Download

1 / 29
290 likes | 305 Views
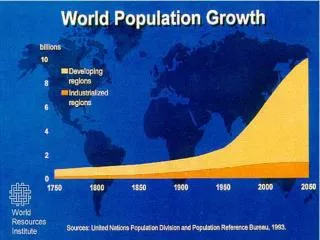
Modeling Study Outcomes. Consider the k studies as coming from a population of effects we want to understand. One way to model effects in meta-analysis is using random effects – think of ANOVA or HLM models.

E N D
Modeling Study Outcomes Consider the k studies as coming from a population of effects we want to understand. One way to model effects in meta-analysis is using random effects – think of ANOVA or HLM models. Or if we are only interested in the set of studies we have in hand – all the “levels” of interest are right here – this is a fixed-effects model. We also assume all studies come from a single population effect with this model.
Modeling Study Outcomes Let us call the effect sizes Ti , for k independent studies i = 1 to k. We will have T1, T2, . . . , Tk We begin with a model for each effect, just as in primary research.
Modeling Study Outcomes In meta-analysis, we model the study outcome Ti . The simplest model is the random-effects model. For studies i = 1 to k, Ti = θi + ei Observed Population Residual deviation study parameter due to sampling outcome for study i error We assume that parameters (the θi) vary, as do the sample values Ti.
Graphic representation of random-effects model • This is from Viechtbauer (2007) in Zeitschrift fur Psychologie. Smaller n’s lead to more sampling variation (and wider CIs). Reverse is true for larger studies like this one.
Graphic representation of random-effects modelOur problem is that we must work backwards... • We begin with the sample data – our set of effects, but we do not know what parameters generated these effects. • However, we do know each effect’s sampling variation based on vi and the CIs.
Graphic representation of random-effects modelWe will plot the confidence intervals using the variance formula for our effect size (let’s say these are d values, estimating ds). ----o---- -----o----- --------o-------- ---o--- |____|____|____|____|____|____| -.2 0 .2 .4 Each o represents a d value – this one (say, d4) appears to be about 0.22. Its CI goes from about 0.17 to 0.27. d
Graphic representation of random-effects modelDepending on how wide the CIs are we may “see” more or less variation in the true d values: --o-- --o-- --o-- --o-- |____|____|____|____|____|____| -.2 0 .2 .4 d These CIs make the effects look farther apart (more variable) because these studies are very precise.
Graphic representation of random-effects modelThe same effects look different with different CIs drawn around them: ---------o--------- --------o-------- -----------o----------- ----------o---------- |____|____|____|____|____|____| -.2 0 .2 .4 d These wide CIs make it seem like the true effects probably do not vary greatly – or if they do, the studies are too imprecise to detect it.
Fixed-Effects (FE) Model If all population parameters are equal (θi = θ), we have the fixed-effects model: Ti = θ + ei for i = 1 to k. Observed Single Residual deviation study population due to sampling outcome parameter error All studies are modeled as having the same effect θ.
Graphic representation of fixed-effects model • The “distribution” in the first panel is now one value. In this case the distributions below would all shift to be in line with the single d value, and the effects would be closer together (see x’s not o’s). x x x x x x xx
Variances under fixed-effects model In these models the ei represents sampling error, so that the variance of Ti is V(Ti) = V(θi) + V(ei) . If θ is a constant, then V(Ti) = V(ei) = Vi (Vi will be our symbol for the FE variance.) Under the fixed-effects model, all variation is conceived as being due to sampling error. This is why all distributions lined up in the last slide.
Variances under random-effects (RE) model If the variance of Ti is V(Ti) = V(θi) + V(ei) , and the θido vary, then we say V(θi) = s2θ and then V(Ti) = s2θ + Vi This is the RE variance. Under the random-effects model, variation comes from sampling error AND true differences in effects.
Fixed-Effects Model More specific fixed-effects models are for correlations ri = ρ + ei and for effect sizes di = δ + ei . V(ei) or Vi is estimated as above, e.g., for ri Vi = Var(ri) = (1 - ri2 )2/(ni-1), and for di Vi = (niE + niC) + di2 . (niE*niC) 2*(niE + niC)
In the RE case each population has a different effect, and we estimate the amount of uncertainty (variation) due to those differences or we try to predict it. So... Under the simple fixed-effects model, we estimate a “common” effect; Under the simple random-effects model, we estimate an “average” effect.
Estimating Common or Average Effects One goal in most meta-analyses is to examine overall, or typical effects, and to test them, as in H0: = 0 Here the could represent any effect size such as d or r. We can write the hypothesis using more specific symbols, e.g., H0: d= 0
Estimating Common or Average Effects Under the random-effects model, we test H0: . = 0 e.g., H0: . = 0 The average of The average of the i values the population is zero correlations is zero We will earn how to do this test shortly.
Testing Consistency or Homogeneity Another hypothesis we typically test in meta-analysis is that all studies arise from one population H0: 1 = . . . = k = or H0:2 = 0 This is also the test of whether the fixed-effects model is appropriate.
Testing Consistency or Homogeneity The test statistic is where wi = 1/Vi and wi is an inverse variance weight from the FE model.
Testing Consistency or Homogeneity Parts of the Q statistic may look familiar Q is a weighted variance, and under H0 , Q ~ chi-square with k-1 df Squared deviation from mean
Testing Consistency or Homogeneity A large Q means our results do not all agree, or we may say the results are “heterogeneous” or “inconsistent” . Some researchers prefer not to test Q but to simply assume that the effects vary, and to estimate their true variance.
Testing Consistency or Homogeneity We can see that the Q statistic can get large for two reasons 1) Ti is far from the mean, T. 2) Vi is small so weight wi = 1/Vi is large (which happens when the sample is big)
This is the teacher expectancy data. This plot shows confidence intervals for the effect sizes, which are all d values. We’ve computed T + 1.96Vi here, and we can see one interval that appears to be larger than the others. The effect size is above 1 SD!! Also there is a fair amount of spread – there’s no place where a line crosses all of the intervals (a quick test for homogeneity). LLIM ULIM T min max ‑1 2 *‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑* ‑0.22 0.28 0.03 | [‑‑‑*‑‑‑] | ‑0.17 0.41 0.12 | [‑‑|‑*‑‑‑] | ‑0.47 0.19 ‑0.14 | [‑‑‑‑*‑|‑‑] | 0.45 1.91 1.18 | | [‑‑‑‑‑‑‑‑‑‑*‑‑‑‑‑‑‑‑‑‑] | ‑0.46 0.98 0.26 | [‑‑‑‑‑‑|‑‑‑*‑‑‑‑‑‑‑‑‑‑] | ‑0.26 0.14 ‑0.06 | [‑‑*|‑] | ‑0.22 0.18 ‑0.02 | [‑‑‑*‑‑] | ‑0.75 0.11 ‑0.32 | [‑‑‑‑‑‑*‑‑‑‑|‑] | ‑0.05 0.59 0.27 | [|‑‑‑*‑‑‑‑] | 0.31 1.29 0.80 | | [‑‑‑‑‑‑*‑‑‑‑‑‑‑] | ‑0.05 1.13 0.54 | [|‑‑‑‑‑‑‑*‑‑‑‑‑‑‑‑] | ‑0.26 0.62 0.18 | [‑‑‑|‑‑*‑‑‑‑‑] | ‑0.59 0.55 ‑0.02 | [‑‑‑‑‑‑‑‑*‑‑‑‑‑‑‑] | ‑0.34 0.80 0.23 | [‑‑‑‑|‑‑*‑‑‑‑‑‑‑‑] | ‑0.49 0.13 ‑0.18 | [‑‑‑‑*‑‑|‑] | ‑0.39 0.27 ‑0.06 | [‑‑‑‑*|‑‑‑] | 0.03 0.57 0.30 | [‑‑‑*‑‑‑‑] | ‑0.11 0.25 0.07 | [‑|*‑‑] | ‑0.41 0.27 ‑0.07 | [‑‑‑‑*|‑‑‑] | *‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑‑*
This output shows SPSS GLM output for Q and the FE mean. Do NOT use the F test or SEs from this output!!!
Q is a chi-square with 18 df (k-1 = 18). The Q is significant at the .01 level (with p < .01). This means that the FE mean of 0.06 shown above should NOT be used to represent the overall result for these data. We need a random effects mean, which we will discuss later. This result is not surprising given the spread in the CI plot. We will return to the teacher expectancy data later.
Other Indices: The Birge ratioThe ratio of a chi-square to its degrees of freedom can provide a scale-free index of variability. Birge used the value Q/df which we will call B. Since the df is the expected value of each chi-square, when the chi-square shows only random variation (and thus is not much larger than its df), B is close to 1.
The Birge ratioThe ratio B therefore is larger than 1 when the results of a set of studies are heterogeneous (i.e., more varied than we’d expect from just sampling error). So we can compute BTotal = QTotal /(k-1)and we can use BTotal to compare different-sized data sets to see whether one is more heterogeneous.
Other Indices: I squaredThe Q test has been used in one other way to get an index of heterogeneity. It is something like a percentage and is called I2. We compute I2 = 100*[QTotal - (k-1)]/Qtotal = 100*[1 - (k-1)/Q]If Q is much larger than its degrees of freedom, then the numerator [QTotal - (k-1)] will be large. If Q < k-1 there is little variation, and we set the value of I2 to zero.
Q, the Birge ratio, and I2 for the teacher expectancy dataQTotal (k-1) BTotal = QTotal /(k-1) I2______________________________________ 35.83 18 1.99 49.76This reflects a significant, but only moderate amount of variation.
This output shows SPSS output for the Q and RE mean for these data. Some things we have not yet discussed. Fixed-effects Homogeneity Test (Q) 35.8254 P-value for Homogeneity test (P) .0074 Birge's ratio, ratio of Q/(k-1) 1.9903 I-squared, ratio 100 [Q-(k-1)]/Q .4976 Variance Component based on Homogeneity Test (QVAR) .0259 Variance Component based on S2 and v-bar (SVAR) .0804 RE Lower Conf Limit for T_Dot (L_T_DOT) -.0410 Weighted random-effects average of effect size based on QVAR (T_DOT) .1143 RE Upper Conf Limit for T_Dot (U_T_DOT) .2696