Download

1 / 19
190 likes | 337 Views
Graphplan. The Dock-Worker Robots (DWR) Domain. informal description: harbour with several locations (docks), docked ships, storage areas for containers, and parking areas for trucks and trains cranes to load and unload ships etc., and robot carts to move containers around. Simplified DWR.

E N D
The Dock-Worker Robots (DWR) Domain • informal description: • harbour with several locations (docks), docked ships, storage areas for containers, and parking areas for trucks and trains • cranes to load and unload ships etc., and robot carts to move containers around Automated Planning: Introduction and Overview
Simplified DWR • Two robots: r and q • Two containers: a and b • Two locations: 1 and 2 • Robots can load and unload containers and move between locations
Dock-Worker-Robot domain • Move(r, l, l’) • Pre: at(r,l), adjacent(l,l’) • Effects: at(r,l’), ¬at(r,l) • Load(c,r,l) • Pre: at(r,l), in(c,l), unloaded(r) • Effects: loaded(r,c), ¬in(c,l), ¬unloaded(r) • Unload(c,r,l) • Pre: at(r,l), loaded(r,c) • Effects: unloded(r), in(c,l), ¬loaded(r,c)
Dock-Worker-Robot domain:Propositionalized version • Robots r and q: • r1 and r2: at(r, l1), at(r, l2) • q1 and q2: at(q, l1), at (q, l2) • ur and uq: unloaded(r), unloaded(q) • Containers a and b: • a1, a2, ar, aq: in(a, l1), in(a, l2), loaded(a, r), loaded(a,q) • b1, b2, br, bq: in(b, l1), in(b, l2), loaded(b, r), loaded(b,q) • Example initial state: {r1,q2,a1,b2,ur,uq}
Dock-Worker-Robot domain:Propositionalized version • Move actions in propositions: • Mr12: move(r,l1,l2) • similarly we hae Mr21, Mq12, Mq21 • Load actions: • Lar1: load(a,r,l1) • Similarly we have Lar2, Laq1, Laq2, Lbr1, Lbr2, Lbq1, Lbq2 • Unload actions: • Uar1: unload(a, r, l1) • Similarly we have Uar2, Uaq1, Uaq2, Ubr1, Ubr2, Ubq1, Ubq2
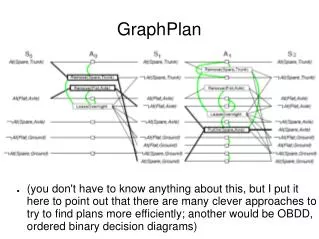
The Graphplan algorithm • Main compoents • Expand graph, where each level includes • Action Layer • Proposition Layer • Mutex propositions • Mutex actions • Back-search procedure to retrieve plan • Executed when a graph level includes all goal propositions and non of them are mutex • This still doesn’t mean there is a valid plan in this level • Basically, this is depth-first search
The expand method r1 r2 q1 q2 a1 a2 ar aq b1 b2 br bq ur uq r1 r2 q1 q2 a1 ar aq b2 br bq ur uq Mr12 Mr21 Mq12 Mq21 Lar1 Laq1 Lbr2 Lbq2 Uar1 Ubq2 Mr12 Mr21 Mq12 Mq21 Lar1 Laq1 Lbr2 Lbq2 Uar1 Uar2 Uaq1 Ubr2 Ubq1 Ubq2 r1 r2 q1 q2 a1 ar b2 bq ur uq Mr12 Mq21 Lar1 Lbq2 r1 q2 a1 b2 ur uq P0 A1 P1 A2 P2 A3 P3
The expand method • Expand graph, where each level includes • Action Layer • Proposition Layer • Mutex propositions • Mutex actions • Important: we also have noOps to propagate propositions from one layer to the next (these were not shown in previous example to save space)
Independent actions • Mr12 and Lar1: • Not independent • Mr12 deletes precondition of Lar1 • Mr12 and Mr21: • Not independent • Mr12 deletes positive effect of Mr21 • Mr12 and Mq21: • Independent • May occur in same action layer r1 r2 q1 q2 a1 ar aq b2 br bq ur uq Mr12 Mr21 Mq12 Mq21 Lar1 Laq1 Lbr2 Lbq2 Uar1 Ubq2 A2 P2
Mutex actions Function mutexAction(a1, a2, mP) if not(independent(a1,a2) return true for all p1 in precon(a1) for all p2 in precon(a2) if(p1,p2) in mP return true return false
Mutex propositions Function mutexProposition (p1, p2, mA) for all a1 in p1.producers for all a2 in p2.producers if(a1,a2) not in mA return false return true
The expand method: Pseudo-code Function expand(Gk-1) Ak {a in A | precond(a) in Pk-1and {(p1,p2)|p1,p2 in precond(a) mPk-1={} } mAk {(a1,a2)|a1,a2 in Ak, a1!=a2, and mutex(a1,a2,mPk-1)} Pk {p in P | ain Ak: p is positive effect of a} mPk {(p1,p2)|p1,p2 in pk, p1!=p2, and mutex(p1,p2,mAk)}
Backward graph search • Back-search procedure to retrieve plan • Executed when a graph level includes all goal propositions and non of them are mutex • This still doesn’t mean there is a valid plan in this level • Basically, this is depth-first search from the latest layer to layer 0 • At each iteration we choose an action that achieves one of the goal propositions and add its preconditions as goals for the next iteration • Backtrack when fails
Choose one action for each proposition, will back track if fail noOp r1 r2 q1 q2 a1 a2 ar aq b1 b2 br bq ur uq r1 r2 q1 q2 a1 ar aq b2 br bq ur uq Mr12 Mr21 Mq12 Mq21 Lar1 Laq1 Lbr2 Lbq2 Uar1 Ubq2 Mr12 Mr21 Mq12 Mq21 Lar1 Laq1 Lbr2 Lbq2 Uar1 Uar2 Uaq1 Ubr2 Ubq1 Ubq2 r1 r2 q1 q2 a1 ar b2 bq ur uq Mr12 Mq21 Lar1 Lbq2 r1 q2 a1 b2 ur uq P0 A1 P1 A2 P2 A3 P3
The noGood table • When the planning graph has k levels, the noGood table is an array of k sets of sets of goal propositions. • A set of goal propositions g appears in noGood(k) if we failed to find a plan for g in level k • Before searching for set g in Pj: • Check whether g is in noGood(j) • When search for set g in Pj failed: • Add g to noGood(j)
Backward graph search: Optional implementation Function extract (G, g, level) if level=0 return [] if g in noGoods(level) return failure plan gpSearch(G, g, {}, level) if plan!=failure reuturn plan noGood(level) noGood(level) + g return failure
Backward graph search: Optional implementation Function gpSearch(G, g, plan, level) if g = {} #no more subgoals newPlan = extract (G, all preconds of actions in plan, level-1) if newPlan = failure return failure else return newPlan union with plan p g.selectOneProp() providers {a in Alevel|p in posEffects(a) and no action in plan is mutex with a} if providers = {} return failure a providers.chooseOneAction() return gpSearch(G, g – positive effects of a, plan+a, level) Need to add backtracking here and choose another action if failing