoeae, Enterococcus faecalis, Streptococcus pneumoniae, Haemophilus influenzae, Salmonella typhimurium, …Pseudomonas aeruginosa,… or any species falling within the genera of any of the above species. Claim: A method for inhibiting cellular proliferation comprising introducing a compound which inhibits the activity or reduces the amount of a polypeptide comprising a sequence selected from the group consisting of SEQ ID NOs. 243-357 and SEQ ID NOs. 359-398 or which inhibits the activity or reduces the amount of a nucleic acid comprising a nucleotide sequence encoding said polypeptide into a cell.
Amuse gueule from a forthcoming patent landscape analysis by CAMBIA BiOS • ...Three apps are continuations in a single application family assigned to Mendel Biotechnology, called "Polynucleotides and polypeptides in plants" which also includes continuations called "Yield related genes in plants", "environmental stress tolerance genes", etc all claiming priority to a series of 1998 "bulk sequence applications". While these 1998 applications themselves are not published, it can be inferred from the daughter applications (which by convention maintain the SEQ ID numbering) that each claimed approximately 2000 sequences, many of which did not have well-characterised functions in 1998 (that can be inferred from the reference list). CIPs have been filed as functions have become clear, and continuations are being kept alive for those for which the functions are still unclear, these three apps being examples of the latter. Check out claims 1 & 2 of the particular daughter app (US 2004/19927) that relates to transcription factors:
This is not a joke. And it is typical.Patent App US 2004/19927: Mendel Biotech What is claimed is: 1. A transgenic plant comprising a recombinant polynucleotide having a polynucleotide sequence, or a complementary polynucleotide sequence thereof, selected from the group consisting of: (a) a polynucleotide sequence encoding a polypeptide, wherein said polypeptide is selected from the group consisting of SEQ ID NO: 2N, wherein N=1-229, SEQ ID NO: 467; 488-490; 501-503; 505; 512-515; 521-522; 525-526; 528; 530; 534-537; 540; 558-559; 569; 587-594; 597; 607-609; 621-626; 635-639; 665-669; 708-713; 720-721; 736-739; 742; 780-807; 824; 835-837; 851-854; 865-867; 890-891; 903-907; 910-913; 922-923; 926; 933-934; 943; 953-960; 966-967; 987-988;994; 1011; 1035-1042; 1064-1073; 1081-1090; 1105-1110; 1122; 1129-1133; 1139-1141; 1157-1158; 1176-1186; 1191; 1200-1201; 1221-1248; 1254-1257; 1263; 1270; 1288-1291; 1302; 1310-1314; 1324-1327; 1338-1339; 1342-1343; 1362-1364; 1378; 1391-1392; 1395; 1399-1418; 1433; 1453-1454; 1457-1459; 1466-1467; 1492-1498; 1500-1501; 1503-1504; 1522; 1528; 1533-1535; 1540-1541; 1563-1566; 1572; 1583-1586; 1593-1594; 1621-1624; 1645-1646; 1655-1658; 1670; 1674; 1681; 1687; 1701-1705; 1710-1713; 1727; 1735-1737; 1743; 1754-1756; 1761-1762; 1765; 1769; 1781; 1785; 1790; 1805; 1813; 1838-1846; 1857; 1863; 1874-1875; 1883-1884; 1897-1901; 1911-1912; 1917-1920; 1929-1930; 1937-1939; 1942-1943; and SEQ ID NO: 2N, wherein N=974-1101; (b) a polynucleotide sequence encoding a polypeptide, wherein said polynucleotide sequence is selected from the group consisting of SEQ ID NO: 2N-1, wherein N=1-229, SEQ ID NO: 459-466;468-487; 491-500; 504; 506-511; 516-520; 523-524; 527; 529; 531-533; 538-539; 541-557; 560-568; 570-586; 595-596;
Claim 1 cont & claim 2. • 598-606; 610-620; 627-634; 640-664; 670-707; 714-719; 722-735; 740-741; 743-779; 808-823; 825-834; 838-850; 855-864; 868-889; 892-902; 908-909; 914-921; 924-925; 927-932; 935-942; 944-952; 961-965; 968-986; 989-993; 995-1010; 1012-1034; 1043-1063; 1074-1080; 1091-1104; 1111-1121; 1123-1128; 1134-1138; 1142-1156; 1159-1175; 1187-1190; 1192-1199; 1202-1220; 1249-1253; 1258-1262; 1264-1269; 1271-1287; 1292-1301; 1303-1309; 1315-1323; 1328-1337; 1340-1341; 1344-1361; 1365-1377; 1379-1390; 1393-1394; 1396-1398; 1419-1432; 1434-1452; 1455-1456; 1460-1465; 1468-1491; 1499; 1502; 1505-1521; 1523-1527; 1529-1532; 1536-1539; 1542-1562; 1567-1571; 1573-1582; 1587-1592; 1595-1620; 1625-1644; 1647-1654; 1659-1669; 1671-1673; 1675-1680; 1682-1686; 1688-1700; 1706-1709; 1714-1726; 1728-1734; 1738-1742; 1744-1753; 1757-1760; 1763-1764; 1766-1768; 1770-1780; 1782-1784; 1786-1789; 1791-1804; 1806-1812; 1814-1837; 1847-1856; 1858-1862; 1864-1873; 1876-1882; 1885-1896; 1902-1910; 1913-1916; 1921-1928; 1931-1936; 1940-1941; 1944-1946, and SEQ ID NO: 2N-1, wherein N=974-1101; (c) a polynucleotide sequence encoding the polypeptide sequence of (a) with conservative substitutions as defined in Table 2, wherein said polypeptide sequence of (a) with conservative substitutions is a transcription factor; (d) a variant of the polynucleotide sequences of (a) or (b), which is at least 80% identical to a sequence of (a) or (b), and wherein said sequence variant encodes a polypeptide that is a transcription factor; (e) an orthologous sequence of the polynucleotide sequences of (a) or (b), which is at least 80% identical to a sequence of (a) or (b), and wherein said orthologous sequence encodes a polypeptide; (f) a paralogous sequence of the polynucleotide sequences of (a) or (b), which is at least 80% identical to a sequence of (a) or (b), and wherein said paralogous sequence encodes a polypeptide; (g) a polynucleotide sequence encoding a polypeptide comprising a conserved domain that exhibits at least 80% sequence homology with the conserved domain of the polypeptide of (a), wherein said polypeptide comprising a conserved domain of a transcription factor; and wherein said conserved domain of (a) is bounded by amino acid residue coordinates according to Table 5; and (h) a polynucleotide that hybridizes to the polynucleotide of (a) or (b) under stringent conditions. • 2. The transgenic plant according to claim 1, wherein: the transgenic plant possesses an altered trait as compared to a non-transformed plant; or the transgenic plant exhibits an altered phenotype as compared to said non-transformed plant; or the transgenic plant expresses an altered level of one or more genes associated with a plant trait as compared to said non-transformed plant; wherein said non-transformed plant does not overexpress the recombinant polynucleotide.
Entrée (same application) • AP2 domain found in SEQ IDs 151-217, 243-296 • MADS domain found in SEQ IDs 2-57 • MYB-related 129-180 • Z-CO-like32-76 Any of you working on any of these? I’m sure the owner thanks you for adding ‘value’ to their patents.
“First Complete Plant Genetic Sequence Is Determined”Andrew Pollack in New York Times 14 Dec, 2000 • "There's thousands of applications1 coming down the pipeline," said Chris Somerville2, director of the department of plant biology at the Carnegie Institution, professor at Stanford University and an early organizer of the sequencing project. 2 "Our goal — and I say we're going to reach it in the next decade — is to understand plants like little machines. And we're going to use it to do real engineering.” 1 I guess he meant patent applications… 2 Also co-founder, Director and now CEO of Mendel
Digestif Here's a method claim from a patent granted to Mendel in 2004 (US 6,835,540): 1. A method of determining whether a member of a pool of cloned test transcription factor polynucleotides encodes a plant pathway transcription factor, the method comprising: collecting a pool of cloned test transcription factor polynucleotides; introducing into a plant cell a nucleic acid comprising a plant promoter of a pathway gene operably linked to a reporter gene; introducing into the plant cell a member of the pool of cloned test transcription factor polynucleotides, wherein said member is selected on the basis of structural similarity to a known transcription factor for a pathway gene; and detecting expression of said reporter gene in the plant cell, thereby determining whether the member of the cloned test transcription factor polynucleotide pool encodes a plant pathway transcription factor.
To date, Ceres has filed patent applications on over 50,000 full-length functionally annotated genes and over 10,000 promoter sequences.
Forthcoming patent technology landscapes (2006…we hope) • The Rice Genome • The Arabidopsis Genome • RNAi • Homologous Recombination • Transcriptional Activators • …..others?