Download
1 / 1
10 likes | 180 Views
STEMMA: a new system for multilingual semio/syntactic parsing for applications to synthetic speech prosodic stylization Per Aage Brandt* and Patrizia Bonaventura** *Department of Modern Languages and Literatures **Department of Communication Sciences.

E N D
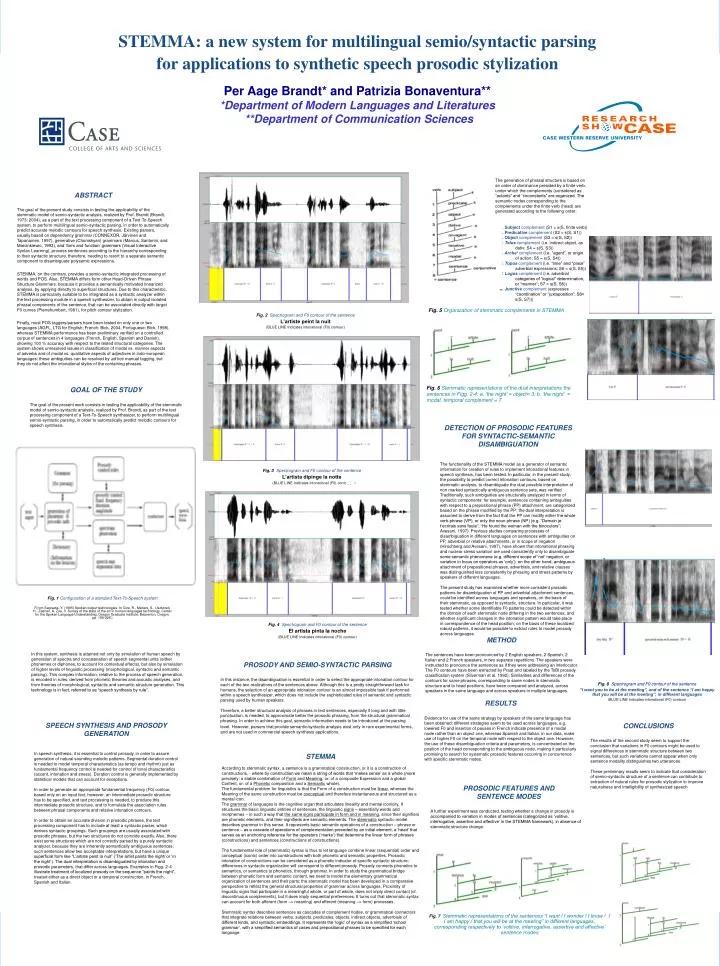
STEMMA: a new system for multilingual semio/syntactic parsing for applications to synthetic speech prosodic stylization Per Aage Brandt* and Patrizia Bonaventura** *Department of Modern Languages and Literatures **Department of Communication Sciences The generation of phrasal structure is based on an order of dominance presided by a finite verb, under which the complements (considered as “actants” and “circonstants” are organized. The semantic nodes corresponding to the complements under the finite verb (head) are generated according to the following order: ABSTRACT The goal of the present study consists in testing the applicability of the stemmatic model of semio-syntactic analysis, realized by Prof. Brandt (Brandt, 1973; 2004), as a part of the text processing component of a Text-To-Speech system, to perform multilingual semio-syntactic parsing, in order to automatically predict accurate melodic contours for speech synthesis. Existing parsers, usually based on dependency grammar (CONNEXOR, Järvinen and Tapanainen, 1997), generative (Chomskyan) grammars (Marcus, Santorini, and Marcinkiewic, 1993), and ‘form and function’ grammars (Visual Interactive Syntax Learning), process sentences according to the hierarchy corresponding to their syntactic structure, therefore, needing to resort to a separate semantic component to disambiguate polysemic expressions. STEMMA, on the contrary, provides a semio-syntactic integrated processing of words and POS. Also, STEMMA differs form other Head-Driven Phrase Structure Grammars, because it provides a semantically motivated linearized analysis, by applying directly to superficial structures. Due to this characteristic, STEMMA is particularly suitable to be integrated as a syntactic analyzer within the text processing module in a speech synthesizer, to obtain in output isolated phrasal components of the sentence, that can be associated directly with target F0 curves (Pierrehumbert, 1981), for pitch contour stylization. Finally, most POS taggers/parsers have been tested on only one or two languages (AGFL, LTG for English; French: Bick, 2004; Portuguese: Bick, 1998), whereas STEMMA performance has been preliminary verified on a controlled corpus of sentences in 4 languages (French, English, Spanish and Danish), showing 100 % accuracy with respect to the tested structural categories. The system shows unresolved issues in classification of modal vs. manner aspects of adverbs and of modal vs. qualitative aspects of adjectives in indo-european languages; these ambiguities can be resolved by ad hoc manual tagging, but they do not affect the intonational styles of the containing phrases. 1. Subject complement (S1 = s(S, finite verb)) 2. Predicative complement (S2 = s(S, S1)) 3. Object complement (S3 = s(S, S2)) 4. Telos complement (i.e. indirect object, as dativ; S4 = s(S, S3)) 5. Arche’complement (i.e. “agent”, or origin of action; S5 = s(S, S4)) 6. Toposcomplement (i.e. “time” and “place” adverbial expressions; S6 = s(S, S5)) 7. Logos complement (i.e. adverbial categories of “logical” determination, or “manner”; S7 = s(S, S6)) 8. Junctive complement (expresses “coordination” or “juxtaposition”; S8= s(S, S7))) Fig. 5Organization of stemmatic complements in STEMMA • Fig. 2Spectrogram and F0 contour of the sentence • L’artiste peint la nuit • (BLUE LINE Indicates intonational (F0) contour) GOAL OF THE STUDY The goal of the present work consists in testing the applicability of the stemmatic model of semio-syntactic analysis, realized by Prof. Brandt, as part of the text processing component of a Text-To-Speech synthesizer, to perform multilingual semio-syntactic parsing, in order to automatically predict melodic contours for speech synthesis. Fig. 6Stemmatic representations of the dual interpretations the sentences in Figg. 2-4: a. ‘the night’ = object= 3; b. ‘the night’ = modal, temporal complement = 7 • DETECTION OF PROSODIC FEATURES FOR SYNTACTIC-SEMANTIC DISAMBIGUATION • The functionality of the STEMMA model as a generator of semantic information for creation of rules to implement intonational features in speech synthesis, has been tested. In particular, in the present study, the possibility to predict correct intonation contours, based on stemmatic analysis, to disambiguate the dual possible interpretation of non marked syntactically ambiguous sentence sets, was verified. • Traditionally, such ambiguities are structurally analyzed in terms of syntactic components: for example, sentences containing ambiguities with respect to a prepositional phrase (PP) attachment, are categorized based on the phrase modified by the PP: the dual interpretation is assumed to derive from the fact that the PP can modify either the whole verb phrase (VP), or only the noun phrase (NP) (e.g. “Demain je t’ecrirais sans faute”; “He found the woman with the binoculars”; Avesani, 1997). Previous studies comparing processes of disambiguation in different languages on sentences with ambiguities on PP, adverbial or relative attachments, or in scope of negation (Hirschberg and Avesani, 1997), have shown that intonational phrasing and nuclear stress variation are used consistently only to disambiguate some semantic phenomena (e.g. different scope of ‘not’ negation, or variation in focus on operators as ‘only’); on the other hand, ambiguous attachment of prepositional phrases, adverbials, and relative clauses was distinguished less consistently by phrasing and stress patterns by speakers of different languages. • The present study has examined whether more consistent prosodic patterns for disambiguation of PP and adverbial attachment sentences, could be identified across languages and speakers, on the basis of their stemmatic, as opposed to syntactic, structure. In particular, it was tested whether some identifiable F0 patterns could be detected within the domain of each stemmatic node differing in the two sentences, and whether significant changes in the intonation pattern would take place in correspondence of the head position; on the basis of these localized robust patterns, it would be possible to extract rules to model prosody across languages. • Fig. 3Spectrogram and F0 contour of the sentence • L’artista dipinge la notte • (BLUE LINE Indicates intonational (F0) contour) Fig. 1Configuration of a standard Text-To-Speech system F(rom Sagisaka, Y. (1995) Spoken output technologies. In Cole, R., Mariani, S., Uszkoreit, H., Zaenen, A. Zue, V. Survey of the state of the art in human languages technology. Center for the Spoken Language Understanding, Oregon Graduate Institute, Beaverton, Oregon. pp. 189-226 ) • Fig. 4Spectrogram and F0 contour of the sentence • El artista pinta la noche • (BLUE LINE Indicates intonational (F0) contour) METHOD The sentences have been pronounced by 2 English speakers, 2 Spanish, 2 Italian and 2 French speakers, in two separate repetitions. The speakers were instructed to pronounce the sentences as if they were addressing an interlocutor. The F0 contours have been extracted by Praat and labeled by the ToBI prosody classification system (Silverman et al. 1992). Similarities and differences of the contours for same phrases, corresponding to same nodes in stemmatic structure and to head positions, have been compared and analyzed, across speakers in the same language and across speakers in multiple languages. In this system, synthesis is attained not only by simulation of human speech by generation of spectra and concatenation of speech segmental units (either phonemes or diphones, to account for contextual effects), but also by simulation of higher levels of linguistic processing (morphological, syntactic and semantic parsing). This complex information, relative to the process of speech generation, is encoded in rules, derived from phonetic theories and acoustic analyses, and from theories of morphological, syntactic and semantic structure generation. This technology is in fact, referred to as “speech synthesis by rule”. PROSODY AND SEMIO-SYNTACTIC PARSING In this instance, the disambiguation is essential in order to select the appropriate intonation contour for each of the two realizations of the sentences above. Although this is a pretty straightforward task for humans, the selection of an appropriate intonation contour is an almost impossible task if performed within a speech synthesizer, which does not include the sophisticated rules of semantic and syntactic parsing used by human speakers. Therefore, a better structural analysis of phrases in text sentences, especially if long and with little punctuation, is needed, to approximate better the prosodic phrasing, from the structural grammatical phrasing. In order to achieve this goal, semantic information needs to be introduced at the parsing level.However, parsers that provide semantic/syntactic analysis exist only in rare experimental forms, and are not used in commercial speech synthesis applications. • Fig. 8Spectrogram and F0 contour of the sentence • “I want you to be at the meeting”, and of the sentence “I am happy that you will be at the meeting”, in different languages • (BLUE LINE Indicates intonational (F0) contour) RESULTS Evidence for use of the same strategy by speakers of the same language has been obtained; different strategies seem to be used across languages, e.g. lowered F0 and insertion of pauses in French indicate presence of a modal node rather than an object one, whereas Spanish and Italian, in our data, make use of higher F0 on the temporal node with respect to the object one. However, the use of these disambiguation criteria and parameters, is concentrated on the position of the head corresponding to the ambiguous node, making it particularly promising to search for systematic prosodic features occurring in concurrence with specific stemmatic nodes. • SPEECH SYNTHESIS AND PROSODY GENERATION • In speech synthesis, it is essential to control prosody, in order to assure generation of natural sounding melodic patterns. Segmental duration control is needed to model temporal characteristics (as tempo and rhythm) just as fundamental frequency control is needed for control of tonal characteristics (accent, intonation and stress). Duration control is generally implemented by statistical models that can account for exceptions. • In order to generate an appropriate fundamental frequency (F0) contour, based only on an input text, however, an intermediate prosodic structure has to be specified, and text processing is needed, to produce this intermediate prosodic structure, and to formulate the association rules between phrasal components and relative intonation contours. • In order to obtain an accurate division in prosodic phrases, the text processing component has to include at least a syntactic parser, which derives syntactic groupings. Such groupings are usually associated with prosodic phrases, but the two structures do not coincide exactly. Also, there exist some structures which are not correctly parsed by a purely syntactic analyzer, because they are inherently semantically ambiguous sentences; such sentences allow two acceptable interpretations, but have a unique superficial form like “L’artiste peint la nuit” (‘The artist paints the night/ or ‘in the night’). The dual interpretation is disambiguated by intonation and prosodic parameters, that differ across languages. Examples in Figg. 2-4 illustrate treatment of localized prosody on the sequence “paints the night”, treated either as a direct object or a temporal construction, in French, SpanishandItalian. CONCLUSIONS The results of the second study seem to support the conclusion that variations in F0 contours might be used to signal differences in stemmatic structure between two sentences, but such variations cannot appear when only sentence modality distinguishes two utterances. These preliminary results seem to indicate that consideration of semio-syntactic structure of a sentence can contribute to extraction of natural rules for prosodic stylization to improve naturalness and intelligibility of synthesized speech STEMMA According to stemmatic syntax, a sentence is a grammatical construction, or it is a construction of constructions, - where by construction we mean a string of words that ‘makes sense’ as a whole (more precisely: a stable combination of Form and Meaning, or: of a composite Expression and a global Content, or: of a Phonetic composition and a Semantic whole). The fundamental problem for linguistics is that the Form of a construction must be linear, whereas the Meaning of the same construction must be conceptual and therefore instantaneous and structured as a mental icon. The grammar of languages is the cognitive organ that articulates linearity and mental iconicity. It structures the basic linguistic entities of sentences, the linguistic signs – essentially words and morphemes – in such a way that the same signs participate in form and in meaning, since their signifiers are phonetic elements, and their signifieds are semantic elements. The stemmatic syntactic model describes grammar in this sense. It represents basic semantic operations of a construction – phrase or sentence – as a cascade of operations of complementation preceded by an initial element, a ‘head’ that serves as an anchoring reference for the operators (‘marks’) that determine the linear form of phrases (constructions) and sentences (constructions of constructions). The fundamental role of (stemmatic) syntax is thus to let language combine linear (sequential) order and conceptual (iconic) order into constructions with both phonetic and semantic properties. Prosodic intonation of constructions can be considered as a phonetic indicator of specific syntactic structure; differences in syntactic organization will correspond to different prosody. Prosody connects phonetics to semantics, or semantics to phonetics, through grammar. In order to study the grammatical bridge between phonetic form and semantic content, we need to model the elementary grammatical organization of sentences and their parts; the stemmatic model has been developed in a comparative perspective to reflect the general structural properties of grammar across languages. Proximity of linguistic signs that participate in a meaningful whole, or part of whole, does not imply direct contact (cf. discontinuous complements), but it does imply sequential preferences. It turns out that stemmatic syntax can account for both afferent (form –> meaning) and efferent (meaning –> form) processes. Stemmatic syntax describes sentences as cascades of complement nodes, or grammatical connectors that integrate relations between verbs, subjects, predicates, objects, indirect objects, adverbials of different kinds, and syntactic embeddings. It represents the ‘logic’ of syntax as a simplified ‘school grammar’, with a simplified semantics of cases and prepositional phrases to be specified for each language. PROSODIC FEATURES AND SENTENCE MODES A further experiment was conducted, testing whether a change in prosody is accompanied to variation in modes of sentences (categorized as ‘volitive, interrogative, assertive and affective’ in the STEMMA framework), in absence of stemmatic structure change. • Fig. 7Stemmatic representations of the sentences “I want / I wonder / I know / I I am happy / that you will be at the meeting” in different languages, corresponding respectively to ‘volitive, interrogative, assertive and affective’ sentence modes


















