Download

1 / 30
300 likes | 533 Views
A MapReduce-Based Maximum-Flow Algorithm for Large Small-World Network Graphs. Felix Halim, Roland H.C. Yap, Yongzheng Wu. Outline. Background and Motivation Overview Maximum-Flow algorithm (The Ford-Fulkerson Method) MapReduce (MR) Framework Parallelizing the Ford-Fulkerson Method

E N D
A MapReduce-Based Maximum-Flow Algorithm for Large Small-World Network Graphs Felix Halim, Roland H.C. Yap, Yongzheng Wu
Outline • Background and Motivation • Overview • Maximum-Flow algorithm (The Ford-Fulkerson Method) • MapReduce (MR) Framework • Parallelizing the Ford-Fulkerson Method • Incremental update, bi-directional search, multiple excess paths • MapReduce Optimizations • Stateful extension, trading off space vs. number of rounds • Experimental Results • Conclusion
Background and Motivation • Large Small-world network Graphs naturally arise in • World Wide Web, Social Netwoks, Biology, etc… • Have been shown to have small diameter and robust • Maximum-flow algorithm on Large Graphs • Isolate a group of spam sites on WWW • Community Identification • Defense against Sybil attack • Challenge:Computation, storage and memory requirements exceed a single machine capacity • Our approach: Cloud/Cluster Computing • Run Max-Flow on top of the MapReduce Framework
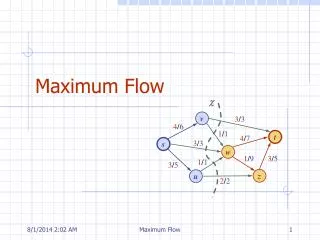
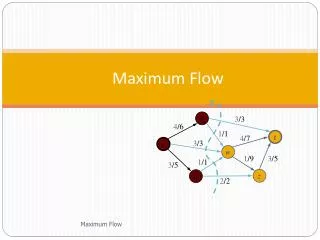
The Maximum-Flow Overview • Given a flow network G = (V,E), s, t • Residual network Gf = (V, Ef) • Augmenting path • A simple path from s to t in the residual network • To compute the maximum-flow • The Ford-Fulkerson Method O( |f*| E ) While an Augmenting path p is found in Gf Augment the flow along the path p
Maximum-Flow Example Residual Network 9 Legends: source node sink node intermediate node residual = C – F augmenting path p 6 10 t s 2 10 s 7 9 8 t Augment p 3 0 4 r 6 6 6 t s 2 10 7 9 8
Maximum-Flow Example Residual Network 3 Legends: source node sink node intermediate node residual = C – F augmenting path p 0 4 6 6 6 t s 2 10 s 7 9 8 t Augment p 3 0 4 r 6 6 6 t s 2 10 2 0 1 7 7 7
Maximum-Flow Example Residual Network 3 Legends: source node sink node intermediate node residual = C – F augmenting path p 0 4 6 6 6 t s 2 10 s 2 0 1 7 7 t 7 Augment p 2 0 3 r 7 7 6 1 t s 10 1 1 0 0 8 7 8
Maximum-Flow Example Flow / Capacity 7/9 Legends: source node sink node intermediate node residual = C – F augmenting path p 6/6 7/10 t s 1/2 10 s 7/7 8/9 8/8 t Max-Flow = 14 2 0 3 r 7 7 6 1 t s 10 1 1 0 0 8 7 8
MapReduce Framework Overview • Introduced by Google in 2004 • Open source implementation: Hadoop • Operates on very large dataset • Consists of key/value pairs • Across thousands of commodity machines • Order terabytes of data • Abstracts away distributed computing problems • Data partitioning and distribution, load balancing • Scheduling, fault tolerance, communication, etc…
MapReduce Model • User Defined Map and Reduce function (stateless) • Input: a list of tuples of key/value pairs (k1/v1) • The user’s map function is applied to each key/value pair • Produces a list of intermediate key/value pairs • Output: a list of tuples of key/value pairs (k2/v2) • The intermediate values are grouped by its key • The user’s reduce function is applied to each group • Each tuple is independent • Can be processed in isolation and massively parallel manner • Total input can be far larger than the total workers’ memory
Max-Flow on MR - Observations • Input: Small-world graph with small diameter D • A vertex in the graph is modeled as an input tuple in MR • Naïve translation of the Ford-Fulkerson method to MapReduce requires O(|f*| D)MR rounds • Breadth-first search on MR requires O(D) MR rounds • BFSMR using 20 machines takes 9 rounds and 6 hours for • SWN with ~400M vertices and ~31B edges • It would take years to compute a maxflow (|f*| > 1000) • Question: How to minimize the number of rounds?
FF1: A Parallel Ford-Fulkerson • Goal: Minimize the number of rounds thru parallelism • Do more work/round, avoid spilling tasks to the next round • Use speculative execution to increase parallelism • Incremental updates • Bi-directional search • Doubles the parallelism (number of active vertices) • Effectively halves the expected number of rounds • Maintain parallelism (maintain large number of active vertices) • Multiple Excess Paths (k) -> most effective • Each vertex stores k excess paths (avoid becoming inactive) • Result: • Lower the number of rounds required from O(|f*| D) to ~D • Large number of augmenting path/round (MRbottleneck)
MR Optimizations • Goal: minimize MR bottlenecks and overheads • FF2 : External worker(s) for stateful MR extension • Reducer for vertex t is the bottleneck for FF1 (bottleneck) • An external process is used to handle augmenting paths acceptance • FF3 : Schimmy Method [Lin10] • Avoid shuffling the master graph • FF4 : Eliminate object instantiations • FF5 : Minimize MR shuffle (communication) costs • Monitor the extended excess paths for saturation and resend as needed • Recompute/reprocess the graph instead of shuffling the delta (not in paper)
Experimental Results • Facebook Sub-Graphs • Cluster setup • Hadoop v0.21-RC-0 installed on 21 nodes (8-cores Hyper-threaded (2 Intel E5520 @2.27GHz), 3 hard disks (@500GB SATA) and Centos 5.4 (64-bit))
Handling Large Max-Flow Values • FF5MR is able to process FB6 with a very small number of MR rounds (close to graph diameter).
MapReduce Optimizations • FF1 (parallel FF) to FF5 (MR optimized) vs. BFSMR
Shuffle Bytes Reduction • The bottleneck in MR is the shuffle bytes, FF5 optimizes the shuffled bytes
Conclusion • We showed how to parallelize a sequential max-flow algorithm, minimizing the number of MR rounds • Incremental Updates, Bi-directional Search, and Multiple Excess Paths • We showed MR optimizations for max-flow • Stateful extension, minimize communication costs • Computing max-flow on Large Small-World Graph • Is practical using FF5MR
Q & A • Thank you
Backup Slides • Related Works • Multiple Excess Paths – Results • Edge processed / second – Results • MapReduce example (word count) • MapReduce execution flow • FF1 Map Function • FF1 Reduce Function • MR
Related Work • The Push-Relabel algorithm • Distributed (no global view of the graph required) • Have been developed for SMP architectures • Needs sophisticated heuristics to push the flows • Not Suitable for MapReduce model • Need locks, pull information from its neighbors • Low number of active vertices • Pushing flow to a wrong sub-graph can lead to huge number of rounds
Multiple Excess Paths - Effectiveness • The more the k, the less the number of MR rounds required (keep the number of active vertices high)
# Edges processed / sec • The larger the graph, the more effective
MapReduce Example – Word Count map(key,value) // document name, contents foreach word w in value EmitIntermediate(w, 1); reduce(key,values) // a word, list of counts freq = 0; foreach v in values freq = freq + v Emit(key, freq)
MapReduce Simple Applications • Word Count • Distributed Grep • Count URL access frequency • Reverse Web-Link Graph • Term-Vector per host • Inverted Index • Distributed Sort All these tasks can be completed in one MR job
General MR Optimizations • External worker as stateful Extension for MR • (Dedicated) External workers outside mappers / reducers • Immediately process requests • Don’t need to wait until mappers / reducers complete • Flexible synchronization point • Minimize shuffling intermediate tuples • Can avoid shuffling by re-(process/compute) in the reduce • Use flags in the data structure to prevent re-shuffling • Eliminate object instantiation • Use binary serializations