Download

1 / 17
170 likes | 265 Views
Speaker Identification Using Wavelet Analysis and ANN. Dr. Anupam Shukla Dr. Ritu Tiwari Hemant Kumar Meena Rahul Kala.

E N D
Speaker Identification Using Wavelet Analysis and ANN Dr. AnupamShukla Dr. RituTiwari Hemant Kumar Meena Rahul Kala Shukla, Anupam; Tiwari, Ritu; Meena, Hemant Kumar & Kala, Rahul; “Speaker Identification using Wavelet Analysis and Artificial Neural Networks”, proceedings of the National Symposium on Acoustics (NSA) 2008
Index Introduction Techniques used Procedure Results Conclusion
Introduction • Identification of a person is a very traditional problem. • Finger print recognition, face recognition, signature recognition are common techniques. • Speaker recognition or Automatic Speaker Identification (ASI) identifies an author based on the words spoken. • We have used wavelet analysis to extract the various features and Artificial Neural Networks to identify the speaker by the extracted features.
Common Techniques • Analysis techniques Fourier Analysis Short Time Fourier Analysis Wavelet Analysis • Artificial Neural Networks
Analysis Techniques • We have used Wavelet transform to extract characteristics, which is an advancement over Fourier analysis and Short Time Fourier Analysis (STFT).
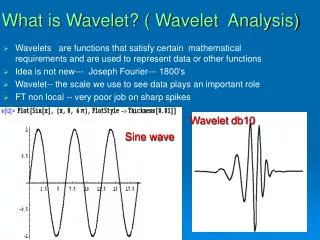
Wavelet Analysis • It is a windowing technique with variable-sized regions. • Wavelet analysis allows the use of different time intervals for different type frequency information.
Wavelet Analysis(Cont..) • Capable of revealing aspects of data • Wavelet packet method • Signal decomposition
Artificial Neural Network • Excellent means of machine learning • Reputed training of the system to learn the given data • Testing • Performance
Procedure • Collection of data sets • Analysis of data sets (feature extraction) • Training of ANN • Testing • Result
Normalization of Data Ii=(Vi - Mean(Vij) ) / (Max(Vij)- Mean(Vij) ), for all j Here Ii is th ith input of the neural network Vi is the ith feature extracted from Wavelet Analysis Mean(Vi) is the mean of all Vij found in the training data set Max(Vi) is the maximum of all Vij found in training data set for all j in data set
Result • Performance of 97.5% • This clearly shows that the algorithm works well and gives correct results on almost all inputs. • 20 speakers and 40 test cases (39 correctly identified)