Download
1 / 11
110 likes | 226 Views
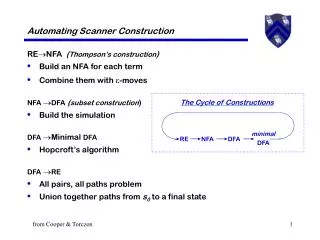
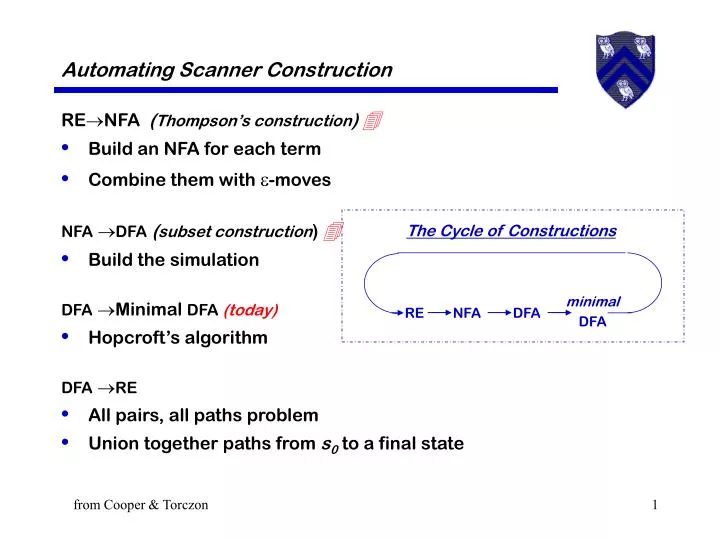
The Cycle of Constructions. minimal DFA. RE. NFA. DFA. Automating Scanner Construction. RENFA ( Thompson’s construction ) Build an NFA for each term Combine them with -moves NFA DFA ( subset construction ) Build the simulation DFA Minimal DFA (today)

E N D
The Cycle of Constructions minimal DFA RE NFA DFA Automating Scanner Construction RENFA (Thompson’s construction) • Build an NFA for each term • Combine them with -moves NFA DFA(subset construction) • Build the simulation DFA Minimal DFA (today) • Hopcroft’s algorithm DFA RE • All pairs, all paths problem • Union together paths from s0to a final state from Cooper & Torczon
DFA Minimization The Big Picture • Discover sets of equivalent states • Represent each such set with just one state Two states are equivalent if and only if: • The set of paths leading to them are equivalent • , transitions on lead to equivalent states (DFA) • transitions to distinct sets states must be in distinct sets A partition P of S • Each s S is in exactly one set pi P • The algorithm iteratively partitions the DFA’s states from Cooper & Torczon
DFA Minimization Details of the algorithm • Group states into maximal size sets, optimistically • Iteratively subdivide those sets, as needed • States that remain grouped together are equivalent Initial partition, P0 , has two sets {F} & {Q-F} (D =(Q,,,q0,F)) Splitting a set • Assume qa, qb, & qcs, and • (qa,a) = qx, (qb,a) = qy, & (qa,a) = qz • If qx, qy, & qz are not in the same set, then s must be split • One state in the final DFA cannot have two transitions on a from Cooper & Torczon
DFA Minimization The algorithm Why does this work? • Partition P 2Q • Start off with 2 subsets of Q {F} and {Q-F} • While loop takes PiPi+1 by splitting 1 or more sets • Pi+1 is at least one step closer to the partition with |Q | sets • Maximum of |Q | splits Note that • Partitions are never combined • Initial partition ensures that final states are intact P { F, {Q-F}} while ( P is still changing) T { } for each set s P for each partition s by into s1, s2, …, sk T T s1, s2, …, sk if T P then P T This is a fixed-point algorithm! from Cooper & Torczon
a a a b b s0 s1 s3 s4 a b a b s2 b b a a a b b s0 , s2 s1 s3 s4 a b DFA Minimization Enough theory, does this stuff work? • Recall our example: ( a | b)*abb final state from Cooper & Torczon
b s2 b a s0 s1 b c c s3 c Final states DFA Minimization What about a ( b | c )* ? First, the subset construction: b q5 q4 a q0 q1 q2 q3 q9 q8 c q7 q6 from Cooper & Torczon
b s2 b | c b a s0 s1 a b c s0 s1 c s3 c DFA Minimization Then, apply the minimization algorithm To produce the minimal DFA final states In lecture 6, I said that a human would design a simpler automaton than Thompson’s construction did. The algorithms produce that same DFA! from Cooper & Torczon
Limits of Regular Languages Advantages of Regular Expressions • Simple & powerful notation for specifying patterns • Automatic construction of fast recognizers • Many kinds of syntax can be specified with REs Example — an expression grammar Term [a-zA-Z] ([a-zA-z] | [0-9])* Op + | - | | / Expr ( Term Op )*Term Of course, this would generate a DFA … If REs are so useful … Why not use them for everything? from Cooper & Torczon
Limits of Regular Languages Not all languages are regular RL’s CFL’s CSL’s You cannot construct DFA’s to recognize these languages • L = { pkqk }(parenthesis languages) • L = { wcw r| w *} Neither of these is a regular language(nor an RE) But, this is a little subtle. You can construct DFA’s for • Alternating 0’s and 1’s ( | 1)( 0 | 1) ( 0 | ) • Sets of pairs of 0’s and 1’s ( 01 | 10 ) ( 01 | 10 )* RE’s can count bounded sets and bounded differences from Cooper & Torczon
What can be so hard? Poor language design can complicate scanning • Reserved words are important if then then then = else; else else = then (PL/I) • Significant blanks (Fortran & Algol68) do 10 i = 1,25 do 10 i = 1.25 • String constants with special characters (C, others) newline, tab, quote, comment delimiters, … • Finite closures • Limited identifier length • Adds states to count length from Cooper & Torczon
What can be so hard? (Fortran 66/77) • How does a compiler do this? • First pass finds & inserts blanks • Can add extra words or tags to • create a scanable language • Second pass is normal scanner Example due to Dr. F.K. Zadeck from Cooper & Torczon