Download
1 / 1
10 likes | 130 Views
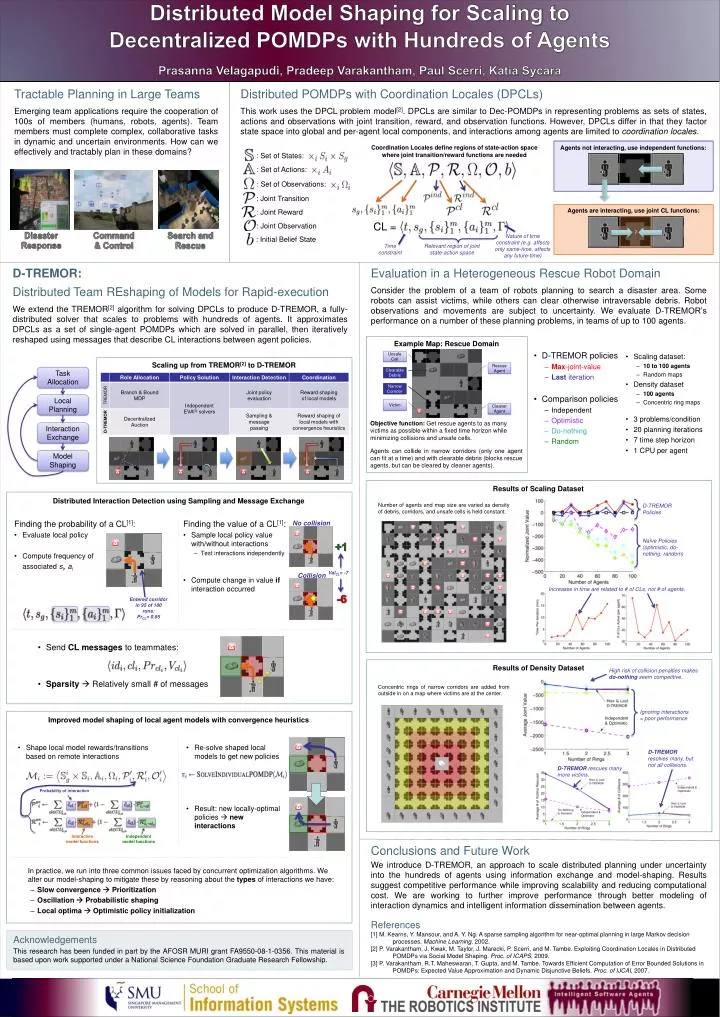
Distributed Model Shaping for Scaling to Decentralized POMDPs with Hundreds of Agents Prasanna Velagapudi, Pradeep Varakantham, Paul Scerri, Katia Sycara. High risk of collision penalties makes do-nothing seem competitive. Finding the value of a CL [1] :

E N D
Distributed Model Shaping for Scaling to Decentralized POMDPs with Hundreds of Agents Prasanna Velagapudi, Pradeep Varakantham, Paul Scerri, Katia Sycara High risk of collision penalties makes do-nothing seem competitive. Finding the value of a CL[1]: • Sample local policy value with/without interactions • Test interactions independently • Compute change in value if interaction occurred No collision D-TREMOR resolves many, but not all collisions. Task Allocation D-TREMOR rescues many more victims. +1 Local Planning Ignoring interactions = poor performance Entered corridor in 95 of 100 runs: PrCL= 0.95 Tractable Planning in Large Teams Emerging team applications require the cooperation of 100s of members (humans, robots, agents). Team members must complete complex, collaborative tasks in dynamic and uncertain environments. How can we effectively and tractably plan in these domains? Distributed POMDPs with Coordination Locales (DPCLs) This work uses the DPCL problem model[2]. DPCLs are similar to Dec-POMDPs in representing problems as sets of states, actions and observations with joint transition, reward, and observation functions. However, DPCLs differ in that they factor state space into global and per-agent local components, and interactions among agents are limited to coordination locales. ValCL= -7 Collision Probability of interaction Interaction Exchange ? CL = -6 Model Shaping Nature of time constraint (e.g. affects only same-time, affects any future-time) Interaction model functions Independent model functions Coordination Locales define regions of state-action space where joint transition/reward functions are needed Agents not interacting, use independent functions: : Set of States: : Set of Actions: : Set of Observations: Unsafe Cell : Joint Transition Rescue Agent Agents are interacting, use joint CL functions: : Joint Reward Clearable Debris : Joint Observation Narrow Corridor : Initial Belief State Time constraint Relevant region of joint state-action space Search and Rescue Disaster Response Command & Control Victim D-TREMOR: Distributed Team REshaping of Models for Rapid-execution We extend the TREMOR[2] algorithm for solving DPCLs to produce D-TREMOR, a fully-distributed solver that scales to problems with hundreds of agents. It approximates DPCLs as a set of single-agent POMDPs which are solved in parallel, then iteratively reshaped using messages that describe CL interactions between agent policies. Evaluation in a Heterogeneous Rescue Robot Domain Consider the problem of a team of robots planning to search a disaster area. Some robots can assist victims, while others can clear otherwise intraversable debris. Robot observations and movements are subject to uncertainty. We evaluate D-TREMOR’s performance on a number of these planning problems, in teams of up to 100 agents. Cleaner Agent • D-TREMOR policies • Max-joint-value • Last iteration • Comparison policies • Independent • Optimistic • Do-nothing • Random • Scaling dataset: • 10 to 100 agents • Random maps • Density dataset • 100 agents • Concentric ring maps • 3 problems/condition • 20 planning iterations • 7 time step horizon • 1 CPU per agent Example Map: Rescue Domain Number of agents and map size are varied as density of debris, corridors, and unsafe cells is held constant. Finding the probability of a CL[1]: • Evaluate local policy • Compute frequency of • associated si, ai D-TREMOR Policies Naïve Policies (optimistic, do-nothing, random) Increases in time are related to # of CLs, not # of agents. Scaling up from TREMOR[2] to D-TREMOR Results of Density Dataset Results of Scaling Dataset Improved model shaping of local agent models with convergence heuristics Distributed Interaction Detection using Sampling and Message Exchange • Send CL messages to teammates: • Sparsity Relatively small # of messages Objective function: Get rescue agents to as many victims as possible within a fixed time horizon while minimizing collisions and unsafe cells. Agents can collide in narrow corridors (only one agent can fit at a time) and with clearable debris (blocks rescue agents, but can be cleared by cleaner agents). Concentric rings of narrow corridors are added from outside in on a map where victims are at the center. Independent & Optimistic • Shape local model rewards/transitions based on remote interactions • Re-solve shaped local models to get new policies • Result: new locally-optimal policies new interactions Independent & Optimistic Independent & Optimistic Conclusions and Future Work We introduce D-TREMOR, an approach to scale distributed planning under uncertainty into the hundreds of agents using information exchange and model-shaping. Results suggest competitive performance while improving scalability and reducing computational cost. We are working to further improve performance through better modeling of interaction dynamics and intelligent information dissemination between agents. References [1] M. Kearns, Y. Mansour, and A. Y. Ng. A sparse sampling algorithm for near-optimal planning in large Markov decision processes. Machine Learning. 2002. [2] P. Varakantham, J. Kwak, M. Taylor, J. Marecki, P. Scerri, and M. Tambe. Exploiting Coordination Locales in Distributed POMDPs via Social Model Shaping. Proc. of ICAPS, 2009. [3] P. Varakantham, R.T. Maheswaran, T. Gupta, and M. Tambe. Towards Efficient Computation of Error Bounded Solutions in POMDPs: Expected Value Approximation and Dynamic Disjunctive Beliefs. Proc. of IJCAI, 2007. Acknowledgements This research has been funded in part by the AFOSR MURI grant FA9550-08-1-0356. This material is based upon work supported under a National Science Foundation Graduate Research Fellowship. • In practice, we run into three common issues faced by concurrent optimization algorithms. We alter our model-shaping to mitigate these by reasoning about the types of interactions we have: • Slow convergence Prioritization • Oscillation Probabilistic shaping • Local optima Optimistic policy initialization