Download

1 / 27
270 likes | 306 Views
Explore CAMP architecture for Trie-based IP lookup with Circular pipeline, optimizing memory usage and stage utilization. Includes implications, efficiency metrics, setup results, and nodes-to-stages mapping.

E N D
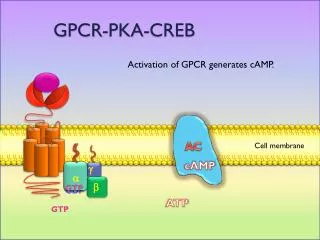
CAMP: Fast and Efficient IP Lookup Architecture Sailesh Kumar, Michela Becchi, Patrick Crowley, Jonathan Turner Washington University in St. Louis
Context • Trie based IP lookup • Circular pipeline architectures
Context IP address 111010… Prefix dataset • Trie based IP lookup • Circular pipeline architectures
0 1 0 1 0 1 1 0 1 0 0 1 Context IP address 111010… Trie Prefix dataset • Trie based IP lookup • Circular pipeline architectures P1 P6 P7 P5 P2 P8 P3 P4
0 1 P1 0 1 0 1 P6 P7 1 0 1 0 P5 P2 P8 0 1 P3 P4 Context IP address 111010… Trie Prefix dataset • Trie based IP lookup • Circular pipeline architectures Stage 1 Stage 2 Stage 3 Stage 4
0 1 P1 0 1 0 1 4 1 P6 P7 1 0 1 0 P5 P2 P8 3 2 0 1 P3 P4 Context IP address 111010… Trie Circular pipeline Prefix dataset • Trie based IP lookup • Circular pipeline architectures Stage 1 Stage 2 Stage 3 Stage 4
CAMP: Circular Adaptive and Monotonic Pipeline • Problems: • Optimize global memory requirement • Avoid bottleneck stages • Make the per stage utilization uniform • Idea: • Exploit a Circular pipeline: • Each stage can be a potential entry-exit point • Possible wrap-around • Split the trie into sub-trees and map each of them independently to the pipeline
CAMP (cont’d) • Implications: • PROS: • Flexibility: decoupling of maximum prefix length from pipeline depth • Upgradeability: memory bank updates involve only partial remapping • CONS: • A stage can be simultaneously an entry point and a transition stage for two distinct requests • Conflicts’ origination • Scheduling mechanism required • Possible efficiency degradation
x=2 P1 P1 P1 P3 P2 P3 P6 P7 P8 P2 P6 P7 P8 P4 P5 P4 P5 Trie splitting Direct index table Define initial stride x Use a direct index table with 2x entries for first x levels Expand short prefixes to length x Map the sub-trees Subtree 1 Subtree 3 Subtree 2 E.g.: initial stride x=2
Dealing with conflicts • Idea: use a request queue in front of each stage • Intuition: without request queues, • a request may wait till n cycles before entering the pipeline • a waiting request causes all subsequent requests to wait as well, even if not competing for the same stages • Issue: ordering • Limited torequests with different entry stages (addressed to different destinations) • An optional output reorder buffer can be used
Pipeline Efficiency • Metrics: • Pipeline utilization: fraction of time the pipeline is busy provided that there is a continuous backlog of requests • Lookups per Cycle (LPC): averagerequest dispatching rate • Linear pipeline: • LPC=1 • Pipeline utilization generally low • Not uniform stage utilization • CAMP pipeline: • High pipeline utilization • Uniform stage utilization • LPC close to 1 • Complete pipeline traversal for each request • # pipeline stages = # trie levels • LPC > 1 • Most requests don’t make complete circles around pipeline • # pipeline stages > # trie levels
Pipeline efficiency – all stages traversed • Setup: • 24 stages, all traversed by each packet • Packet bursts: sequences of packets to same entry point • Results: • Long bursts result in high utilization and LPC • For all burst size, enough queuing (32) guarantees 0.8 LPC
Pipeline efficiency – LPC > 1 • Setup: • 32 stages, rightmost 24 bits, tree-bit map of stride 3 • Average prefix length 24 • Results: • LPC between 3 and 5 • Long bursts result in lower utilization and LPC
Nodes-to-stages mapping • Objectives: • Uniform distribution of nodes to stages • Minimize the size of the biggest stage • Correct operation of the circular pipeline • Avoid multiple loops around pipeline • Simplified update operation • Avoid skipping levels
Nodes-to-stages mapping (cont’d) • Problem Formulation (constrained graph coloring): • Given: • A list of sub-trees • A list of colors represented by numbers • Color nodes so that: • Every color is nearly equally used • A monotonic ordering relationship without gaps among colors is respected when traversing sub-trees from root to leaves • Algorithm (min-max coloring heuristic) • Color sub-trees in decreasing order of size • At each steps: • Try all possible colors on root (the rest of the sub-tree is colored consequentially) • Pick the local optimum
1 2 2 3 3 3 3 4 4 4 4 4 Min-max coloring heuristic - example T3 T4 T2 T1
1 2 2 3 3 3 3 4 4 4 4 4 Min-max coloring heuristic - example T3 T4 T2 T1
1 3 2 2 4 3 3 3 3 1 1 4 4 4 4 4 2 2 2 2 Min-max coloring heuristic - example T3 T4 T2 T1
1 3 2 2 4 3 3 3 3 1 1 4 4 4 4 4 2 2 2 2 Min-max coloring heuristic - example T3 T4 T2 T1
1 2 3 2 2 3 3 4 3 3 3 3 4 1 1 4 4 4 4 4 1 1 2 2 2 2 Min-max coloring heuristic - example T3 T4 T2 T1
1 2 3 1 2 2 3 3 4 3 3 3 3 4 1 1 4 4 4 4 4 1 1 2 2 2 2 Min-max coloring heuristic - example T3 T4 T2 T1
Evaluation settings • Trends in BGP tables: • Increasing number of prefixes • Most of prefixes are <26 bit (~24 bit) long • Route updates can concentrate in short period of time; however, they rarely change the shape of the trie • 50 BGP tables containing from 50K to 135K prefixes
Memory requirements CAMP Level based mapping Height based mapping • Balanced distribution across stages • Reduced total memory requirements • Memory overhead: 2.4% w/ initial stride 8, 0.02% w/ initial stride 12, 0.01% w/ initial stride 16
Updates • Techniques for handling updates • Single updates inserted as “bubbles” in the pipeline • Rebalancing computed offline and involving only a subset of tries • Scenario • migration between different BGP tables • imbalance leads to 4% increase in occupancy of larger stage
Summary • Analysis of a circular pipeline architecture for trie based IP lookup • Goals: • Minimize memory requirement • Maximize pipeline utilization • Handle updates efficiently • Design: • Decoupling # of stages from maximum prefix length • LPC analysis • Nodes to stages mapping heuristic • Evaluation: • On real BGP tables • Good memory utilization and ability to keep 40Gbps line rate through small memory banks
Addressing the worst case • Observations: • We addressed practical datasets • Worst case tries may have long and skinny sections difficult to split • Idea: adaptive CAMP • Split trie into “parent” and “child” subtries • Map the parent sub-trie into pipeline • Use more pipeline stages to mitigate effect of multiple loops around pipeline