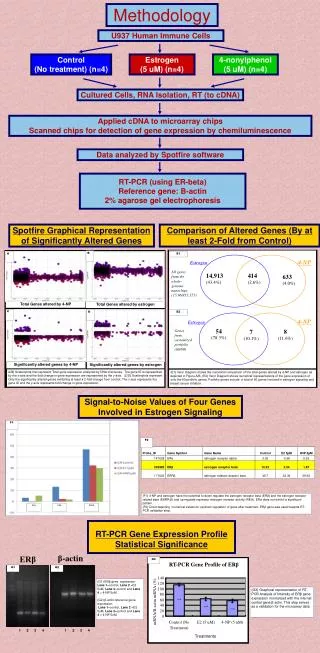
Download
1 / 1
10 likes | 116 Views
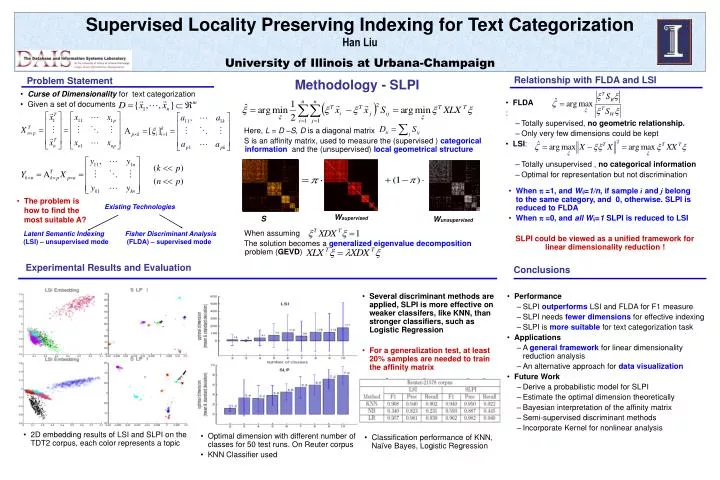
Supervised Locality Preserving Indexing for Text Categorization Han Liu University of Illinois at Urbana-Champaign. Problem Statement. Relationship with FLDA and LSI. Methodology - SLPI. Curse of Dimensionality for text categorization

E N D
Supervised Locality Preserving Indexing for Text Categorization Han Liu University of Illinois at Urbana-Champaign Problem Statement Relationship with FLDA and LSI Methodology - SLPI • Curse of Dimensionality for text categorization • Given a set of documents , • FLDA : • Totally supervised, no geometric relationship. • Only very few dimensions could be kept • LSI: • Totally unsupervised , no categorical information • Optimal for representation but not discrimination Here, L = D –S, D is a diagonal matrix S is an affinity matrix, used to measure the (supervised ) categorical information and the (unsupervised) local geometrical structure • When p =1, and Wij=1/n, if sample i and j belong to the same category, and 0, otherwise. SLPI is reduced to FLDA • When p =0, and all Wij=1 SLPI is reduced to LSI SLPI could be viewed as a unified framework for linear dimensionality reduction ! • The problem is how to find the most suitable A? Existing Technologies Wsupervised S Wunsupervised When assuming The solution becomes a generalized eigenvalue decomposition problem (GEVD) Latent Semantic Indexing (LSI) – unsupervised mode Fisher Discriminant Analysis (FLDA) – supervised mode Experimental Results and Evaluation Conclusions • Performance • SLPI outperforms LSI and FLDA for F1 measure • SLPI needs fewer dimensions for effective indexing • SLPI is more suitable for text categorization task • Applications • A general framework for linear dimensionality reduction analysis • An alternative approach for data visualization • Future Work • Derive a probabilistic model for SLPI • Estimate the optimal dimension theoretically • Bayesian interpretation of the affinity matrix • Semi-supervised discriminant methods • Incorporate Kernel for nonlinear analysis • Several discriminant methods are applied, SLPI is more effective on weaker classifers, like KNN, than stronger classifiers, such as Logistic Regression • For a generalization test, at least 20% samples are needed to train the affinity matrix • 2D embedding results of LSI and SLPI on the TDT2 corpus, each color represents a topic • Optimal dimension with different number of classes for 50 test runs. On Reuter corpus • KNN Classifier used • Classification performance of KNN, Naïve Bayes, Logistic Regression