Download

1 / 26
270 likes | 391 Views
Incremental Computation. AJ Shankar CS265 Spring 2003 Expert Topic. The idea. Sometimes a given computation is performed many times in succession on inputs that differ only slightly from each other

E N D
Incremental Computation AJ Shankar CS265 Spring 2003 Expert Topic
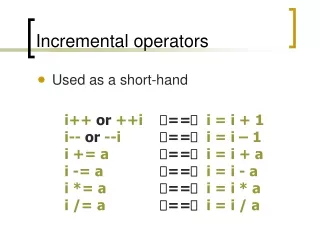
The idea • Sometimes a given computation is performed many times in succession on inputs that differ only slightly from each other • Let’s optimize this situation by trying to use the previous output of the computation in computing the current one • Iteration and recursion are special cases of “repeated computation” – so lots of gains to be had
A simple example Compute the successive sums of each m-element window in an n-element array (with m < n) for (int i = 0 ; i < n-m ; i++) { for (int j = i ; j < m ; j++) { sum[i] += ary[j]; } } This is an O(n2) algorithm.
A simple example, continued 5 Consider a four-element window. The naïve approach adds up each group of four numbers from scratch. 8 3 1 6 However, all we need to do to compute a new window is subtract the number that is leaving the window and add the number that is entering it! 9 5 4
A simple example, continued So we can incrementally compute each successive window as follows: // compute the first window from scratch for (int j = 0 ; j < m ; j++) { sum[0] += ary[j]; } // incrementally compute each successive window for (int i = 1 ; i < n-m ; i++) { sum[i] = sum[i-1] - ary[i-1] + ary[i+m-1]; } This new algorithm is O(n)!
Our goal • Let the user write natural, maintainable code • Discover repeated computations that can be “incrementalized” • Generate an incremental version of these computations that is faster than the original • Do this as automatically as possible
What this problem is not • Incremental algorithms: algorithms explicitly designed to accommodate incremental changes to their inputs. We’d like to study the automated incrementalization of existing code. • Incremental model of computation: code is rendered incremental at run-time via function caching, etc. Relies on a run-time mechanism and therefore never explicitly constructs incremental code that can be run by conventional means.
Some history • First introduced by Early in 1974 as ‘iterator inversion’ • Explored further by Paige, Schwartz, and Koenig (1977, 1982) • Very high level (sets) • Called ‘formal differentiation’ • For the first time, discussed the possible automation of the algorithm • Strength reduction • More specific notion of replacing costly operations with cheap ones (say * by +)
Incremental computation • Described in a series of papers by Yanhong Annie Liu et. al. through the 90s • First systematic approach to incrementalizing programs written in a common functional language • Proof of correctness (not covered here)
Formal definition • Let f be a program and let x be an input to f. • Let y be a change in the value of x, and let be a change operation that combines x and y to produce a new input value xy. • Let r = f(x): the result of executing f on x. • Let f’(x,y,r) be a program that computes f(xy) such that • f’ computes faster than f for almost all x and y • f’ makes non-trivial use of r • Then f’ is an incremental version of f.
An illustrative case • Let sort(x) be selection sort; it takes O(n2) time for x of length n • Let sort’(x,y,r) – where r is sort(x) –compute sort(cons(x,y)) by running merge sort on cons(x,y); takes O(n log n) time. Not incremental! • Let sort’’(x,y,r) compute sort(cons(x,y)) by inserting y in r in O(n) time. Non-trivial use of r; hence, incremental.
A general systematic transformational approach • Given f and , derive an incremental program that computes f(xy) using • The value of f(x)(Liu, Teitelbaum 1993) • The intermediate results of f(x)(Liu, Teitelbaum 1995) • Auxiliary information of f(x)(Liu, Stoller, Teitelbaum 1996) • Each successive class of information allows for greater incrementality than the previous one
P1. Using the previous result • Given f(x), introduce f’(x,y,r) • Unfold • Expand f using the definition of the operator • Simplify • Use basic rewrite rules like car(cons(a,b)) = a • Replace using cached result • Substitute r when we see f(x) in the expanded function • Eliminate dead code
An example sum(x) = if null(x) then 0 else car(x) + sum(cdr(x)) x y = cons(y, x) sum’(x,y,r) = sum(cons(y,x)) x y = cons(y, x) sum’(x,y,r) = if null(cons(y,x)) then 0 else car(cons(y,x)) + sum(cdr(cons(y,x))) x y = cons(y, x) sum’(x,y,r) = if (false) then 0 else y + sum(x) x y = cons(y, x) sum’(x,y,r) = y + r x y = cons(y, x) sum’(y,r) = y + r x y = cons(y, x) • Introduce f’ • Unfold • Simplify • Replace • Eliminate • sum(cons(y,x)) takes O(n) time • sum’(y,r) takes O(1) time and one unit of space
P2. Using intermediate results • In computing f(x), we might calculate some intermediate results that would be useful in computing f(xy) but are not retrievable from r • Recall the successive sums problem: • f(2..6) = 6 + f(2..5) // intermediate result from f(1..5) • So let’s keep track of all the intermediate results • …But there might be a ton of them!
The cache-and-prune method • Stage 1: Construct f* that extends f to return r and all intermediate results • Stage 2: Incrementalize f* to get f*’ as per P1 • Stage 3: Figure out which results are necessary and prune out the rest from f*’, yielding f^’
Our old friend, Fibonacci fib(x) = if x 1 then 1 else fib(x-1) + fib(x-2)
Fibonacci, continued • Note that the standard P1 method will not work – we still have fib(x-2) • So, cache-and-prune: • Stage 1: Construct a function that, if run, would return an exponential-sized tree • Stage 2: Incrementalize this function, noticing that both fib(x-1) and fib(x-2) can be retrieved from the cached tree • Stage 3: Remove the other unnecessary results (the rest of the tree)
Fibonacci, continued The final incrementalized version of fib(x) is fib^’(x) = if x 1 then <1,0> // pair else if x = 2 then <2,1> else let r = fib^’(x-1) in <1st(r) + 2nd(r), 1st(r)> The old fib(x) took O(2n) time, whereas this version takes O(n) time.
P3. Auxiliary information • Let’s go even further and discover information that would be useful for computing f(xy) but that is never computed in f(x) • Two-phase method: • Identify computations in f(xy) done only on x that cannot be retrieved from any existing cached data • Determine whether such information would aid in the efficient computation of f(xy); if so, compute and store it • Most of this can be done using techniques from P1 and P2, respectively
A (complicated) example cmp(x) = sum(odd(x)) prod(even(x)) x y = cons(y, x) • When we add y, the odd and even sublists are swapped – we must now take the product of what we used to sum and vice-versa • Therefore, the results (even intermediate ones) of the previous computation are useless! • So we really want to compute and save the values of sum(even(x)) and prod(odd(x)) too, which can be done with a single addition or multiplication each • This is auxiliary information (see board)
Unrolling cmp cmp(x) = sum(odd(x)) <= prod(even(x)) odd(x) = if null(x) then nil else cons(car(x), even(cdr(x))) even(x) = if null(x) then nil else odd(cdr(x)) Unroll… cmp(cons(y,x)) = sum(odd(cons(y,x))) prod(even(cons(y,x))) cmp(cons(y,x)) = sum( if null(cons(y,x)) nil else cons(car(cons(y,x)), even(cdr(cons(y,x)))) ) prod( if null(cons(y,x)) then nil else odd(cdr(cons(y,x))) )
Optimizing cmp, continued Simplify… cmp(cons(y,x)) = sum(cons(y,even(x)) prod(odd(x)) Identify even(x) and odd(x) as computations that only depend on x that can be incrementalized. cmp*(x) = let v1= odd(x), u1 = sum(v1), v2= even(x), u2 = prod(v2) in <u1 u2, u1, u2, sum(v2), prod(v1)> cmp’(y,r) = <y + 4th(r) 5th(r), y + 4th(r), 5th(r), 2nd(r), y * 3rd(r)> res sum(odd) prod(even) sum(even) prod(odd)
Further work • CACHET (1996) • An interactive programming environment that derives incremental programs from non-incremental ones • Transformations directly manipulate the program tree • Use annotations to preserve user-specified stuff and to give direction to the optimizer • Basically a proof of concept
Further work • Using incrementalization to transform general recursion into iteration (1999) • Find base and recursive cases of f • For each recursive case, identify an input increment (f(x) = 2*f(x-1))and derive an incremental version • Form the iterative program using some generic iteration constructs as appropriate
Recursion to iteration, con’t • The tail recursion optimization may in fact produce slower code than the original recursive function! • Multiplying small numbers is faster than multiplying large ones, etc. • So far we can generate an additional function that computes an incremental result given a previous result r • This work handles the inlining of the iterative computations, including the hairy bits with multiple base and recursive cases • Use associativity, loop contraction, redundant test elimination, pointer reversal