Download
1 / 1
10 likes | 173 Views
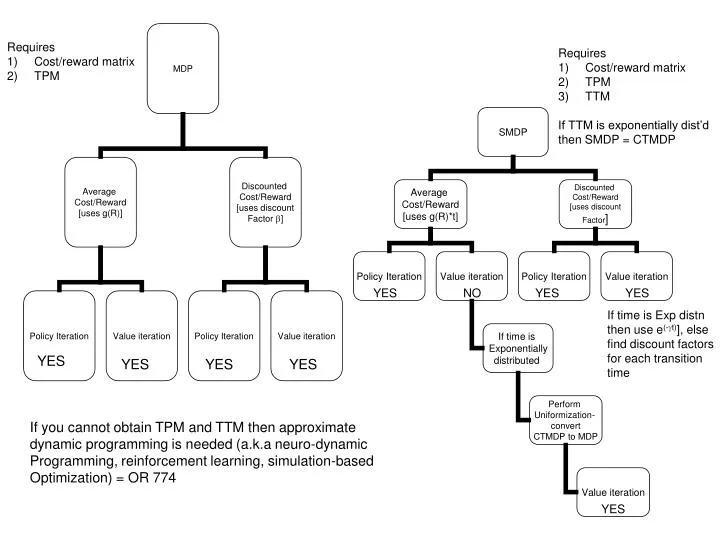
Requires Cost/reward matrix TPM. Requires Cost/reward matrix TPM TTM If TTM is exponentially dist’d then SMDP = CTMDP. If time is Exp distn then use e (- g t) ], else find discount factors for each transition time. If you cannot obtain TPM and TTM then approximate

E N D
Requires • Cost/reward matrix • TPM • Requires • Cost/reward matrix • TPM • TTM • If TTM is exponentially dist’d • then SMDP = CTMDP If time is Exp distn then use e(-gt)], else find discount factors for each transition time If you cannot obtain TPM and TTM then approximate dynamic programming is needed (a.k.a neuro-dynamic Programming, reinforcement learning, simulation-based Optimization) = OR 774 YES