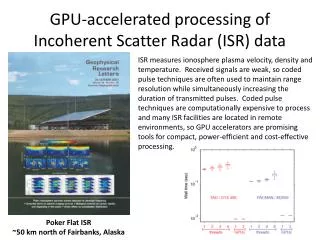
Download

1 / 23
230 likes | 438 Views
A GPU Accelerated Storage System. Abdullah Gharaibeh with: Samer Al-Kiswany Sathish Gopalakrishnan Matei Ripeanu. NetSysLab The University of British Columbia. GPUs radically change the cost landscape. $600. $1279. (Source: CUDA Guide). Harnessing GPU Power is Challenging.

E N D
A GPU Accelerated Storage System Abdullah Gharaibeh with: Samer Al-Kiswany Sathish Gopalakrishnan Matei Ripeanu NetSysLab The University of British Columbia
GPUs radically change the cost landscape $600 $1279 (Source: CUDA Guide)
Harnessing GPU Power is Challenging • more complex programming model • limited memory space • accelerator / co-processor model
Context: Distributed Storage Systems Motivating Question: Does the 10x reduction in computation costs GPUs offer change the way we design/implement distributed systems?
Computationally intensive Limit performance Distributed Systems Computationally Intensive Operations Operations Techniques Similarity detection Content addressability Security Integrity checks Redundancy Load balancing Summary cache Storage efficiency Hashing Erasure coding Encryption/decryption Membership testing (Bloom-filter) Compression
Metadata Manager Application Client Access Module b1 b2 b3 bn Distributed Storage System Architecture Application Layer FS API Files divided into stream of blocks Techniques To improve Performance/Reliability Redundancy Integrity Checks Similarity Detection Security Enabling Operations Compression Encryption/ Decryption Hashing Encoding/ Decoding Storage Nodes CPU GPU Offloading Layer
Contributions: • A GPU accelerated storage system: Design and prototype implementation that integrates similarity detection and GPU support • End-to-end system evaluation: 2x throughput improvement for a realistic checkpointing workload
b1 b2 b3 bn Challenges Files divided into stream of blocks • Integration Challenges • Minimizing the integration effort • Transparency • Separation of concerns • Extracting Major Performance Gains • Hiding memory allocation overheads • Hiding data transfer overheads • Efficient utilization of the GPU memory units • Use of multi-GPU systems Similarity Detection Hashing Offloading Layer GPU
b1 b2 b3 bn Past Work: Hashing on GPUs HashGPU1:a library that exploits GPUs to support specialized use of hashing in distributed storage systems Hashing stream of blocks One performance data point: Accelerates hashing by up to 5x speedup compared to a single core CPU HashGPU GPU However,significant speedup achieved only for large blocks (>16MB) => not suitable forefficient similarity detection 1“Exploiting Graphics Processing Units to Accelerate Distributed Storage Systems” S. Al-Kiswany, A. Gharaibeh, E. Santos-Neto, G. Yuan, M. Ripeanu,, HPDC ‘08
Profiling HashGPU At least 75% overhead Amortizing memory allocation and overlapping data transfers and computation may bring important benefits
b1 b2 b3 bn CrystalGPU CrystalGPU:a layer of abstraction that transparently enables common GPU optimizations Files divided into stream of blocks Similarity Detection One performance data point: CrystalGPU improves the speedup of HashGPU library by more than one order of magnitude HashGPU Offloading Layer CrystalGPU GPU
b1 b2 b3 bn CrystalGPU Opportunities and Enablers • Opportunity: Reusing GPU memory buffers Enabler: a high-level memory manager • Opportunity: overlap the communication and computation Enabler: double buffering and asynchronous kernel launch • Opportunity: multi-GPU systems (e.g., GeForce 9800 GX2 and GPU clusters) Enabler: a task queue manager Files divided into stream of blocks Similarity Detection HashGPU CrystalGPU Offloading Layer Memory Manager Task Queue Double Buffering GPU
Experimental Evaluation: • CrystalGPU evaluation • End-to-end system evaluation
b1 b2 b3 bn CrystalGPU Evaluation Testbed: A machine with CPU: Intel quad-core 2.66 GHz with PCI Express 2.0 x16 bus GPU: NVIDIA GeForce dual-GPU 9800GX2 Files divided into stream of blocks • Experiment space: • HashGPU/CrystalGPU vs. original HashGPU • Three optimizations • Buffer reuse • Overlap communication and computation • Exploiting the two GPUs HashGPU CrystaGPU GPU
HashGPU Performance on top CrystalGPU Base Line: CPU Single Core The gains enabled by the three optimizations can be realized!
End-to-End System Evaluation • Testbed • Four storage nodes and one metadata server • One client with 9800GX2 GPU • Three implementations • No similarity detection (without-SD) • Similarity detection • on CPU (4 cores @ 2.6GHz) (SD-CPU) • on GPU (9800 GX2) (SD-GPU) • Three workloads • Real checkpointing workload • Completely similar files: all possible gains in terms of data saving • Completely different files: only overheads, no gains • Success metrics: • System throughput • Impact on a competing application: compute or I/O intensive
System Throughput (Checkpointing Workload) 1.8x improvement The integrated system preserves the throughput gains on a realistic workload!
System Throughput (Synthetic Workload of Similar Files) Room for 2x improvement Offloading to the GPU enables close to optimal performance!
Impact on Competing (Compute Intensive) Application Writing Checkpoints back to back 2x improvement 7% reduction Frees resources (CPU) to competing applications while preserving throughput gains!
Summary • We present the design and implementation of a distributed storage system that integrates GPU power • We present CrystalGPU: a management layer that transparently enable common GPU optimizations across GPGPU applications • We empirically demonstrate that employing the GPU enable close to optimal system performance • We shed light on the impact of GPU offloading on competing applications running on the same node
Hashing X W Y Y Z Z Hashing File B Similarity Detection File A Potentially improving write throughput Only the first block is different
1 2 4 5 1 2 3 4 5 TPreprocesing + TDataHtoG + TProcessing + TPostProc + TDataGtoH Execution Path on GPU – Data Processing Application • Preprocessing (memory allocation) • Data transfer in • GPU Processing • Data transfer out • Postprocessing 3 TTotal =