Download

1 / 51
510 likes | 648 Views
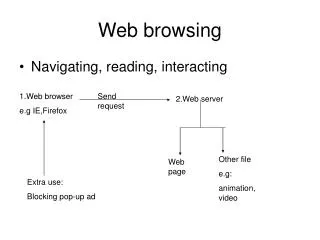
Correlation-Based Content Adaptation For Mobile Web Browsing. Iqbal Mohomed, Adin Scannell, Nilton Bila, Jin Zhang, Eyal de Lara Department of Computer Science University of Toronto. Middleware 2007. Need for Adaptation. Downloaded Data 600KB. Content must be customized!.

E N D
Correlation-Based Content Adaptation For Mobile Web Browsing Iqbal Mohomed, Adin Scannell, Nilton Bila, Jin Zhang, Eyal de Lara Department of Computer Science University of Toronto Middleware 2007
Need for Adaptation Downloaded Data 600KB Content must be customized!
Automatic Adaptation Mobile Device Adaptation Proxy Unmodified Content Server We Have The Mechanism But … The Hard Problem is Policies!
Achieving Fine Grain Adaptation • Usage and context both affect the customization that is needed • Machines have a hard time distinguishing between good and bad adaptations • People are better
Achieving Fine Grain Adaptation • Usage and context both affect the customization that is needed • Machines have a hard time distinguishing between good and bad adaptations • People are better Rely on a few users to adapt content for everyone!
Usage-awaRe Interactive Content Adaptation (URICA) • Allow users to interactively refine system’s adaptation decision • System learns from user modifications • Uses history for future adaptation predictions • Applicable to a wide range of adaptation types, such as image fidelity and page layout
40KB Server 1 Improve Fidelity Server 2 Mobile 2 Application 10KB 20KB Prediction How it Works Mobile 1 Application Adaptation Proxy
Predictions based on History Challenge: When users have varying preferences, how do we pick an appropriate adaptation?
Correlation-Based Content Adaptation • Typically, web pages/sites contain multiple objects • e.g. images • Use history to determine correlations in the adaptation requirements of different objects • When a user provides corrective feedback for one object, update the adaptation prediction for all related objects!
How To Find Correlations Automatically? • Boosted Decision Stumps • Mine data to create rules that capture relationships between the adaptation requirements of objects For objects X and Y: IF X > 3 THEN Y=7 • Gaussian Mixture Model • History data is used to parameterize a set of Gaussian distributions • Key parameter is # of distributions to consider • A user belongs to each distribution with some prior probability • As the user provides feedback to the system, these probabilities are updated
Page Layout Adaptation Prototype • Intended for use on mobile devices with limited screen real-estate • Allows users to increase or decrease the display size of images on web pages • Key metric is # of user interactions required to reach appropriate adaptation
Page Layout User Study • User study • 3 simulated display sizes: Phone, PDA and in-car browser • 4 web pages, 3 images per page • 30 participants • No prediction during data collection • Traces used to run experiments • Leave-one-out cross validation
Page Layout User Study • User study • 3 simulated display sizes: Phone, PDA and in-car browser • 4 web pages, 3 images per page • 30 participants • No prediction during data collection • Traces used to run experiments • Leave-one-out cross validation Without Correlation History-based predictions: 15 interactions, on average With Correlations Decision Stumps: 5.1 interactions, on average Gaussian Mixture Model: 5.9 interactions, on average
Fidelity Adaptation Prototype • Intended for bandwidth-limited environments
Fidelity Adaptation Prototype • Intended for bandwidth-limited environments
Fidelity Adaptation Prototype • Intended for bandwidth-limited environments
Fidelity Adaptation Prototype • Intended for bandwidth-limited environments
Fidelity Adaptation Prototype (contd.) • Two primary metrics of concern • Number of user interactions • Wasted bandwidth • Users can only increase the fidelity of images • Users have little incentive to reduce the fidelity of an image that they have already been served • Feedback is only one-sided, as opposed to the two-sided feedback received in page layout adaptation
Fidelity Adaptation:Movie Posters Study • User study • Users given 1 of 3 tasks • 9 web pages, 1 image of a movie poster per page • 37 participants per task • No prediction during data collection • Traces used to run experiments • Leave-one-out cross validation
Results From Movie Posters Study GMM (One-sided Feedback)
Results From Movie Posters Study GMM (One-sided Feedback) GMM (Perfect Feedback, Hypothetical)
Results From Movie Posters Study GMM (One-sided Feedback) GMM (Perfect Feedback, Hypothetical) Gaussian Mixture Model and Decision Stumps Did Not Perform Well When Only One-Sided Feedback Is Available
Our Approach • Run standard clustering algorithm (K-Means) on adaptation history • Custom algorithm (called all-in) to perform online classification • Intuition: narrow down the possible clusters a user can belong to quickly
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Clusters Found In History Using history, precalculate clusters as well as range of fidelities (min,max) for each image
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History When a user initially accesses the page, all clusters are valid
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History For each image, serve the lowest maximum fidelity value from the valid clusters
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History If the user requests a higher fidelity for an image, we can eliminate a cluster
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History If the user requests a higher fidelity for an image, we can eliminate a cluster
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History When only a single cluster remains, serve at the average
Operation of all-in Algorithm avg, min, max avg, min, max avg, min, max Image Desired By User Provided By System Clusters Found In History When only a single cluster remains, serve at the average
Results From Movie Posters Study GMM (One-sided Feedback) GMM (Perfect Feedback, Hypothetical) All-in
Fulfillment Time(Movie Posters Study) Legend: NA: No Adaptation DS: Decision Stumps GM: Gaussian Mixture AI: All-in OR: Hypothetical Oracle Fulfillment Time = download time + time spent by user to provide feedback
Fulfillment Time(Movie Posters Study) Legend: NA: No Adaptation DS: Decision Stumps GM: Gaussian Mixture AI: All-in OR: Hypothetical Oracle Fulfillment Time = download time + time spent by user to provide feedback
Fulfillment Time(Movie Posters Study) Legend: NA: No Adaptation DS: Decision Stumps GM: Gaussian Mixture AI: All-in OR: Hypothetical Oracle Fulfillment Time = download time + time spent by user to provide feedback
Fulfillment Time(Movie Posters Study) Legend: NA: No Adaptation DS: Decision Stumps GM: Gaussian Mixture AI: All-in OR: Hypothetical Oracle Fulfillment Time = download time + time spent by user to provide feedback
Fulfillment Time(Movie Posters Study) Legend: NA: No Adaptation DS: Decision Stumps GM: Gaussian Mixture AI: All-in OR: Hypothetical Oracle Fulfillment Time = download time + time spent by user to provide feedback
Summary • Correlation-based adaptation can be used to provide fine grain customization of content even when users have varying preferences • Standard machine learning techniques work well when there is two-sided feedback (e.g. page layout adaptation) • All-in algorithm performs well when only one-sided feedback is available (e.g. fidelity adaptation) • All-in behaves aggressively to quickly narrow down the number of clusters to which a user can belong