Download

1 / 66
660 likes | 833 Views
Arrays. CS101 2012.1. (1-dimensional) array. So far, each int , double or char variable had a distinct name Called “scalar” variables An array is a collection of variables They share the same name But they have different indices in the array Arrays are provided in C++ in two ways

E N D
Arrays CS101 2012.1
(1-dimensional) array • So far, each int, double or char variable had a distinct name • Called “scalar” variables • An array is a collection of variables • They share the same name • But they have different indices in the array • Arrays are provided in C++ in two ways • “Native arrays” supported by language itself • The vector type (will introduce later) • Similar: understand one, understand both Chakrabarti
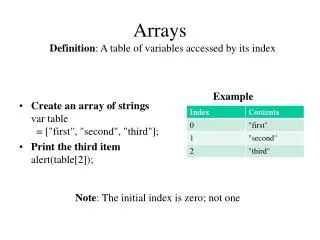
Notation • When writing series expressions in math, we use subscripts like ai, bj etc. • For writing code, the subscript is placed in box brackets, as in a[i], b[j] • Inside […] can be an arbitrary integer expression • In C++, the first element is a[0], b[0] etc. • If the array has n elements, the last element is at position n-1, as in a[n-1] • Watch against out-of-bound index errors Chakrabarti
Why do we need arrays • Print a running median of the last 1000 temperatures recorded at a sensor • Tedious to declare and use 1000 scalar variables of the form t0, t1, …, t99 • Cannot easily express a computation like “print differences between consecutive readings” as a loop computation • Want to write “ti+1 – ti” • I.e., want to access elements using index that is an integer expression Chakrabarti
Declaring a native array main() { int vn = 9; int va[vn]; for (int vx = 0; vx < vn; ++vx) { va[vx] = vx * (vn - 1 - vx); } for (int vx = 0; vx < vn; ++vx) { cout << va[vx] << ", "; } cout << endl; Number of elements in array to be created Reserve memory for 9-element array Lvalue: cell to which rhs value is to be written Note: no size() or length; hang on to vn Rvalue: access int in specified cell Chakrabarti
One 32-bit int (0) One 32-bit int (7) One 32-bit int (12) Representation in memory • Elements of array have fixed size • Laid out consecutively • Compiler associates array name va with memory address of first byte • To fetch va[ix], go to byte address A + ix*4 and fetch next four bytes as integer • A, A+4, A+8, A+12, … va starts here (address A) va[0] va[1] va[2] Chakrabarti
Sum and product of all elements double arr[an]; // fill in suitably double sum = 0, prod = 1; for (int ax = 0; ax < an; ++ax) { sum += arr[ax]; prod *= arr[ax]; } • In standard notation we would write these as Chakrabarti
Dot-product of two vectors double av[nn], bv[nn]; // filled in double dotprod = 0; for (int ix = 0; ix < nn; ++ix) { dotprod += av[ix] * bv[ix]; } Chakrabarti
Cosine of the angle between two vectors • Need to compute norms alongside dot prod double av[nn], bv[nn]; // filled in double dot=0, anorm=0, bnorm=0; for (int ix = 0; ix < nn; ++ix) { dot += av[ix] * bv[ix]; anorm += av[ix] * av[ix]; bnorm += bv[ix] * bv[ix]; } double ans =dot/sqrt(anorm)/sqrt(bnorm); Chakrabarti
Josephus problem • numPeople people stand in a circle • Say named 0, 1, …, numPeople-1 • Start at some arbitrary person (say 0) • Skip skip people • Loop back from numPeople-1 to 0 if needed • Throw out victim at next position • Repeat until circle becomes empy • Eviction order? Who survives to the end? • Need to model only two states per person: present (true) or absent (false) Chakrabarti
Josephus solution bool present[numPeople]; // initialize to all true (present) int victim = 0, numEvicted = 0; while (numEvicted < numPeople) { // Skip over skip present people // Evict victim } • Irrespective of whether victim is present or not at the beginning of the loop, • ensure that after the skip step, victim is again a present person Chakrabarti
The skip step for (int toSkip = skip; ; victim=(victim+1)%numPeople) { if (present[victim]) { --toSkip; } if (toSkip == 0) { break; } } • Note that present[victim] is true here • If skip is large, may skip over the same candidate victim many times • Note use of for without condition to check Chakrabarti
Evict step present[victim] = false; ++numEvicted; cout << "Evicted " << victim << endl; • Eviction takes constant time • victim is now absent, but next iteration’s skip step will take care of that Chakrabarti
Alternative representation • Are we wasting too much time skipping over people who have already left? • Alternative: instead of a bool array, maintain a shrinking int array with person IDs • On every eviction, squeeze out the evicted ID and reduce array size by 1 • (Allocated space remains same, we just don’t use all of it) Chakrabarti
Busy eviction 0 victim numPeople for (int cx=victim, cx<numPeople-1; ++cx) { survivors[cx] = survivors[cx+1]; } --numPeople; • Cannot just swap, because order of people in survivors must not be disturbed Chakrabarti
Skipping is now trivial • All person IDs in survivors is present by construction • So skipping is as simple asvictim = (victim + skip) % numPeople; • Takes constant time • Note that numPeople decreases by one after each eviction Chakrabarti
Time analysis • First representation (bit vector) • Skipping is messy • Evicting is trivial • Second representation (person ID vector) • Skipping is trivial • Evicting is messy (move data) • Which is better? • Depends on the goal of the computation Chakrabarti
Smallest and largest elements • Convention: for an empty array • Largest element is (minus infinity) • Smallest element is + (plus infinity) • Will show how to instantiate for all numeric types int array[an]; // suitably filled in int min = PLUS_INF, max = MINUS_INF; for(int ax=0; ax < an; ++ax){ int elem = array[ax]; min = (elem < min)? elem : min; max = (elem > max)? elem : max; } Ties? Chakrabarti
Position (index) of smallest element • Given double array[0, …, an-1] • Find index imin of smallest element • Must remember current smallest too double amin = PLUS_INF; int imin = -1; // illegal value to start for (int ax = 0; ax < an; ++ax) { if (array[ax] < amin) { amin = array[ax]; imin = ax; } } // imin holds the answer Chakrabarti
Swapping array elements • Once we find imin, we can exchange the element at imin with the element at 0double tmp = array[imin];array[imin] = array[0];array[0] = tmp; • This places the smallest element at slot 0 • Or largest, if we wish • We can keep doing this, will give us a sorted array Chakrabarti
Prefix (cumulative) sum • Given array a[0,…,n-1] • Compute array b[0,…,n-1] whereb[i] = a[0] + a[1] + … + a[i] • Nested loop works but is naïve int a[n], b[n]; // vector a filled for (int bx = 0; bx < n; ++bx) { b[bx] = 0; for (int ax = 0; ax <= bx; ++ax) { b[bx] += a[ax]; } } Time taken is proportional to n2 Chakrabarti
Prefix sum: faster • Given array a[0,…,n-1] • Compute array b[0,…,n-1] whereb[i] = a[0] + a[1] + … + a[i] int a[n], b[n]; // vector a filled for (int ix = 0; ix < n; ++ix) { b[ix] = ( b[ix-1]) + a[ix]; } a[0] a[1] a[2] a[3] b[0]=a[0] a[0]+a[1] a[0]+a[1]+a[2] ? (ix == 0)? 0 : Makes code inefficient Chakrabarti
Applications of cumulative sum • Running balance in bank account • Deposits positive, withdrawals negative • Range sum: given array, proprocess it so that, given “query” i, j, can returna[i] + a[i+1] + … + a[j] very quickly • Answer is simply b[j] – b[i-1] Chakrabarti
Merging sorted arrays • Arrays double a[m], b[n] • Repeated values possible • Each has been sorted in increasing order • Know sorting by repeated move-smallest-to-front • Output is array c[m+n] • Contains all elements of a[m] and b[n] • Including all repeated values • In increasing order • Example: a=(0, 2, 7, 8) b=(2, 3, 5, 8, 9) c=(0, 2, 2, 3, 5, 7, 8, 8, 9) Chakrabarti
Merge approach • Run two indexes ax on a[…] and bx on b[…] • Also called cursors • Choose minimum among cursors, advance that cursor • Append chosen number to c[…] ax 0 2 7 8 0 2 2 3 5 7 2 3 5 8 9 bx Chakrabarti
Merge code double a[m], b[n], c[m+n]; // a and b suitably initialized int ax = 0, bx = 0, cx = 0; while (ax < m && bx < n) { if (a[ax]<b[bx]) {c[cx++]=a[ax++];} else { c[cx++] = b[bx++];} } // one or both arrays are empty here while (ax < m) { c[cx++] = a[ax++]; } while (bx < n) { c[cx++] = b[bx++]; } Chakrabarti
Another way to sort • Earlier we sorted by finding the minimum element and pulling it out to the leftmost unsorted position • Suppose array length is a power of 2 • First sort segments of length 1 (already done) • Merge into sorted segments of length 2 • [0,1] [2,3] [4,5] [6, 7] • Merge into sorted segments of length 4 • [0, 1, 2, 3] [4, 5, 6, 7] Mergesort Chakrabarti
Mergesort picture • Recall that any location of RAM can be read/written at approximately same speed • But access to hard disk best made in large contiguous chunks of bytes • Mergesort best for data larger than RAM 35 9 22 16 17 13 29 4 9 35 16 22 13 17 4 29 9 16 22 35 4 13 17 29 4 9 13 16 17 22 29 35 Chakrabarti
Time taken by mergesort • Time to merge a[m] and b[n] is m+n • Suppose array to be sorted is s[2p] • 2p-1 merges of segments of size 1, 1 takes time 2p • 2p-2 merges of segments of size 2, 2 takes time 2p again • p merge phases each taking 2p time • So total time is p 2p • Writing N=2p, total timeis N log N, optimal! Index arithmetic and bookkeeping slightly complicated Chakrabarti
Searching a sorted array • Given array a=(4, 9, 13, 16, 17, 22) • Find the index/position of q=16 (answer: 3) • Print -1 if q not found in a • Why do we care? • E.g., income tax department database • Array pan[numPeople] (sorted) • Array income[numPeople] (not sorted) • Each index is for one person • Find index of specific PAN • Then access person’s income Chakrabarti
Searching a sorted array • Given array a=(4, 9, 13, 16, 17, 22) • Find the index/position of q=16 (answer: 3) • Print -1 if q not found in a • Linear searchfor (int ax=0; ax<an; ++ax) { if (a[ax] == q) { cout << ax; break; }}if (ax==an) { cout << -1; } • More efficient to do binary search No need to look farther because all values will be larger than q Chakrabarti
Binary search • Bracket unchecked array segment between indexes lo and hi • Bisect segment: mid = (lo + hi)/2 • Compare q with a[mid] • If q is equal to a[mid] answer is mid • If q < a[mid], next bracket is lo…mid-1 • If q > a[mid], next bracket is mid+1…hi lo hi q=16 Chakrabarti
Binary search • Terminate when lo == hi (?) • Before first halving, bracket has n candidates • After first halving, reduces to ~n/2 • After second halving, … ~n/4 • Number of halvings required is approximately log n • If array was not sorted, need to check all n • To implement, need a little care with index arithmetic • lo=2 hi=3 mid=2, lo=3 hi=4 mid=3 Chakrabarti
Binary search code int lo = 0, hi = n-1, ans=-1; while (lo <= hi) { int mid = (lo + hi)/2; if (q < a[mid]) { hi = mid-1; } if (q > a[mid]) { lo = mid+1; } if (q == a[mid]) { ans = mid; break; } } if (ans == -1) { … } If not found, common convention to return the negative form of the index where the query should be inserted Chakrabarti
Median • Given a sorted array a with n elements • By definition, median is a[n/2] or a[n/2+1] • Similarly, percentiles • What if the array is not sorted? • Trivial: first sort then find middle element • Have seen that this will take n2 or n log n time • Can we do better? • Turns out cn steps are enough for some constant c • (Complicated) Chakrabarti
Median • Given two sorted arrays a[m] and b[n], supposing their merge was c[m+n] • Goal: find median of c without calculating it (would take m+n time) • I.e., find median in much less time Lab! All items marked large are larger than all items marked small Therefore no large item can be a median Eliminates ~(m+n)/2 elements m/2 a small 20 > small 27 large b n/2 Chakrabarti
Back to mergesort index arithmetic • Assume array size N = 2pow • There are pow merge rounds • In the pxth merge round, px=0,1,…,pow-1: • There are 2pow-px sorted runs • Numbered rx = 0, 1, …, rn = 2pow-px • Each run has 2px elements • rxth run starts at index rx * 2px • And ends at index (rx+1)* 2px (excluded) • Merge rxth and (rx+1)th runs for rx=0, 2, 4, … Demo Chakrabarti
Bottom up mergesort • Start with solutions to small subproblems, then combine them to form solutions of larger subproblems • Eventually solving the whole problem 35 9 22 16 17 13 29 4 9 35 16 22 13 17 4 29 9 16 22 35 4 13 17 29 4 9 13 16 17 22 29 35 Chakrabarti
Top down expression • To mergesort array in positions [lo,hi) … • If hi == lo then we are done, otherwise … • Find m = (lo + hi)/2 • Mergesort array in positions [lo, m) • Recursive call • Mergesort array in positions [m, hi) • Recursive call • Merge these two segments Chakrabarti
vector • A vector can hold items of many types • Need to tell C++ compiler which type • Declare as vector<double> oneArray;vector<int> anotherArray; • Very similar to string in other respects • array.resize(10); // sets or resets size • array.size() // current number of elements • foo = array[index]; // reading a cell • array[index] = value; // writing a cell Chakrabarti
Initialization vector<int> array; const int an = 10; array.resize(an); for (int ax = 0; ax < an; ++ax) { array[ax] = ax * (an – ax); } • Usually, arrays are read from data files Chakrabarti
Advantages of using vector • Can store elements of any type in it • E.g. vector<string> firstNames; • Memory management is handled by C++ runtime library • Can grow and shrink array after declaration • But there’s more! • Sorting is already provided • So is binary search • And many other useful algorithms Demo Chakrabarti
Sparse arrays • Thus far, our arrays allocated storage for each and every element • Sometimes, can’t afford this • E.g. documents • Represented as vectors ina very high-dimensional space • One axis for each word inthe vocabulary, which couldhave billions of tokens • Most coordinates of most docs are zeros logic dog cat Chakrabarti
Example • A corpus with only two docs • my care is loss of care • by old care done • Distinct tokens: 0=by 1=care 2=done 3=is 4=loss 5=my 6=of 7=old • Represented as token IDs, docs look like • 5 1 3 4 6 1 • 0 7 1 2 • In sparse notation ignoring sequence info • { 1:2, 3:1, 4:1, 5:1, 6:1 } • { 0:1, 1:1, 2:1, 7:1 } Documents are similar if they frequently share words Extreme compression: can instead store gaps between adjacent token IDs Chakrabarti
Storing sparse arrays • Assign integer IDs to each axis/dimension • Use two “ganged” vectors • vector<int> dims storesdimension IDs • vector<float> vals storescoordinate in corresponding dim • Some important operations • Find the L2 norm of a vector • Add two vectors • Find the dot product between two vectors 1 3 4 5 6 2 1 1 1 1 Chakrabarti
Norm vector<int> dims; // suitably filled vector<float> vals; // suitably filled float normSquared = 0; for (int vx = 0, vn = vals.size();vx < vn; ++vx) { normSquared += vals[vx] * vals[vx]; } float norm = sqrt(normSquared); Chakrabarti
Sparse sum • aDims, aVals, bDims, bVals cDims, cVals • Best to keep all dims in increasing order • Conventionally written as • a = { 0:2.2, 3:1.4, 11:35 } b = { 1: 5.2, 3: 1.4 } • Then c = { 0:2.2, 1:5.2, 11:35 } • Two parts • Given a sparse vector that is not ordered by dim, how to clean it up • Given a and b sorted on dim, how to compute c • Second part first It’s just a merge! Chakrabarti
Sum merge ax 0 3 3 11 aDims 2.2 -1.4 35 aVals 0 1 11 cDims bx 2.2 -5.2 35 cVals 1 3 3 bDims -5.2 1.4 bVals Chakrabarti
Sum merge code vector<int> aDims, bDims, cDims; vector<float> aVals, bVals, cVals; // a and b filled, c empty int ax=0, an=aDims.size(),bx=0, bn=bDims.size(); while (ax < an && bx < bn) { // three cases: // aDims[ax] < bDims[bx] // aDims[ax] > bDims[bx] // aDims[ax] == bDims[bx] } // append leftovers as before Chakrabarti
Three cases • aDims[ax] < bDims[bx] • cDims.push_back(aDims[ax]); • cVals.push_back(aVals[ax]); ++ax; • aDims[ax] > bDims[bx] • cDims.push_back(bDims[bx]); • cVals.push_back(bVals[bx]); ++bx; • aDims[ax] == bDims[bx] • float newVal = aVals[ax] + bVals[bx]; • If |newVal| is zero/small, discard, else • cDims.push_back(aDims[ax]); • cVals.push_back(newVal); • In either case, ++ax; ++bx; Chakrabarti