Download

1 / 19
190 likes | 310 Views
Disks and RAID. Outline. Disks Disk scheduling algorithms Redundancy in storage systems, RAID File Systems Overview of file system File system design Consistency and crash recovery Sharing files Unix file system. Sector. Disk Geometry. Disks have multiple platters

E N D
Outline • Disks • Disk scheduling algorithms • Redundancy in storage systems, RAID • File Systems • Overview of file system • File system design • Consistency and crash recovery • Sharing files • Unix file system
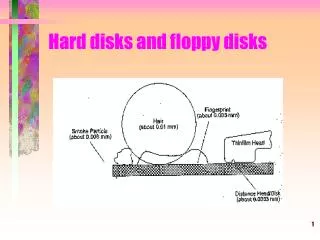
Sector Disk Geometry • Disks have multiple platters • Each platter has an head • The different heads are attached to a single arm • The different heads can access data in parallel • Each platter has multiple concentric tracks • A cylinder consists of thesame track across different platters • Each track has multiple sectors • A sector typically has preamble, data and ECC Platters Track Cylinder
Disk Access Delays • Time to access a disk sector is determined by 3 delays • Seek time • Time to move head to correct track • Rotational delay • Time for disk to rotate to correct sector • Transfer time • Time to read/write the bits of sector
Disk Performance Trends • Capacity • 100% per year (2X every year) • Transfer rate (BW) • 40% per year (2X every two years) • Typically, 50-100 MB/s • Sector transfer time is 100-200 microseconds • Seek time and Rotation time • 8% per year (1/2 every 10 years) • Seek and rotation time are typically 4-8 ms today • Disk scheduling aims to minimize these times, especially seek time
Disk Performance • Fastest: No head movement, no rotational latency • => Sequential access • Faster: no head movement, rotational latency • => Access to blocks on the same cylinder is faster • Slow: head movement, rotational latency • => Access to blocks on different cylinders • => The further the cylinders the worse it is
Addressing Disks • Older disks required OS to specify all parameters for transferring data • E.g., cylinder #, track #, sector #, transfer size • Modern disks are more complicated • Not all sectors are the same size, sectors are remapped, etc. • Current disks provide a higher-level interface • Disk exports its data as a logical array of blocks • Disk maps logical blocks to its surface • OS code is simpler but disk parameters are hidden
Layers of Abstraction • Program <Filename, Offset> • File system <Partition, Block#> • Device driver <Disk#, Sector#> • Disk Controller <Cylinder, Track, Sector>
Disk Errors • Lots of errors possible • E.g., latent sector errors, mis-directed writes, etc. • Transient vs. hard errors • Some errors can be masked by ECC • Bad sectors • Allocate spare sectors per track • Block can be mapped to spare in various ways • In the factory, by the device controller, by OS • OS can hide bad sectors by allocating them to a special hidden file • Physical backup programs have to careful
Disk Scheduling Algorithms • Aim is to improve disk performance • Two methods • Reduce seeks and rotation • Read several blocks of data • Algorithms • First-come, first served (FCFS) • Simple, fair, slow • Shortest seek time first (SSF) • SCAN (Elevator)
Shortest Seek First (SSF) • Shortest seek first minimizes arm motion • Unlike FCFS, starvation is possible Initial position Pending requests
SCAN (Elevator) • Use a bit to track outward or inward arm direction • Service the next pending request in same direction • When there are no more requests in the current direction, reverse direction • Increases seek compared to SSF but ensures no starvation • A variant is called C-SCAN • SCAN, but request go in one direction (typewriter) • What are its benefits/drawbacks vs. SCAN?
Modern Disk Scheduling • Disks know their layout better than the OS • May ignore or undo disk scheduling in OS!
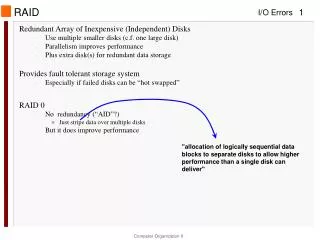
Redundancy in Storage Systems • Idea: Use many disks in parallel • Increases storage bandwidth, improves reliability • Redundant Array of Inexpensive Disks (RAID) • A storage system, not a file system • Files are striped across disks • Stripes on different disks can be read/written in parallel • Bandwidth increases with more disks • Better throughput for large requests • Choosing stripe size is important • Normally between 1KB to 1MB • Increase stripe size, as average file size increases
RAID Levels 0, 1 • RAID level 0: disk striping • Distributes data across several disks for speed • No redundancy • RAID level 1: mirroring • Backup solution • Write both, read either • 50% utilization
RAID Levels 4, 5 • RAID level 4: block striping, dedicated parity disk • Calculate XOR value of stripes across disks • Store XOR stripe value on separate disk • Uses one extra disk for parity • Utilization: (N-1)/N, N is the number of disks • RAID level 5: striping with distributed parity • Similar to 4 but parity information is distributed across all disks • Avoids bottleneck for parity disk • If a single disk dies, it has to be replaced • Information for that disk is recreated from the other disks • RAID level 6: • Can recovery from the loss of two disks • Allows (single) failure during disk recovery