Download

1 / 34
400 likes | 701 Views
A web browser. A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. An information resource is identified by a Uniform Resource Identifier (URI) and may be a web page, image, video, or other piece of content. [.

E N D
A web browser • A web browser is a software application for retrieving, presenting, and traversing information resources on the World Wide Web. • An information resource is identified by a Uniform Resource Identifier (URI) and may be a web page, image, video, or other piece of content.[
Lynx – 1992 • Mosaic – 1994
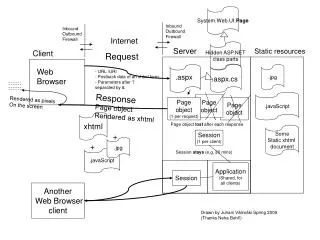
Function of browser • The primary purpose of a web browser is to bring information resources to the user. This process begins when the user inputs a Uniform Resource Locator (URL), for example http://en.wikipedia.org/, into the browser. The prefix of the URL determines how the URL will be interpreted. http , ftp • In the case of http, https, file, and others, once the resource has been retrieved the web browser will display it. • HTML is passed to the browser's layout engine to be transformed from markup to an interactive document. • Aside from HTML, web browsers can generally display any kind of content that can be part of a web page. Most browsers can display images, audio, video, and XML files, and often have plug-ins to support Flash applications and Java applets. Upon encountering a file of an unsupported type or a file that is set up to be downloaded rather than displayed, the browser prompts the user to save the file to disk.
The User Interface subsystem is the layer between the user and the Browser Engine. It provides features such as toolbars, visual page-load progress, smart download handling, preferences, and printing. • It may be integrated with the desktop environment to provide browser session management or communication with other desktop applications.
The Browser Engine subsystem is an embeddable component that provides a high-level interface to the Rendering Engine. • It loads a given URI and supports primitive browsing actions such as forward, back, and reload. • It provides hooks for viewing various aspects of the browsing session such as current page load progress and JavaScript alerts. • It also allows the querying and manipulation of Rendering Engine settings.
The Rendering Engine subsystem produces a visual representation for a given URI. It is capable of displaying HTML and Extensible Markup Language (XML) (Bray et al., 2004) documents, optionally styled with CSS, as well as embedded content such as images. • It calculates the exact page layout and may use “reflow” algorithms to incrementally adjust the position of elements on the page. • This subsystem also includes the HTML parser.
The Networking subsystem implements file transfer protocols such as HTTP and FTP. It translates between different character sets, and resolves MIME media types for files. • It may implement a cache of recently retrieved resources
The JavaScript Interpreter evaluates JavaScript (also known as ECMAScript) code, which may be embedded in web pages. • Certain Java- Script functionality, such as the opening of pop-up windows, may be disabled by the Browser Engine or Rendering Engine for security purposes.
The XML Parser subsystem parses XML documents into a Document Object Model (DOM) tree. This is one of the most reusable subsystems in the architecture. • In fact, almost all browser implementations leverage an existing XML Parser rather than creating their own from scratch.
The Display Backend subsystem provides drawing and windowing primitives, a set of user interface widgets, and a set of fonts. • It may be tied closely with the operating system.
The Data Persistence subsystem stores various data associated with the browsing session on disk. This may be high-level data such as bookmarks or toolbar settings, or it may be low-level data such as cookies, security certificates, or cache.
Web search engine • A web search engineis designed to search for information on the World Wide Web and FTP servers. The search results are generally presented in a list of results and are often called hits. The information may consist of web pages, images, information and other types of files. Some search engines also mine data available in databases or open directories. • The very first tool used for searching on the Internet was Archie in 1990 • Gopher
How Search engine works? • A search engine operates in the following order: • Web crawling • Indexing • Searching.
How Search engine works? • Web search engines work by storing information about many web pages, which they retrieve from the html itself. These pages are retrieved by a Web crawler (sometimes also known as a spider) — an automated Web browser which follows every link on the site. Exclusions can be made by the use of robots.txt. • The contents of each page are then analyzed to determine how it should be indexed (for example, words are extracted from the titles, headings, or special fields called meta tags). Data about web pages are stored in an index database for use in later queries. • A query can be a single word. The purpose of an index is to allow information to be found as quickly as possible. • Some search engines, such as Google, store all or part of the source page (referred to as a cache) as well as information about the web pages, whereas others, such as AltaVista, store every word of every page they find.
How search engine works? • When a user enters a query into a search engine (typically by using key words), the engine examines its index and provides a listing of best-matching web pages according to its criteria, usually with a short summary containing the document's title and sometimes parts of the text. • The index is built from the information stored with the data and the method by which the information is indexed.
Robot.txt • This text file should contain the instructions in a specific format . Robots that choose to follow the instructions try to fetch this file and read the instructions before fetching any other file from the web site. • If this file doesn't exist web robots assume that the web owner wishes to provide no specific instructions.
Robot.txt • For websites with multiple subdomains, each subdomain must have its own robots.txt file. • If example.com had a robots.txt file but a.example.com did not, the rules that would apply for example.com would not apply to a.example.com.
This example allows all robots to visit all files because the wildcard * specifies all robots: User-agent: * Disallow: This example keeps all robots out: User-agent: * Disallow: / The next is an example that tells all crawlers not to enter four directories of a website: User-agent: * Disallow: /cgi-bin/ Disallow: /images/ Disallow: /tmp/ Disallow: /private/ Example that tells a specific crawler not to enter one specific directory: User-agent: BadBot # replace the 'BadBot' with the actual user-agent of the bot Disallow: /private/
Web Crawler • A Web crawler is a computer program that browses the World Wide Web in a methodical, automated manner or in an orderly fashion. • ants, • automatic indexers, • Bots, • Web spiders, • Web robots, • Web scutters
Working of web crawler • A Web crawler is one type of bot, or software agent. In general, it starts with a list of URLs to visit, called the seeds. • As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. • URLs from the frontier are recursively visited according to a set of policies
The behaviour of a Web crawler is the outcome of a combination of policies: • a selection policythat states which pages to download, • a re-visit policy that states when to check for changes to the pages, • a politeness policythat states how to avoid overloading Web sites, and • a parallelization policythat states how to coordinate distributed Web crawlers.
Web Indexing • The purpose of storing an index is to optimize speed and performance in finding relevant documents for a search query. • Without an index, the search engine would scan every document in the corpus, which would require considerable time and computing power.
Index Design Factors • Merge factors How data enters the index, or how words or subject features are added to the index during text corpus traversal, and whether multiple indexers can work asynchronously. The indexer must first check whether it is updating old content or adding new content. Traversal typically correlates to the data collection policy. Search engine index merging is similar in concept to the SQL Merge command and other merge algorithms. • Storage techniques How to store the index data, that is, whether information should be data compressed or filtered. • Index size How much computer storage is required to support the index.
Lookup speed How quickly a word can be found in the inverted index. The speed of finding an entry in a data structure, compared with how quickly it can be updated or removed, is a central focus of computer science. • Maintenance How the index is maintained over time. • Fault tolerance How important it is for the service to be reliable. Issues include dealing with index corruption, determining whether bad data can be treated in isolation, dealing with bad hardware, partitioning, and schemes such as hash-based or composite partitioning as well as replication.
Inverted Indices • Many search engines incorporate an inverted index when evaluating a search query to quickly locate documents containing the words in a query and then rank these documents by relevance. • Because the inverted index stores a list of the documents containing each word, the search engine can use direct access to find the documents associated with each word in the query in order to retrieve the matching documents quickly. The following is a simplified illustration of an inverted index: Word Documents The Document 1, Document 3, Document 4, Document 5 Cow Document 2, Document 3, Document 4 Says Document 5 Moo Document 7
The Forward Index • The forward index stores a list of words for each document. The following is a simplified form of the forward index: Document Words Document 1 the,cow,says,moo Document 2 the,cat,and,the,hat Document 3 he,dish,ran,away,with,the,spoon
Limitations of search engine • Can not save your searches • Can not search according to date • cannot export selected search results to your office applications • cannot show all results on a single page • ...don't allow you to enter search strings for multiple searches all at once and then provide you with all available search results for each search. • works on metadata
Search engine optimization • Search engine optimization (SEO) is the process of improving the visibility of a website or a web page in search engines via the "natural" or un-paid ("organic" or "algorithmic") search results.