Download

1 / 26
290 likes | 591 Views
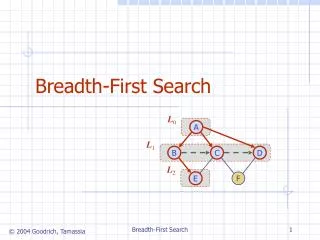
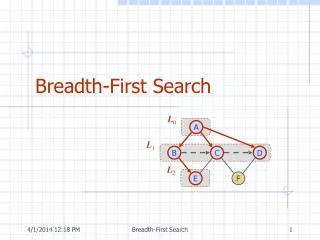
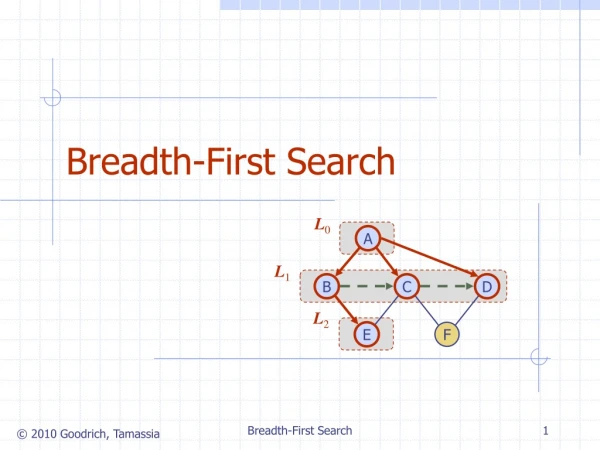
Breadth-first search (BFS) is a common graph alg. building block Hybrid approach demonstrates speedups (8x) over prior work Since last retreat Much better insight into when and why hybrid approach is faster Distributed (MPI) hybrid implementation (w/ Aydin Buluc).

E N D
Breadth-first search (BFS) is a common graph alg. building block Hybrid approach demonstrates speedups (8x) over prior work Since last retreat Much better insight into when and why hybrid approach is faster Distributed (MPI) hybrid implementation (w/ Aydin Buluc) Direction-OptimizingBreadth-First Search Scott Beamer Photo of you
GPUs are often underutilized. More CPU/GPU integration. Can offload GC to the GPU. Present a new algorithm for Mark & Sweep GC on a GPU. Need to use memory band-width, maximize parallelism. Achieve mark performance within 1.4-1.8x of CPU. GPUs as an Opportunity for Off-loading Garbage Collection Martin Maas Philip Reames + J. Morlan, K. Asanovic, A. Joseph, J. Kubiatowicz
OS sees encrypted view of app’s memory HW re-encrypts data leaving cell “Capabilities” for keys Investigation of arch for crypto. Trust neither App nor OS not to leak data SecureCell: HW for Private Cloud DRAM Contents Decrypted Object Contents Encrypted Data mmap() decryptRange CPU Private Mem Metadata Metadata Decrypted Key Untrusted Storage Eric Love Key1 Payload Data Virtual Memory Address Space AES Key Registers With John Kubiatowicz, Krste Asanović
Four cell types: Event-triggered (NEW!) Time-triggered No-multiplexed Best effort One resource multiplexer per hardware thread “communication-avoiding gang-scheduling”: use global time base to avoid coordination in the common case Juan Colmenares Gage Eads John Kubiatowicz Hilfi Alkaff Decentralized Cell Multiplexing in Tessellation
Current OS often don’t provide good QoS for storage In Tessellation: Disk accessed by multiple services and applications. Services need to access multiple devicses. Hierarchical composition of SLA’s Work in early stages QoS for Storage in Tessellation OS Nitesh Mor & Israel Jacques, Juan Colmenares, John Kubiatowicz
Previous work on Shared Memory Concurrency Scalable data race detection for UPC Compiler instrumentation for hybrid programming models Active Testing for MPI Many legacy code and frameworks for MPI Message races in MPI are a cause of non-determinism Verification and Testing of MPI Programs Chang-Seo Park
How to write unit test for concurrent programs? Must fix: Inputs+ Thread schedule DSL: Specify thread schedules for SUT Formal, concise, and convenient way Describe model checking algorithms Tool: Systematically explore all-and-only schedules of SUT specified in DSL Concurrit: A Domain Specific Language for Writing Concurrent Tests Insights/ideas about thread schedules // Example test in Concurrit DSL TA, TB, TC = WAIT_FOR_DISTINCT_THREADS() LOOP UNTIL TA, TB, TC COMPLETE { BACKTRACK HERE WITH T IN [TA, TB, TC] RUN T UNTIL READS OR WRITES } Software Under Test (SUT) + Test written in Concurrit DSL Tayfun Elmas Jacob Burnim ✓ ? George Necula Koushik Sen
SEJITS BLB Applications Machine Learning/Statistical Analysis for Big Data Results 127,000 vectors; 96,000 features 109.8 seconds Statistically robust A SEJITS Specializer for BLB Aakash Prasad David Howard
Graph algorithms applied to graphs with “attributes” on edges Integrate with Knowledge Discovery Toolbox Filtering graph to only include wanted edges = 80x slowdown SEJITS moves algorithms from being bound by interpreter to being memory bound High Performance Analysis ofFiltered Semantic Graphs Roofline Perf Bounds C++ SEJITS MemoryBandwidth PurePython Shoaib Kamil
eWallpaper:thousands of embedded Rocket processors. One antenna per processor. Application:Use the radio transceivers to image the room. For assisted living, gesture interaction, soundfield synthesis, etc. Algorithm:each radio transmits pulses. The responses are combined using SAR techniques to form an image. Challenges: Response distributed amongst 16 000 processors Restrictive mesh topology Limited local memory per processor A Distributed Algorithm for 3D Radar Imaging on eWallpaper Patrick Li, Simon Scott
Programmer tool for developing audio analysis applications Goals: Productivity, Efficiency, Portability and Scalability Three example applications: Speaker Diarization Music Recommendation (Pardora) Video event detection CPU, GPU and cluster platforms PyCASP: Python-Based Audio Content Analysis using Specialization Katya Gonina, Gerald Friedland with: Eric Battenberg, Penporn Koanantakool, Michael Driscoll, Evangelos Georganas and Kurt Keutzer
This is the first SpMV OpenCL work that covers a wide spectrum of sparse matrix formats (9 formats in total) We propose a new sparse matrix format, the Cocktail Format, that takes advantage of the strengths of many different sparse matrix formats We have developed the clSpMV autotuner to analyze the input sparse matrix at runtime, and recommend the best representation of the given sparse matrix clSpMV outperforms state-of-the-art GPU SpMV works clSpMV: A Cross-Platform OpenCL SpMV Autotuner on GPUs Bor-Yiing Su Bor-Yiing Su, Kurt Keutzer, "clSpMV: A Cross-Platform OpenCL SpMV Framework on GPUs," in International Conference on Supercomputing (ICS 2012), Italy, June 2012.
Using automatic speech recognition as the driver of our system Want to productively explore a large design space and choose the right implementation fabric Cannot afford custom programming environments for each target platform From a single Python description, our system gives us the ability to target GPU,CPU, and FPGA/ASIC We use reordering transforms to target these diverse platforms Three Fingered Jack: Automatic code generation for CPU, GPU ,and FPGA/ASIC David Sheffield
Problem Stroke treatment not quantitative Solution Patient specific risk-stratification Progress 3x increase image processing speed Improved patient analysis algorithm Approval for 160 new patient scans Modeling of Strokes in the Cerebral Vasculature Tobias Harrison-Noonan Patterns Sparse Linear Algebra Dense Linear Algebra Structured Grid Map-Reduce
More results Sodor educational processors 1stage, 2stage, 5stage, uCode, OOO Vector research processor More functionality Improved syntax Vec(n){ item } Reduce Verilog warnings Logic simplification Combinational loop detection Standard library Chisel Project Updates Huy Vo, Jonathan Bachrach
Language for describing global coherence xactions as “flows” with declarative concurrency Language for describing local pipeline logic as transactional processes Adding both to Chisel as language extensions and composing them Integrating synthesis with formal verification tools Productive Design of Extensible Cache Coherence Protocols Protocol Flows Transactors Chisel Verilog HW/Sim/Verification Henry Cook Jonathan Bachrach
undergraduate computer architecture class (CS 152) 5 labs Menagerie of processors 1-stage, 2-stage, 5-stage Micro-coded Out-of-Order (MIPS r10k style) Hwacha (vector-thread) Dual-core Rocket Chisel in the Classroom Interesting Image Or Graph from Poster Chris Celio
Performance and energy characterization Parsec, DaCapo, SPEC and Par Lab applications Hierarchical clustering LLC, prefetcher, BW, thread scalability Representive selection Tradeoff threads and cache capacity Consolidate several applications without affecting execution time and reducing overall energy consumption Energy-Aware Resource Allocation on the Sandy Bridge Processor M. MoretoH. CookS. BirdK. DaoK. AsanovicD. Patterson
pOSKI-v1.0.0 was released (4/27/12) pOSKI autotuning History Data using SQLite pOSKI(Parallel Optimized Sparse Kernel Interfaces)Update: Run-time autotuning with “History Data” Jong-Ho Byun, Richard Lin
Benchmarking CPU/GPU memories: 2,500 cycle average memory latency Occasional 1,000,000 cycle stalls 500 cycles to broadcast cache line across 10 cores 2,000 cycles to broadcast cache line across 4 sockets Naïve barrier beats OpenMP barrier 2x 1,000-cycle memory latencies Vasily Volkov
Because of rounding errors floating-point computations are non-consistent, depending on the order of computation. Repeatability can be attained, BUT at what cost ? Approach 1: reproducible reduction tree fix the order of computation Approach 2: higher precision reduce computing errors. Reproducibility of FP computations Hong Diep Nguyen
CAPS decreases both computation and communication compared to classical matrix multiplication CAPS outperforms all previous algorithms, classical and Strassen-based Our poster has lots of performance data and discusses the practicality of Strassen If allowed, CAPS would improve the LINPACK score of machines on TOP500 list Communication-Avoiding Parallel Strassen: Implementation and Performance OURS good THEIRS Grey Ballard Jim Demmel Olga Holtz Ben Lipshitz Oded Schwartz
Energy consumption of major interest in client/cloud We propose a simple model of algorithm energy consumption, and then extend comm. bounds to obtain bounds on energy Using *.5 algorithms, matrix multiplication and naïve n-body have region of perfect energy strong scaling Reviewed during earlier talk, happy to discuss details or suggestions Energy & Communication-Avoiding Algorithms Jim Demmel Andrew Gearhart Ben Lipshitz Oded Schwartz
Communication Avoiding (CA) :-minimize communication between different levels of memory to increase performance Multigrid Method :- Multilevel technique to accelerate iterative solver convergence Iterates towards convergence via a hierarchy of grid resolutions , operates in a V-cycle Communication Avoiding Optimizations for the Geometric Multigrid on GPUs Amik Singh Optimizations :- 1. More Ghost Zones 2. Wavefront Approach Communication time decreased by a factor of two!
Numerical Aspects of Communication-Avoiding Iterative Solvers • Krylov Subspace Methods (KSMs) are popular iterative solvers for large, sparse, linear systems • Problem: Communication-bound operations in each iteration limit performance! • Communication-Avoiding KSMs (CA-KSMs) • One communication step per s iterations • Reduces communication cost by a factor of s! • Problem: Round-off error in finite precision CA-KSM algorithms grows with s! • Trade off between performance and accuracy Erin Carson Can we regain accuracy without sacrificing performance benefits?
Communication avoidance (CA) and overlapping seem to be orthogonal We combine CA algorithms and overlapping techniques for: Matrix Multiplication Triangular solve Cholesky factorization Performance modeling to guide our optimizations 2.5D algorithm replicates the matrix on different layers Each layer updates its trailing matrix using a different subpanel The trailing matrix is reduced among different layers In the second phase we can overlap broadcasts with computations Communication Avoiding and Overlapping for Numerical Linear Algebra Jorge González- Domínguez Evangelos Georganas Edgar Solomonik, Yili Zheng, Katherine Yelick 2.5D Cholesky factorization with overlapping