Download
1 / 1
10 likes | 170 Views
MUTAGENICITY OF AROMATIC AMINES: MODELLING, PREDICTION AND CLASSIFICATION BY MOLECULAR DESCRIPTORS. Training set. Test set. Molecular descriptors. Experimental responses. DATASET: 146 amines 670 molecular descriptors 2 responses - TA98

E N D
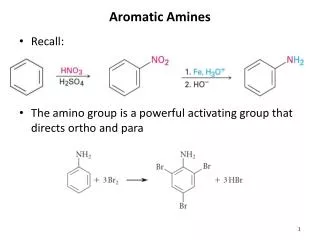
MUTAGENICITY OF AROMATIC AMINES: MODELLING, PREDICTION AND CLASSIFICATION BY MOLECULAR DESCRIPTORS Training set Test set Molecular descriptors Experimental responses DATASET: 146 amines 670 molecular descriptors 2 responses - TA98 - TA100 Internal validation External validation Q2LOO Q2LMO Zr ERcv Models Q2ext ERext Training set Testset Variable subset selection Genetic Algorithm (GA) GA-RLog PLS-DA Predictions CART SIMCA K-NN RDA CP-ANN Regression models Classification models OLS Training set = 60 compounds Test set = 42 comp. n.variables Q2LOOQ2LMOQ2extR2 5 78.5 78.0 38.7 82.8 Training set = 60 comp. Test set = 42 comp. mutagen compounds non mutagen compounds unknown compounds n.variables Q2LOOQ2LMOQ2extR2 1 62.8 63.1 67.5 65.1 STRAIN TA98 frameshift mutation M.Pavan and P.Gramatica QSAR Research Unit, Dept. of Structural and Functional Biology, University of Insubria, Varese, Italy e-mail: manuela.pavan@libero.it Web: http://fisio.varbio2.unimi.it/dbsf/home.html INTRODUCTION Aromatic and heteroaromatic amines are widespread chemicals of considerable industrial and environmental relevance as they are carcinogenic for human beings. QSAR studies have been used to develop models to estimate and to predict mutagenicity by relating it to chemical structure. In mutagenicity QSAR applications, the investigators focus on either the molecular determinants that discriminate between active and inactive chemicals, or the modulators of the relative potency of the active chemicals. The development of a model to predict mutagenicity necessitates a test system capable of providing reproducible and quantitative estimates of toxic activity; the most widely used is a bacterial test, based on the Salmonella typhimurium strains (TA98 frameshift mutation; TA100 base-substitution mutation), introduced by Ames. The data set is constituted by 146 aromatic and heteroaromatic amines collected by Benigni1; mutagenicity data are expressed as the mutation rate in log (revertants/nmol). [1] R. Benigni et all. QSAR Models for both mutagenic potency and activity: application to nitroarens and aromatic amines. Environmental and Molecular Mutagenesis 24, 208-219 (1994). • MOLECULAR DESCRIPTORS • The molecular structure has been represented by a • wide set of 670 molecular descriptors calculated • by a software developed by R.Todeschini (http://www.disat.unimib.it/chm): • sum of atomic properties descriptors (6) • counters (45) • empirical descriptors (2) • information indices (16) • topological descriptors (58) • topographic descriptors (7) • geometric descriptors (170) • quanto-chemicals descriptors (6) • autocorrelation descriptors (252) • directional WHIM descriptors (66) 2 • non-directional WHIM descriptors (33) 2 • [2]R.Todeschini and P.Gramatica, 3D-modelling and prediction by WHIM descriptors. Part 5. Theory development and chemical meaning of the WHIM descriptors, Quant.Struct.-Act.Relat., 16 (1997) 113-119. TRAINING SET SELECTION In order to have knowledge of the predictive capability of the models both internal and external validations were performed. Chemometric methods like PCA, cluster analysis and Kohonen maps were used to select the most representative training set of amines: models were developed on the selected training set and predictions were made for the molecules excluded from the model generation step (test set). • CLASSIFICATION MODELS • Some classification methods (CART, K-NN, RDA, SIMCA and CP-ANN) have been applied to this data set in order to distinguish between activity classes. The selection of the best subset of variables has been realised by Genetic Algorithm (GA-VSS) on Logistic Regression (RLog), a regression method useful when there is a restriction on the possible values of the dependent variable Y, and by PLS-DA, which confirmed the results previously obtained. The models have been validated internally (ER) and externally (ERext). • TA98 • REGRESSION MODELS • The mutagenicity potencyhas been modelledby Ordinary Least Squares (OLS) method using a selected subset starting from 670 different molecular descriptors; the selection of the best subset of variables has been realised by Genetic Algorithm (GA-VSS). The obtained models have been validated by leave-one-out (Q2LOO), leave-more-out (Q2LMO), y-scrambling (Zr) and an external test set (Q2ext) and show satisfactory predictive performances, considering the uncertainty of the biological end-points. • TA98 • TA100 • CART (classification and regression tree) CP-ANN (counterpropagationartificial neural networks) 10x10 neurones; 500 learning epochs Mor32v <-0.23 • TA100 Training set = 63 comp. Test set = 52 comp. Training set = 55 compounds Test set = 60 comp. LogTA98=-10.33+1.68nR06-4.93PJI2-0.06SPAN-2.16SPG14m-14.65E1p JGI4 <0.03 JGI4 <0.04 LogTA100=-3.39-0.72nHA+10.78ACMB5v+0.57L2v Mor32v <-0.29 Mor27v <-0.13 Mor26u <-0.29 1 NOMER% ER%ERext% 42.9 4.7 15.4 CHI0 <8.05 NOMER% ER%ERext% PHI <1.72 1 2 1 1 14.5 3.6 8.3 1 2 1 2 Mor32v,Mor27v,Mor26u steric properties JGI4 topological charges PHI molecular flexibility CHI0 molecular connectivity PW2 molecular shape Mor17u 3D-structure Training set = 43 comp. Test set = 31 comp. LogTA98=-3.807+1.184MWC06 n.variables Q2LOOQ2LMOQ2extR2 3 86.2 85.8 73.9 88.2 CONCLUSIONS STRAIN TA100 base-substitution mutation MWC06 = molecular walk count nHA = number of acceptor atoms for H-bonds ACMB5v = autocorrelation descriptors L2v = directional WHIM • molecular dimension • electronic properties • flexibility • connectivity • molecular dimension • molecular branching aromatic and heteroaromatic amines intercalary agents aromatic and heteroaromatic amines complex base-substitution mutation