Download

1 / 50
500 likes | 574 Views
Explore the fundamentals of internal file structure, file manipulation operations, and file access operations. Understand common file organizations and file management systems to optimize data handling and storage.

E N D
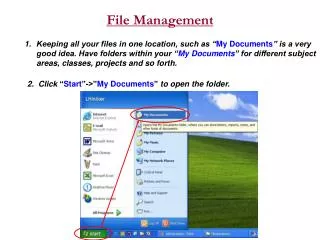
File Management Marc’s first try, Please don’t sue me.
Introduction • Files • Long-term existence • Can be temporally decoupled from applications • Sharable between processes • Can be structured to the task • Can be viewed in various logical manners • Can have permissions for individuals or groups • Can be manipulated in a variety of ways
File Manipulation Operations • Create • Delete • Open • Close • Read (all or a portion) • Write (append or update)
Internal File Structure • Byte (most UNIX) • Field • Record • File • Database
Internal File Structure (cont) • Field: • Basic logical element of data • Characterized by length and data type • ASCII String, decimal, integer, etc • Fixed or variable length • With variable-length, may have subfields • Length may be indicated by demarcation
Internal File Structure (cont) • Record: • A collection of related fields • Can be treated as a unit by app or user • Can be fixed or variable length • If # of fields is variable, each has a name • Entire record usually has a length
Internal File Structure (cont) • File: • A collection of similar records • Treated as a single entity • Can be referenced by name • Access control restrictions implemented • Sometimes enforced at the record or field level
Internal File Structure (cont) • Database: • Collection of related data (many files) • Various explicit relationships between data • Usually managed by a DBMS • Not usually ‘built-in’ to an OS
Internal File Structure (cont) • Database: • Collection of related data (many files) • Various explicit relationships between data • Usually managed by a DBMS • Not usually ‘built-in’ to an OS
File Access Operations Operating primarily on records, but abstraction can be applied to just bytes: • Retrieve_All • Read all records into memory in sequence • Retrieve_One • Usually associated with interactive, transaction-oriented applications
File Access Operations (cont) • Retrieve_Next/Previous • Retrieve next record in some predefined logical sequence. • Often associated with search • Insert_One • May involve random access, or appending • Delete_One • Certain linkages or other data structures may require updating to preserve sequencing
File Access Operations (cont) • Update_One • One-two punch: • Retrieve a record, update one or more fields, then rewirte the updated record back into the file. • With variable-length fields/records, may require much more data structure manipulation. • Retrieve_Few • Get some specified number of records • Usually used in databases when selecting on certain criteria
File Management Systems • Meet data management requirements of user • Guarantee, whenever possible, that file data are valid • Optimize performance (both throughput and response time) • Provide I/O support for various storage devices • Minimize or eliminate the potential for lost or destroyed data • Provide a standardized set of I/O interface routines to use processes • Provide I/O support for multiple users
File System Architecture • Device drivers • Responsible for starting and completing I/O requests to various peripheral devices • Basic file system (physical I/O level in OS) • Deals with interchange of blocks of data • Does not understand content • Basic I/O supervisor (part of OS) • Maintains control structures for device I/O, scheduling, and file status. • Logical I/O • General-purpose facility for accessing records • Maintains basic data about files (indices, etc)
File Organization and Access • Several, sometimes conflicting criteria for organization of files: • Short access time • Ease of update • Economy of storage • Simple maintenance • Reliability • Conflict: economy of storage vs. redundancy Redundancy increases access speed and reliability, but also increases storage requirements
Common File Organizations • Pile • Data are collected in the order in which they arrive • Each record consists of one burst of data • Records may have a wildly varying assortment of fields and field-lengths • Each field must be self-describing • Record access is by exhaustive search. • When you don’t know what you’ll get, this uses space well and is easy to update
Common File Organizations (cont) • Sequential File • Fixed format used for records • Length and position of each field known, requiring that only values of fields must be stored • First field of every record is key field, records then stored in key sequence (can have variations) • NOT good for interactive applications with individual record queries or updates • Inserting records is also inefficent, requiring periodic “batch merges” • Can be implemented by organizing file physically as linked list
Common File Organizations (cont) • Indexed Sequential File • Uses an index to support random access • Requires an overflow file to handle additions • Index uses same key as main file, and has a pointer into the file, greatly improves search time. • Can have multilevel indices to get blazing fast speed
Common File Organizations (cont) • Indexed File • Uses an index to support random access • Maintains multiple indices for each type of field that may be the subject of a search • Records are accessed only by their indices, never by traversal • Variable-length fields can be used • Exhaustive index and partial index may be used
Common File Organizations (cont) • Hashed File • Hashes on the key value to go directly to the record on disk. • Primarily efficient for fixed-length records and Retreive_One operations
File Directories • Is almost always a file itself • Contains info for each file like: • File name, type, organization • Volume, starting address, size used/allocated • Owner, access info, permitted actions • Creation date, creator, last accessed, last accessor, last modified, last modifier, last backup, current usage
File Directory Operations • Search • Locate directory entry corresponding to specified file • Create file • Add new directory entry • Delete file • Remove directory entry • List • Show directory contents, with possible filters • Update • Change properties of the directory or some file attributes only stored in the directory
Directory Structure • Could have a simple, single directory • Many files make it unwieldy for users • Hierarchical approach is widely used • Master directory with a number of files and other directories contained within • Recursive substructure allows virtually unlimited (in modern systems) number of levels • Usually uses a hashed structure to store entries
Directory Structure (cont) • Naming • Directory trees prevent the need for unique file or directory names on different levels • Pathname (in UNIX) specifies the “level” from the top (root or master directory) • /User_B/Draw/ABC • Too complicated to specify full path every time, so we have concept of working directory, both for applications and users: • If in User_B directory: access ./Draw/ABC
Access Rights • Individuals or groups of users are granted certain rights to files or directories, in the following hierarchy: • None • Can’t even know about existence of file or directory • Knowledge • User can determine that file exists and its owner • Execution • User can load & execute program but cannot copy • Read • User can read file for any purpose • Append • User can add data to the file but cannot modify or delete • Update • User can modify, delete, and add to the file’s data (possibly graded) • Change protection • User can change the access rights granted to other users • Deletion • User can delete the file from the file system and do anything else.
Simultaneous Access When access is granted to append or update a file to more than one user, the OS or file management system must enforce discipline. A brute-force approach is to allow a user to lock the entire file when it is to be updated. A finer grain of control is to lock individual records during update. This is the readers/writers problem, and the classic issues of mutual exclusion and deadlock must be addressed.
Record Blocking • Blocks are the unit of I/O for secondary storage • Records are logical unit of access, and must be organized in blocks to perform I/O • Three methods: • Fixed blocking • Fixed-length records are used, with integral number of records stored in a block. Internal fragmentation • Variable-length spanned blocking • Variable-length records are used, packed into blocks with no unused space. Pointers used to span blocks • Variable-length unspanned blocking • Same as above without spanning, with wasted space in most blocks, because of inability to use remainders
Record Blocking (cont) • Fixed blocking common for sequential files with fixed-length records • Variable-length spanned blocking is efficient of storage and does not limit record size, but more complicated to implement and sometimes inefficient. Files are more difficult to update • Variable-length unspanned blocking results in wasted space and limits record size to the size of the block • Record-blocking technique may interact with VM. Page may be implemented as integral number of blocks, or vice versa
File Allocation • Preallocation vs Dynamic Allocation • Preallocation • Max file size is declared at time of creation • Almost impossible to estimate reliably for most applications • Potentially very wasteful • Dynamic: • Allocate space to a file in portions as necessary • Sound familiar?
File Allocation (cont) • Portion Size • Choosing a size is a tradeoff. Consider: • Contiguity of space increases performance, especially for Retrieve_Next • Having a large number of small portions increases the size of tables needed to manage the allocation info • Having fixed-size portions (blocks) simplifies the reallocation of space • Having variable-size or small fixed-size portions minimizes waste of unused storage due to overallocation • Leads to 2 alternatives: • Variable, large contiguous portions • Better performance, but space hard to reuse • Blocks • Provide greater flexibility, but may require complex FA structures
File Allocation (cont) • Methods • Contiguous allocation – preallocation • File Allocation Table (FAT) needs one entry per file, showing start block and length • External fragmentation occurs fairly quickly • Defragmentation is required to maintain performance • Chained allocation • On individual block basis • Each block contains a pointer to next block • Any free block can be added to a chain • No external fragmentation • Unfortunately, cannot capitalize on principle of locality
File Allocation (cont) • Indexed allocation • FAT contains a separate one-level index per file • File index kept in its own block • Allocation can be in either fixed-size blocks or variable-size portions • By blocks eliminates external fragmentation • By portions improves locality • File consolidation on a regular basis will improve performance • Supports both sequential and direct access
File Allocation (cont) • Free Space Management –In addition to FAT we need disk allocation table (DAT) to manage free space • Bit Tables • A vector containing one bit for each block on the disk • Can be very fast in main memory, tradeoff is space • Chained Free Portions • Free portions are chained together by using a pointer and length value in each free portion • Lends itself to high amounts of fragmentation, and even deletion of highly fragmented files becomes a chore • Indexing (only for variable-size portions) • Treats free space like a file and uses an index table. • One entry for every free portion, quite efficient • Free Block List • Each block assigned a number sequentially and list of the numbers of all free blocks is maintained in a reserved portion of the storage. • Efficiency can be achieved by maintaining a small portion of the list in memory at any given time
Reliability • Consider this scenario: • User A requests a file allocation to add to an existing file • The request is granted and the disk and file allocation tables are updated in main memory but not yet on disk • The system crashes and subsequently restarts • User B requests a file allocation and is allocated space on disk that overlaps the last allocation to user A • User A accesses the overlapped portion via a reference that is stored inside A’s file
Reliability (cont) • Solution: • Lock the disk allocation table on disk, preventing another user from altering the table until the current allocation is completed • Search the DAT (in memory) for available space • Allocate space, update DAT, and update disk (write DAT back to disk, and possibly update pointers for chained allocation). • Update the FAT on disk • Unlock the DAT