Download

1 / 25
250 likes | 397 Views
Analysis of Cluster Failures on Blue Gene Supercomputers. Tom Hacker * Fabian Romero +. Chris Carothers. Scientific Computation Research Center Department of Computer Science Rensselaer Polytechnic Institute. Depart. Of Computer & Information Tech. * Discovery Cyber Center +

E N D
Analysis of Cluster Failures on Blue Gene Supercomputers Tom Hacker* Fabian Romero+ Chris Carothers Scientific Computation Research Center Department of Computer Science Rensselaer Polytechnic Institute Depart. Of Computer & Information Tech.* Discovery Cyber Center+ Purdue University
Outline • Update on NSF PetaApps CFD Project • PetaApps Project Components • Current Scaling Results • Challenges for Fault Tolerance • Analysis of Clustered Failures* • EPFL – 8K Blue Gene/L • RPI – 32K Blue Gene/L • Analysis Approach • Findings • Summary *To appear in upcoming issue of JPDC
NSF PetaApps: Parallel Adaptive CFD Ken Jansen (PD), Onkar Sahni, Chris Carothers, Mark S. Shephard • PetaApps Components • CFD Solver • Adaptivity • Petascale Perf Sim • Fault Recovery • Demonstration Apps • Cardiovascular Flow • Flow Control • Two-phase Flow Scientific Computation Research Center Rensselaer Polytechnic Institute Acknowledgments: Partners: Simmetrix, Acusim, Kitware, IBM NSF: PetaApps, ITR, CTS; DOE: SciDAC-ITAPS, NERI; AFOSR Industry:IBM, Northrup Grumman, Boeing, Lockheed Martin, Motorola Computer Resources: TeraGrid, ANL, NERSC, RPI-CCNI
P2 P1 P3 PHASTA Flow Solver Parallel Paradigm • Time-accurate, stabilized FEM flow solver • Two types of work: • Equation formation • O(40) peer-to-peer non/blocking comms • Overlapping comms with comp • Scales well on many machines • Implicit, iterative equation solution • Matrix assembled on processor ONLY • Each Krylov vector is: • q=Ap (matrix-vector product) • Same peer-to-peer comm of q PLUS • Orthogonalize against prior vectors • REQUIRES NORMS=>MPI_Allreduce • This sets up a cycle of global comms. separated by modest amount of work • Not currently able to overlap Comms • Even if work is balanced perfectly, OS jitter can imbalance it. • Imbalance WILL show up in MPI_Allreduce • Scales well on machines with low noise (like Blue Gene)
Parallel Implicit Flow Solver – IncompressibleAbdominal Aorta Aneurysm(AAA)fafdfafd adsf a 32K parts show modest degradation due to 15% node imbalance (with only about 600 mesh-nodes/part) Rgn./elem. ratioi = rgnsi/avg_rgns Node ratioi = nodesi/avg_nodes (Min Zhou)
Scaling of “AAA” 105M Case Scaling loss due to OS jitter in MPI_Allreduce
#of cores Rgn imb Vtx imb Time (s) Scaling 32k 1.72% 8.11% 112.43 0.987 128k 5.49% 17.85% 31.35 0.885 AAA Adapted to 109 Elements:Scaling on Blue Gene /P
ROSS: Massively Parallel Discrete-Event Simulation Local Control Mechanism: error detection and rollback Global Control Mechanism: compute Global Virtual Time (GVT) V i r t u a l T i m e V i r t u a l T i m e collect versions of state / events & perform I/O operations that are < GVT (1) undo state D’s (2) cancel “sent” events GVT LP 2 LP 3 LP 1 LP 2 LP 3 LP 1 unprocessed event processed event “straggler” event “committed” event
PHOLD is a stress-test. • On BG/L @ CCNI • 1 Million LPs (note: DES of BG/L comms had 6M LPs). • 10 events per LP • Upto 100% probablity any event scheduled to any other LP • Other events scheduled to self.
PHOLD on Blue Gene/P • At 64K cores, only 16 LPs per core with 10 events per LP. • At 128K cores, only 8 LPs per core == MAX parallelism and performance drops off significantly. • Peak performance of 12.26 billion events/sec for 10% remote case.
Challenges for Petascale Fault Tolerance • Good news with caveats… • Our applications are scaling well. • But…scaling runs are relatively short. (i.e., < 5 mins) and so don’t experience failures… • One early example… • Phasta could only run for at most 5 hours using 32K nodes before Blue Gene/L lost at least one node and whole program died… • Systems I/O bound..cannot checkpoint.. • BG/P “Intrepid” has 550+ TFlops of compute but only 55 to 60 GB/sec disk IO bandwidth using 4 MB data blocks… • At 10% of peak flops, can only do ~ 1 “double” of I/O per 8000 “double” precision FLOPS. • So we need to understand how systems fail in order to build efficient fault tolerant supercomputer systems…
Assessing Reliability on Petascale Systems Systems containing a large number of components experience a low mean time to failure Usual methods of failure analysis assume Independent failure events Exponentially distributed time between events Necessary for homogenous Markov modeling and Poisson processes Practical experience with systems of this scale show that Failures are frequently cascading Analyzing time between events in reality is difficult Difficult to put knowledge about reliability to practical use Better understanding of reliability from a practical perspective would be useful Increase reliability of large and long-running jobs Decrease checkpoint frequency Squeeze more efficiency from large-scale systems
Our approach Understand underlying statistics of failure on a large system in the field Use this understanding to attempt to predict node reliability Put this knowledge to work to improve job reliability
Characteristics of Failure Failures in large-scale systems are rarely independent singular events A set of failures can arise from a single underlying cause Network problems Rack-level problems Software subsystem problems Failures are manifested as a cluster of failures Grouped spatially (e.g., in a rack) Grouped temporally
Blue Gene We gathered RAS logs from two large Blue Gene systems (EPFL and RPI)
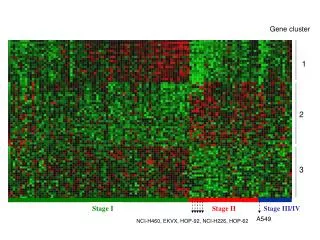
Blue Gene RAS Data Events include a level of severity INFO (least severe), WARNING, SEVERE, ERROR, FATAL, FAILURE Location and time Mapped these events into a 3D space to understand what was happening over time on the system Node address -> X axis Time of event -> Y axis Severity level -> Z axis
Assessing Events Significant spatial and temporal clustering Used cluster analysis in R to reduce clustering Time between events transformed to Weibull Needed a model to predict node reliability In practice, nodes are either Healthy and operating normally Degraded and suspect Down
Two Markov Models Accurate, but slow Continuous time Markov model Cluster analysis takes over 10 hours Less accurate, but much faster Discrete time Markov model Time step adjustable Computed in minutes
Practical Application We can use this information to guide the scheduler Rank nodes by predicted reliability High reliability – least likely to fail Low reliability – most likely to fail Assign most reliable nodes to largest queues Assign least reliable nodes to smallest queues
Summary • Our apps are scaling well on balanced hardware but have strong need to understand how failures impact performance, especially at petascale levels • Analysis of failure logs suggests failures follow a Weibull distribution. • Semi-Markov models are able to access reliability of nodes on the systems • Nodes that log a large number of RAS events (i.e., are noisy) are less reliable than nodes that log few events (i.e., < 3). • Grouping less “noisy” nodes together creates a partition that is much less likely to fail which significantly improves overall job completion rates and reduces the need for checkpointing.