Download
1 / 28
320 likes | 681 Views
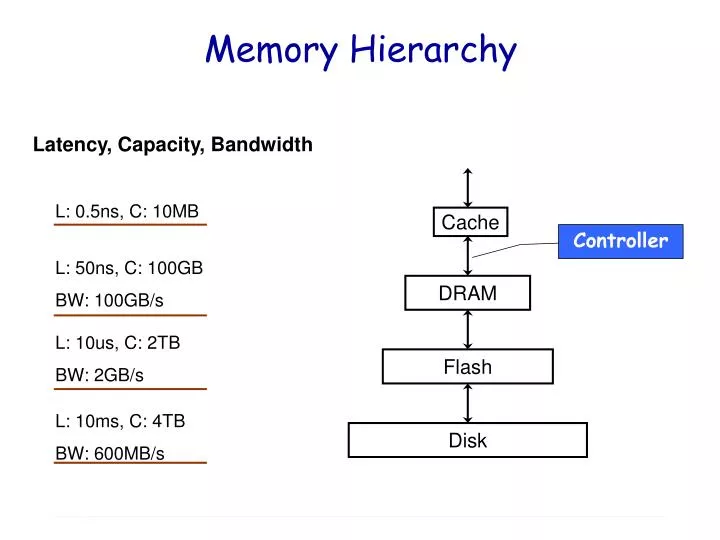
Memory Hierarchy. Latency, Capacity, Bandwidth. L: 0.5ns, C: 10MB. Cache. Controller. L: 50ns, C: 100GB BW: 100GB/s. DRAM. L: 10us, C: 2TB BW: 2GB/s. Flash. L: 10ms, C: 4TB BW: 600MB/s. Disk. DRAM Primer. <bank, row, column>. Page buffer per bank. DRAM Characteristics.

E N D
Memory Hierarchy Latency, Capacity, Bandwidth L: 0.5ns, C: 10MB Cache Controller L: 50ns, C: 100GB BW: 100GB/s DRAM L: 10us, C: 2TB BW: 2GB/s Flash L: 10ms, C: 4TB BW: 600MB/s Disk
DRAM Primer <bank, row, column> Page buffer per bank
DRAM Characteristics • DRAM page crossing • Charge ~10K DRAM cells and bitlines • Increase power & latency • Decrease effective bandwidth • Sequential access VS. random access • Less page crossing • Lower power consumption • 4.4x shorter latency • 10x better BW
Embedded Controller Bad News Good News • None available as in general purpose processor • Opportunities for customization
Agenda • Overview • Multi-Port Memory Controller (MPMC) Design • “Out-of-Core” Algorithmic Exploration
Motivating Example: H.264 Decoder • Diverse QoS requirements Bandwidth sensitive Latency sensitive 1.2 6.4 9.6 164.8 Dynamic latency, BW and power 0.09 31.0 156.7 94 MB/s
Wanted • Bandwidth guarantee • Prioritized access • Reduced page crossing
Previous Works • Bandwidth guarantee • Q0: Distinguish bandwidth guarantee for different classes of ports • Q1: Distinguish bandwidth guarantee for each port • Q2: Prioritized access • Q3: Residual bandwidth allocation • Q4: Effective DRAM bandwidth
Key Observations • Weighted round robin: • Minimum BW guarantee • Busting service • Credit borrow & repay • Reorder requests according to priority • Dynamic BW calculation • Capture and re-allocate residual BW • Port locality: • Same port requests same DRAM page • Service time flexibility • 1/24 second to decode a video frame • 4M cycles at 100 MHz for request reordering • Residual bandwidth • Statically allocated BW • Underutilized at runtime
Weighted Round Robin • Assume bandwidth requirement • Q2: 30% Q1: 50% Q0: 20% Tround = 10 Time: scheduling cycles T(Rij): arriving time of jth requests for Qi Clock: 0 1 2 3 4 5 6 7 8 9 Request time: T(R2) R20 R21 R22 Q2 R20 R21 R22 Service time: T(R1) R10 R11 R12 R13 R14 Q1 R10 R11 R12 R13 R14 T(R0) R00 R01 R00 R01 Q0
Problem with WRR • Priority: Q0 > Q2 Clock: 0 1 2 3 4 5 6 7 8 9 T(R2) R20 R21 R22 Q2 R20 R21 R22 T(R1) R10 R11 R12 R13 R14 Q1 R10 R11 R12 R13 R14 T(R0) R00 R01 R00 R01 Q0 Could be worse! 8 cycles of waiting time!
Borrow Credits • Zero Waiting time for Q0! Clock: 0 1 2 3 4 5 6 7 8 9 T(R2) R20 R21 R22 Q2 R20 T(R1) R10 R11 R12 Q1 borrow T(R0) R00 R01 Q0* R00 R01 debtQ0 Q2 Q2 Q2
Repay Later • At Q0’s turn, BW guarantee is recovered Clock: 0 1 2 3 4 5 6 7 8 9 T(R2) R20 R21 R22 Q2 R20 R21 R22 T(R1) R10 R11 R12 R13 R14 repay Q1 R10 R11 R12 R13 R14 T(R0) R00 R01 Q0* R00 R01 debtQ0 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Prioritized access!
Problem: Depth of DebtQ • DebtQ as residual BW collector • BW allocated to Q0 increases to: 20% + residual BW • Requirement for the depth of DebtQ0 decreases Clock: 0 1 2 3 4 5 6 7 8 9 T(R2) R20 R21 R22 Q2 R20 R21 R22 T(R1) R10 R11 R12 R13 Help repay Q1 R10 R11 R12 R13 T(R0) R00 R01 R03 Q0* R00 R01 R03 debtQ0 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2 Q2
Evaluation Framework • Simulation Framework • Workload: ALPBench suite • DRAMSim: simulates DRAM latency+BW+power • Reference schedulers: PQ, RR, WRR, BGPQ
Bandwidth Guarantee • Bandwidth guarantees: • P0: 2% P1: 30% P2: 20% P3:20% P4:20% • System residual: 8% NoBWguarantee ProvidesBWguarantee!
Cache Response Latency • Average 16x faster than WRR • As fast as PQ (prioritized access) Latency (ns)
DRAM Energy & BW Efficiency • 30% less page crossing (compared to RR) • 1.4x more energy efficient • 1.2x higher effective DRAM BW • As good as WRR (exploit port locality)
Hardware Cost • BCBR: frontend • 1393 LUTs • 884 registers • 0 BRAM • Reference backend: speedy DDRMC • 1986 LUTs • 1380 registers • 4 BRAMs • Xilinx MPMC: frontend + backend • 3450 LUTs • 5540 registers • 1-9 BRAMs • BCBR + Speedy • 3379 LUTs • 2264 registers • 4 BRAMs Better performance without higher cost!
Agenda • Overview • Multi-Port Memory Controller (MPMC) Design • “Out-of-Core” Algorithm / Architecture Exploration
Idea • Out-of-core algorithms • Data does not fit DRAM • Performance dominated by IO • Key questions • Reduce #IOs • Block granularity • Remember DRAM=DISK • So let’s • Ask the same question • Plug-on DRAM parameters • Get DRAM-specific answers
Motivating Example: CDN • Caches in CDN • Get closer to users • Save bandwidth • Zipf’s law • 80-20 rule hit rate
Defining the Knobs • Transaction • a number of column access commands enclosed by row activation / precharge • W: burst size • s : # bursts Function of algorithmic parameters Function of array organization & timing params Function of array organization & timing params
D-nary Heap Algorithmic Design Variable: Branching Factor Record Size
Lessons Learned • Optimal result can be beautifully derived! • Big O does not matter in some cases • Depending on data input characteristics






















