Download

1 / 40
410 likes | 565 Views
Practical techniques for agents playing multi-player games. Quiz: Complexity of Minimax. Chess: has an average branching factor of ~30, and each game takes on average ~40.

E N D
Quiz: Complexity of Minimax Chess: has an average branching factor of ~30, and each game takes on average ~40. If it takes ~1 milli-second to compute the value of each board position in the game tree, how long to figure out the value of the game using Minimax? A few milliseconds A few seconds A few minutes A few hours A few days A few years? A few decades? A few millenia(thousands of years)? More time than the age of the universe?
Quiz: Complexity of Minimax Chess: has an average branching factor of ~30, and each game takes on average ~40. If it takes ~1 milli-second to compute the value of each board position in the game tree, how long to figure out the value of the game using Minimax? A few milliseconds A few seconds A few minutes A few hours A few days A few years? A few decades? A few millenia(thousands of years)? More time than the age of the universe
Strategies for coping with complexity • Reduce b • Reduce m • Memoize
Reduce b: Alpha-beta pruning ∆ <=1 4 ∇ ∇ ∇ ∆ ∆ ∆ 20 4 12 ∆ 9 ∆ 7 1 6 9 5 7 -5 -7 2 5 -9 15 During Minimax search (assume depth-first, left-to-right order): First get a 6 for the left-most child of the root. For the middle child of the root, the first child is a 1. The agent can stop searching the middle child after this 1.
Reduce b: Alpha-beta pruning ∆ <=1 4 ∇ ∇ ∇ ∆ ∆ ∆ 20 4 12 ∆ 9 ∆ 7 1 6 9 5 7 4 10 2 3 -9 15 The agent can stop searching the middle child after this 1. The reason is that this is a Min node, and by finding a 1, we’ve already guaranteed that Min would select AT MOST a 1. So, we’ve guaranteed that MAX would not select this child, and we can move on.
Quiz: Reduce b: Alpha-beta pruning ∆ <=1 4 ∇ ∇ ∇ ∆ ∆ ∆ 20 4 12 ∆ 9 ∆ 7 1 6 9 5 7 4 10 2 3 -9 15 What other nodes will be visited, if the agent continues with this technique? What will be the values of those nodes?
Answer: Reduce b: Alpha-beta pruning ∆ <=1 4 ∇ ∇ ∇ <=3 ∆ ∆ ∆ 20 4 12 ∆ 9 ∆ 7 1 3 6 9 5 7 4 10 2 3 -9 15 What other nodes will be visited, if the agent continues with this technique? What will be the values of those nodes?
Quiz: Reduce b: Alpha-beta pruning ∆ ∇ ∇ ∇ ∆ ∆ ∆ 20 4 12 ∆ ∆ 1 6 9 5 7 4 10 5 15 -9 2 Suppose the algorithm visits nodes depth-first, but Right-to-Left. What nodes will be visited, and what are the values of those nodes?
Answer: Reduce b: Alpha-beta pruning ∆ 4 ∇ ∇ ∇ 4 1 2 >=9 >=15 10 2 7 ∆ ∆ ∆ 20 4 12 ∆ ∆ 1 6 9 5 7 4 10 5 15 -9 2 Going right-to-left in this tree, there are fewer opportunities for pruning: effects of pruning depend on the values in the tree. On average, this technique tends to cut branching factors down to their square root (from b to √b).
Reduce m: evaluation functions ∆ ∇ ∇ ∇ ∆ ∆ ∆ 20 4 12 ∆ ∆ 1 6 9 5 7 4 10 2 5 -9 15 Suppose searching to a depth of m=3 is just too expensive. What we’ll do instead is introduce a horizon (h), or cutoff. For this example, we’ll let h=2. No nodes will be visited beyond the horizon.
Reduce m: evaluation functions ∆ ∇ ∇ ∇ ? ? ? ? ? ∆ ∆ ∆ 20 4 12 ∆ ∆ 1 6 9 5 7 4 10 2 5 -9 15 Problem: how do we determine the value of non-terminal nodes at the horizon? The general answer is to introduce evaluation functions, which estimate (or guess) the value of a node.
Reduce m: evaluation functions ∆ ∇ ∇ ∇ ? ? ? ? ? ∆ ∆ ∆ 20 4 12 ∆ ∆ 1 6 9 5 7 4 10 2 5 -9 15 Let E(n) = w1 f1(n) + w2 f2(n) + … + wkfk(n) Each fi(n) is a “feature function” of the node, that returns some real number describing the node in some way. Each wi is a real number weight or parameter. One common way to create E(n) is to get game experts to come up with appropriate fi and wi.
Hex Evaluation Function Example fi = shortest path for red – shortest path for blue = 2 - 1 = 1 As an example, one possible fi function for Hex could be the shortest path to a solution for Red, minus the shortest path to a solution for Blue.
Hex Evaluation Function Example fi = shortest path for red – shortest path for blue = 2 - 1 = 1 If Red is Max, we can assign wi = -1. This encodes the intuition that if Red has a longer shortest path than Blue, then this is a bad position for Red.
Hex Evaluation Function Example Can you think of some other potential fi for Hex? Notice, the important thing is that fi should be correlated with Value(n).
Learning an evaluation function Experts are often good at coming up with fi functions. But it’s often hard for a game expert (or anyone) to come up with the best wi weights for E(n). An alternative approach is to create an algorithm to learn the wi weights from data.
What’s the data? To do machine learning, you need data that contains inputs and labels. For an evaluation function, that means board positions and values. But we’ve already said that it’s hard to figure out the right value for many board positions – that’s the whole point of the evaluation function in the first place. Instead of asking people to label boards with values, a common approach is to have a simulation of the agent playing against itself. The outcome of the game is used as the value of the board positions along the way.
Quiz: What’s the learning algorithm? Once you’ve collected enough examples of board positions and values, there are lots of algorithms to do the learning. For the kind of evaluation function I introduced, name some appropriate learning techniques that we’ve discussed.
Answer: What’s the learning algorithm? Once you’ve collected enough examples of board positions and values, there are lots of algorithms to do the learning. For the kind of evaluation function I introduced, name some appropriate learning techniques that we’ve discussed. Two come to my mind: -Linear Regression -Gradient Descent
Quiz: Horizon effect example • What is Red’s best move? • If we use a horizon of 2 and the “shortest-path” evaluation, what will Red choose?
Answer: Horizon effect example • What is Red’s best move? If Red moves to either of these squares, Blue can easily block it by moving to the other one. If Red moves to either of these squares, Blue can easily win by moving to the other one.
Answer: Horizon effect example • What is Red’s best move? If Red moves to any of these squares, Blue can win by moving here.
Answer: Horizon effect example • What is Red’s best move? Red’s only chance is to move here first. In fact, if Red does that, Red should win the game. But – that’s hard to see, and requires seeing many moves in advance.
Answer: Horizon effect example • If we use a horizon of 2 and the “shortest-path” evaluation, what will Red choose? This choice gives Red a shortest path of 3. Many of Blue’s responses would decrease Blue’s shortest path to 2 for a difference of 1 in favor of Blue.
Answer: Horizon effect example • If we use a horizon of 2 and the “shortest-path” evaluation, what will Red choose? This choice gives Red a shortest path of 3. Many of Blue’s responses would decrease Blue’s shortest path to 2 for a difference of 1 in favor of Blue. But that’s basically evaluation for many of Red’s moves. So Red has no idea what move is the best move, and must pick randomly.
Memoization Memoization involves remembering/memorizing certain good positions or strategies or moves, to avoid doing a lot of search when such positions or moves become available. Some common examples: • Opening book: A database of good positions for a particular player in the beginning phases of a game, as determined by game experts. (These are especially important for chess.) • Closing book: A database of board positions that are close to the end of the game, with the best possible strategy for completing the game from that position. • Killer moves: A technique of remembering when some move in a game tree results in a big change to the game (eg, someone’s queen gets taken, in chess). If this happens in one place in a game tree, it’s a good idea to check for it in other branches of the tree as well.
Full Algorithm Initial Call: Value(root, 0, -∞, +∞). α: best value for Max found so far. β: best value for Min found so far. Value(n, depth, α, β): • If n is a terminal node, return ∆’s utility • If depth >= cutoff, return E(n) • If n is ∆’s turn: v = -∞ For each c ∊ Children(n): v = max(v, Value(c, depth+1, α, β)) if v >= β: return v (pruning step) α = max(α, v) Return v • If n is ∇’s turn: v = +∞ For each c ∊ Children(n): v = min(v, Value(c, depth+1, α, β)) if v <= α: return v (pruning step) β= min(β, v) Return v
Benefits to Complexity • Reduce b: O(bm) O(bm/2) • Reduce m: O(bm) O(bh), h << m • Memoize: O(bm) O(1), if board position has already been analyzed before Note: alpha-beta pruning is an exact method: the best move using alpha-beta pruning is the same as the best move without it (normal Minimax). Horizon cutoffs are approximate methods: you may get bad results for the choice of an action, if you get a horizon effect.
Example of a Real System: Chinook (checkers player) Checkers: • Red moves first. • Each move is either • a diagonal move one square • a diagonal jump over an opponent’s piece, which removes the opponent’s piece. • Multiple jumps are possible. • If a Jump is available to a player, the player must take it. • Ordinarily, pieces can only move forward. • If a piece gets to the opposite side of the board, it gets “crowned”. • A “crowned” piece can move forward or backwards.
Example of a Real System: Chinook (checkers player) Chinook: Chinook is a computer program that plays Checkers. 1990: It became the first computer program to win the right to compete for a world championship in a game or sport. (It came second in the US National competition.) The Checkers governing body didn’t like that, but they created the World Man-Machine Competition. 1994: Chinook wins the World Man-Machine Competition against Dr. Marion Tinsley, after Tinsley withdraws due to health problems. 1995: Chinook defended its title against Don Lafferty. After that, the program creators decided to retire Chinook. 2007: The program creators proved that the best anyone can do against Chinook is draw.
Example of a Real System: Chinook (checkers player) Chinook: • The Chinook system: • Minimax + alpha-beta pruning • Hand-crafted evaluation function (no learning component) • Linear function with features like: • Num. pieces for each player • How many kings for each player • How many kings are “trapped” • How many pieces are “runaways” – nothing to stop them from being crowned • Opening move database from checkers experts • End-game database that stores the best move from all positions with 8 or fewer pieces.
Stochastic Games Many games (Backgammon, Monopoly, World of Warcraft, etc.) involve some randomness. An attack against another creature may or may not succeed, or the number of squares your piece is allowed to move may depend on a dice roll.
Stochastic Games: Giving Nature a turn ? In Stochastic games, we give “Nature” a turn in the game tree whenever it’s time for a dice roll or some random event. We’ll represent Nature’s turn with a ?, and call these “Chance nodes”. 1 2 3 ∇ ∇ ∇ ? ∆ ∆ 20 4 12 ∆ 1 ? 6 9 5 7 4 10 2 5 -9 15
Stochastic Games: Giving Nature a turn ? We’ll define the Value of a chance node to be the expected value of its children nodes. 1 2 3 ∇ ∇ ∇ ? ∆ ∆ 20 4 12 ∆ 1 ? 1 1 2 2 6 9 5 7 4 10 2 5 -9 15
Quiz: Stochastic Games ? Assume each branch of chance nodes have equal probability. What is the value of the root node for this game tree? 1 2 3 ∇ ∇ ∇ ? ∆ ∆ 20 4 12 ∆ 1 ? 1 1 2 2 6 9 5 7 4 10 2 5 -9 15
Answer: Stochastic Games 2.667 ? Assume each branch of chance nodes have equal probability. What is the value of the root node for this game tree? 1 2 3 ∇ ∇ ∇ 4 1 3 6 10 ? ∆ ∆ 20 4 12 ∆ 1 ? 5 3 9 1 1 2 2 6 9 5 7 4 10 2 5 -9 15
Partially-Observable Games: Poker Example Simple Poker game: Deck contains 2 Ks, 2As. Each player is dealt one card. 1st round: P1 can raise (r) or check (k) 2nd round: P2 can call (c) or fold (f)
Partially-Observable Games: Poker Example ? 1/6: Both K 1/6: Both A 1/3: P1<-K, P2<-A 1/3: P1<-A, P2<-K ∆ ∆ ∆ ∆ k 1 k r k r r k r ∇ ∇ ∇ ∇ -1 0 0 1 -2 1 0 1 2 1 0
Computing equilibria in games with imperfect information If the game has perfect recall (meaning, everyone knows the history of every player’s actions) For 2-player, zero-sum games: Finding equilibria still amounts to Linear Programming. It’s possible to compute equilibria in polynomial time in the size of the game tree. For general-sum games: As hard as the general problem of finding Nash equilibria. For games without perfect recall: hard even for zero-sum games.




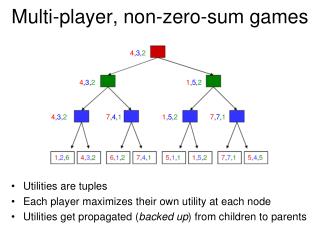













![Market Outlook for Massively Multi-player Online Role-Playing Games in India [2013-2018]](https://cdn4.slideserve.com/7290682/slide1-dt.jpg)
