Download

1 / 13
130 likes | 236 Views
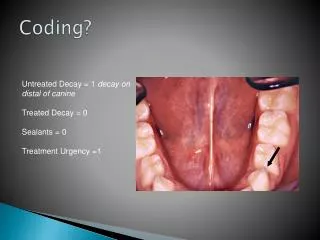
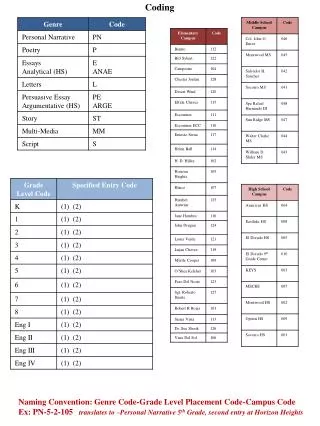
DHMM coding 2. Parameter A. 上次的參數 A 是將所有對應的 state 之 frame 數目加至對應的欄位並做平均取對數 這次參照定義,將 A 設定為 state 轉移的個數取平均再取對數. 1. 1. 2. 2. 3. 3. 3. 3. before. 1. 1. 2. 2. 3. 3. 3. 3. now. Ideal Cluster Number. 假如要對所有的對象使用相同的分群數目,那麼就要找出這整個群體的理想分群

E N D
Parameter A • 上次的參數A是將所有對應的state之frame數目加至對應的欄位並做平均取對數 • 這次參照定義,將A設定為state轉移的個數取平均再取對數 1 1 2 2 3 3 3 3 before 1 1 2 2 3 3 3 3 now
Ideal Cluster Number • 假如要對所有的對象使用相同的分群數目,那麼就要找出這整個群體的理想分群 • 我們的對象是數字0~9,我們要讓它們有相同大小的B;換句話說,我們讓所有數字的B(i,j)大小都是(StateNumbers, ClusterNumbers)),我們就要找出它們的理想分群數 • 做法:將所有的數字做mfcc轉成特徵陣列,再將所有特徵陣列合併,再利用k-means作分群並尋找理想分群數 • 最後找到的理想分群數為35
Path 81543 81535
DHMM的基本原理,是利用許多聲音檔進行viterbi decoding和re-estimate A,B • 上星期已經完成了上述動作,但是現階段面臨的最大問題是:如何使對象(ex. 9)進入屬於這個對象的model,出來的對數機率和會大於其他對象(ex. 0~8) • 現在雖然有辦法找出各個model最後收歛的A,B,但是卻無法使用這些model做辨識;原因是這些model無法讓其對應對象一定有最大對數機率和
目前檢驗此model是否有效的流程: • 找出re-estimate後的A,B,然後將其他所有數字都經過此model產生對數機率和,並將這些數組合成為matrix • 找出此matrix的mean vector,其意義為相同對象的對數機率和平均 • 根據mean vector內最大值的位置是否對應此model的值,來決定這個A,B是否有作用
Example: Numbers • 假如我們利用手上的10個0的聲音檔做A,B的參數訓練,最後可以得到收斂的A,B;利用A,B對數字陣列內的所有數字找出對數機率和,可以得到對數機率和陣列;若mean vector的最大值位置在(1,1)即代表0的辨識率最高,這個A,B有作用 10*10數字陣列 10*10對數機率和陣列 平均向量
之前提到過,目前找的model幾乎無法讓對象有最大機率和;目前只有對數字9找到最佳的A,B,可以讓大部分的9產生最大對數機率和之前提到過,目前找的model幾乎無法讓對象有最大機率和;目前只有對數字9找到最佳的A,B,可以讓大部分的9產生最大對數機率和 • 對所有的對象數字經過1000次的失敗重找A,B後仍然無法找到讓人滿意的A,B 失敗就重找A,B 利用viterbi decoding直到收斂,找出A,B 對所有數字進行對數機率和運算並找出平均向量 成功
EX: Model 0 • 將數字陣列丟入model 0所產生的對數機率和陣列: • 發現只有第3、第10列結果正確 • mean vector的最大值也沒有落在0的位置 mean vector
EX: Model 9 • 這是另一個範例,找出9的最佳參數A,B,將數字陣列丟入model所產生的對數機率和陣列和mean vector: • 這個看起來比較有挽救的希望~ mean vector
Debug • viterbi-decoding有問題所以找到的A,B無法用來辨識 • 但是每次的E都呈現遞減收斂,符合re-estimate的定義 • 聲音樣本(train/test)不符合dhmm的需求 • 但是之前在DTW的時候有作用 • 雖然在DTW有用不等價於在dhmm有用,但是目前看不出來聲音檔的問題是否對dhmm有影響 • 使用共同分群數是否妥當 • 或許可以對不同model做理想分群,但是這會造成每個model的參數B不同
cont. • 之前找的最佳分群數35是否就代表用來辨識的最佳分群數 • 如同上一項所提到的不同分群所造成的影響 • 訓練樣本不夠多 • 目前只對自己的聲音作辨識,樣本數目會有影響?
Other Example • 網路上有一些範例,我找了一個: • 這個code的目的是對數字語音檔做endpoint detection, mfcc, VQ,最後是hmm的train和test • 它的code所截出的mfcc使用12-dim,mfcc長度約在20左右;我的mfcc長度可以破百!這點不知是否有影響 • 它的參數:stateNum=4 symbolNum=64 • 它選用資料訓練後,會對訓練的資料做inside test;對其他的資料做outside test • 根據程式說明,inside test和outside test的準確率分別是87%和73